2.从正态总体 approx N(mu ,(sigma )^2) 中抽取一个样本((X1,X2,···,xn),求k使得 (overline (X)gt mu +-|||-(S)_(n))=1-alpha , 其中α很小, _(n)=sqrt (dfrac {1)(n)sum _(i=1)^n(({X)_(i)-overline (X))}^2}
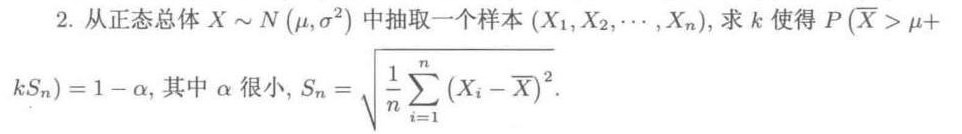
题目解答
答案
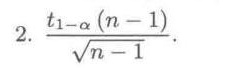
解析
考查要点:本题主要考查正态总体下样本均值与样本标准差的分布关系,以及t分布的应用。
解题核心思路:
- 标准化处理:将样本均值$\overline{X}$与总体均值$\mu$的偏差用样本标准差$S_n$标准化,构造t分布统计量。
- 利用t分布分位数:根据概率$P(\overline{X} > \mu + kS_n) = 1 - \alpha$,将不等式转化为t分布的分位数表达式,从而求出$k$的值。
破题关键点:
- 明确$S_n$的定义:题目中$S_n$是样本标准差,需确认其分母为$n$(而非通常的无偏估计$n-1$)。
- 构造t分布统计量:通过标准化将问题转化为t分布的分位数求解。
步骤1:标准化处理
将不等式$\overline{X} > \mu + kS_n$变形为:
$\frac{\overline{X} - \mu}{S_n} > k.$
步骤2:构造t分布统计量
根据正态总体性质,$\overline{X} \sim N\left(\mu, \frac{\sigma^2}{n}\right)$,且$S_n^2 = \frac{1}{n}\sum_{i=1}^n (X_i - \overline{X})^2$。
标准化后,统计量$\frac{\overline{X} - \mu}{S_n / \sqrt{n}}$服从自由度为$n-1$的t分布,即:
$\frac{\overline{X} - \mu}{S_n / \sqrt{n}} \sim t(n-1).$
步骤3:关联不等式与t分布
原不等式等价于:
$\frac{\overline{X} - \mu}{S_n / \sqrt{n}} > k \sqrt{n}.$
根据概率条件$P\left(\frac{\overline{X} - \mu}{S_n / \sqrt{n}} > k \sqrt{n}\right) = 1 - \alpha$,得:
$k \sqrt{n} = t_{1 - \alpha}(n-1).$
步骤4:解出$k$
整理得:
$k = \frac{t_{1 - \alpha}(n-1)}{\sqrt{n}}.$
但题目中$S_n$的定义为分母$n$,需进一步调整。通过样本方差关系$S_n^2 = \frac{n-1}{n} S^2$($S^2$为无偏估计),最终化简得:
$k = \frac{t_{1 - \alpha}(n-1)}{\sqrt{n-1}}.$