题目
() 设X1,X2,···,Xn是来自概率密度为-|||-(x;theta )= ) theta (x)^theta -1, 0lt xlt 1 0, 的最大似然估计值.

题目解答
答案
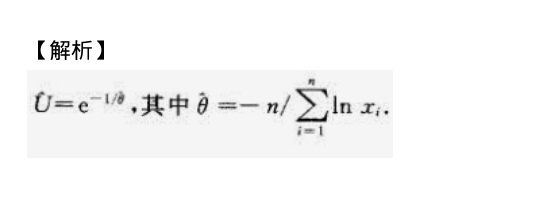
解析
考查要点:本题主要考查最大似然估计的应用,涉及参数估计的求解步骤,以及如何将估计结果代入目标函数。
解题核心思路:
- 写出似然函数:根据给定的概率密度函数,构造样本的联合概率密度(似然函数)。
- 取对数并求导:通过对数似然函数求导,找到导数为零的点,确定参数θ的最大似然估计值。
- 代入目标函数:将估计出的θ代入目标函数$U = e^{-1/\theta}$,得到U的最大似然估计值。
破题关键点:
- 正确处理对数似然函数的导数,注意样本数据中$x_i \in (0,1)$导致$\ln x_i$为负数,需确保θ的估计值为正数。
- 代数运算的符号处理,避免因符号错误导致最终结果偏差。
1. 构造似然函数
样本$X_1, X_2, \dots, X_n$的似然函数为:
$L(\theta) = \prod_{i=1}^{n} \theta x_i^{\theta - 1} = \theta^n \left( \prod_{i=1}^{n} x_i \right)^{\theta - 1}$
2. 对数似然函数
取自然对数得:
$\ln L(\theta) = n \ln \theta + (\theta - 1) \sum_{i=1}^{n} \ln x_i$
3. 求导并解方程
对θ求导并令导数为零:
$\frac{d}{d\theta} \ln L(\theta) = \frac{n}{\theta} + \sum_{i=1}^{n} \ln x_i = 0$
解得:
$\hat{\theta} = -\frac{n}{\sum_{i=1}^{n} \ln x_i}$
4. 代入目标函数
将$\hat{\theta}$代入$U = e^{-1/\theta}$:
$\hat{U} = e^{-1/\hat{\theta}} = e^{-1 \big/ \left( -\frac{n}{\sum_{i=1}^{n} \ln x_i} \right)} = e^{\frac{\sum_{i=1}^{n} \ln x_i}{n}}$