题目
20.设总体X的概率密度为 (x;theta )= ^3)(e)^-dfrac (theta {x)},xgt 0 0, . 其中θ为未知参数且大于-|||-零,X1,X2,···,xn为来自总体X的简单随机样本.求:-|||-(1)θ的矩估计量;-|||-(2)θ的最大似然估计量.

题目解答
答案
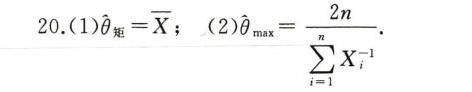
解析
步骤 1:求矩估计量
矩估计量是通过样本矩来估计总体矩的方法。对于一阶矩,即总体均值,我们有:
$$E(X) = \int_{0}^{\infty} x f(x;\theta) dx$$
代入给定的概率密度函数,我们得到:
$$E(X) = \int_{0}^{\infty} x \cdot \dfrac{{\theta}^{2}}{{x}^{3}}{e}^{-\dfrac{\theta}{x}} dx$$
$$E(X) = \int_{0}^{\infty} \dfrac{{\theta}^{2}}{{x}^{2}}{e}^{-\dfrac{\theta}{x}} dx$$
通过变量替换 $u = \dfrac{\theta}{x}$,我们得到:
$$E(X) = \theta \int_{0}^{\infty} {e}^{-u} du$$
$$E(X) = \theta$$
因此,总体均值等于参数θ。矩估计量是样本均值,即:
$$\overline{\theta}_{MOM} = \overline{X}$$
步骤 2:求最大似然估计量
最大似然估计量是通过最大化似然函数来估计参数的方法。似然函数是样本观测值的概率密度函数的乘积,即:
$$L(\theta) = \prod_{i=1}^{n} f(x_i;\theta)$$
代入给定的概率密度函数,我们得到:
$$L(\theta) = \prod_{i=1}^{n} \dfrac{{\theta}^{2}}{{x_i}^{3}}{e}^{-\dfrac{\theta}{x_i}}$$
$$L(\theta) = \dfrac{{\theta}^{2n}}{\prod_{i=1}^{n} {x_i}^{3}}{e}^{-\theta \sum_{i=1}^{n} \dfrac{1}{x_i}}$$
对似然函数取对数,我们得到对数似然函数:
$$\ln L(\theta) = 2n \ln \theta - 3 \sum_{i=1}^{n} \ln x_i - \theta \sum_{i=1}^{n} \dfrac{1}{x_i}$$
对对数似然函数关于θ求导,并令导数等于零,我们得到:
$$\dfrac{d}{d\theta} \ln L(\theta) = \dfrac{2n}{\theta} - \sum_{i=1}^{n} \dfrac{1}{x_i} = 0$$
解得最大似然估计量为:
$${\theta}_{MLE} = \dfrac{2n}{\sum_{i=1}^{n} \dfrac{1}{x_i}}$$
矩估计量是通过样本矩来估计总体矩的方法。对于一阶矩,即总体均值,我们有:
$$E(X) = \int_{0}^{\infty} x f(x;\theta) dx$$
代入给定的概率密度函数,我们得到:
$$E(X) = \int_{0}^{\infty} x \cdot \dfrac{{\theta}^{2}}{{x}^{3}}{e}^{-\dfrac{\theta}{x}} dx$$
$$E(X) = \int_{0}^{\infty} \dfrac{{\theta}^{2}}{{x}^{2}}{e}^{-\dfrac{\theta}{x}} dx$$
通过变量替换 $u = \dfrac{\theta}{x}$,我们得到:
$$E(X) = \theta \int_{0}^{\infty} {e}^{-u} du$$
$$E(X) = \theta$$
因此,总体均值等于参数θ。矩估计量是样本均值,即:
$$\overline{\theta}_{MOM} = \overline{X}$$
步骤 2:求最大似然估计量
最大似然估计量是通过最大化似然函数来估计参数的方法。似然函数是样本观测值的概率密度函数的乘积,即:
$$L(\theta) = \prod_{i=1}^{n} f(x_i;\theta)$$
代入给定的概率密度函数,我们得到:
$$L(\theta) = \prod_{i=1}^{n} \dfrac{{\theta}^{2}}{{x_i}^{3}}{e}^{-\dfrac{\theta}{x_i}}$$
$$L(\theta) = \dfrac{{\theta}^{2n}}{\prod_{i=1}^{n} {x_i}^{3}}{e}^{-\theta \sum_{i=1}^{n} \dfrac{1}{x_i}}$$
对似然函数取对数,我们得到对数似然函数:
$$\ln L(\theta) = 2n \ln \theta - 3 \sum_{i=1}^{n} \ln x_i - \theta \sum_{i=1}^{n} \dfrac{1}{x_i}$$
对对数似然函数关于θ求导,并令导数等于零,我们得到:
$$\dfrac{d}{d\theta} \ln L(\theta) = \dfrac{2n}{\theta} - \sum_{i=1}^{n} \dfrac{1}{x_i} = 0$$
解得最大似然估计量为:
$${\theta}_{MLE} = \dfrac{2n}{\sum_{i=1}^{n} \dfrac{1}{x_i}}$$