参数的点估计的类型、方法、评价方法。(1)点估计(2)区间估计点估计法:a,矩估计法。基本思想:由于样品来源于总体,样品矩在一定程度上反映了总体矩,而且由于大数定律可知, 样品矩依概率收敛于总体矩。因此,只要总体x的k阶原点矩存在,就可以用样本矩作为相应总体矩的估计量,用样本矩的函数作为总体矩的函数的估计量。b,极大似然估计法。基本思想:设总体分布的函数形式已知,但有未知参数二门可以取很多值,有二的一切可能取值中选一个使样品观测值出现概率最大的值作为二的估计 量,记作二,并称为二的极大似然估计值,这叫极大似然估计法。3假设检验的思想、推理依据及参数假设检验的步骤。先假设总体具有某种特征,然后再通过对样品的加工,即构造统计量推断出假设的结论是否 合理。假设检验是带有概率性质的反证法。推理依据:第一,假设检验采用的逻辑方法是反证法;第二,合理与否,依据是小概率事件 实际不可能发生的原理。参数假设检验的步骤:(1)提出原假设和备择假设;(2)选择适当的统计量,并确定其分布 形式。(3)选择显著性水平:•,确定其临界值;(4)作出结论。4•方差分析的目的及思想(结合单因素)。目的:通过分析,判定某一因子是否显著,当因子显著时,我们可以绘出每一水平下指标均 值的估计,以便找出最好的水平。方差分析是对多个总体均值是否相等这一假设进行检验。思想:检验叫=」2=I是通过方差的比较来确定的,即要考虑均值之间的差异,差异产生来自两个方面, 一是由因数中不同水平造成的, 称为系统性差异; 二是由随机性产生 的差异。两方面的差异用两个方差来计量,一个称水平之间的方差(既包括系统因数, 又包括随机性因数);一个称为水平内部方差 (仅包括随机因数)。如果不同的水平对结果没有影 响,两个方差的比值会接近于 1;反之,则两个方差的比值会显著地大于1很多,认为H0不真,可作出判断,说明不同水平之间存在着显著性差异。如果方差分析只对一个因数进行单因数方差分析,单因数方差分析所讨论的是在一个总体标准差皆相等的条件下,解决一个总体平均数是否相等的问题。5•简述正交实验设计中的数据分析方法方法:极差分析法和方差分析法。极差分析法步骤:(1)定指标,确定因数,选水平(2)选用适当的正交表,表头设计,确 定实验方案;(3)严格按要求做实验,并记录实验结果;(4)计算i个因数的每个水平的实验结果和极差(同一因数不同水平的差异),其反映了该因数对实验结果的影响大小;(5)按级差大小排列因数主次;(6)选取较优生产条件(7)进行实验性试验,做进一步分析。 方差分析法:思想:将数据的总偏差平方和分解为因数的偏差平方和与随机误差的平方和之 和,用各因数的偏差平方和与误差平方和相比,做一下检验,即可判断引述的作用是否显著,这里用方差分析的思想来处理有正交表安排的多因数实验的实验结果,分析各因数是否存在显著影响。6主成分分析的基本思想。主成分分析是从总体的多个指标中构造出很少几个互不相关的综合指标,且使这几个综合指标尽可能充分的反映原来各个指标的信息。即主成分分析是一种把原来多个指标化为少数几个互不相关的综合指标的一种统计方法。它的目的是力求数据信息丢失最少的原则下,对高维变量空间进行降维处理。即用原来变量的少数几个线性组合(称为综合变量)来代替原变量,以达到简化数据,揭示变量之间关系 和进行统计解释的目的。7、典型相关分析答:考虑X的综合指标(X的线性函数)与y的综合指标之间的相关性程度来刻画X与Y的相关性,即把两组变量的相关变为两个新变量(线性函数)之间的相关来进行讨论,同时又尽量保留原来变量的信息,或者说,找X的线性函数和Y的线性函数,使这两个函数具有最大的相关性。称这种相关为典型相关,称形式的两个线性函数即两个新的变量为典型变 量,继而还可以分别找出 X与Y的第二对线性函数,使其与第一对典型变量不相关,而这 两个线性函数之间又具有最大的相关性,如此继续进行下去,直到两组变量X与Y之间的相关性被提取完毕为止,这就是典型相关分析的基本思想。总之,典型相关分析是揭示两个因素“集团”之间内部联系的一种数学方法。8、贝叶斯判别法答:贝叶斯判别是根据先验信息使得误判所造成的平均损失达到最小的判别法。假定对研究对象已有一定的认识,常用先验概率分布来描述这种认识,然后我们取得一个样本,用样本来修正已有的认识(先验概率分布)得到后验概率分布,各种统计推断通过后验概率分布来 进行,将贝叶斯思想用于判别分析就得到贝叶斯分布。9、聚类,分类答:聚类分析是研究对样品或指标进行分类的一种多元统计方法, 分类是将一个观测对象指 定到某一类(组) 。分类问题可分为两种:一是将一些未知类别的个体正确地归属于另外一 些已知类中的某一类, 另一种是事先不知道研究的问题应该分为几类, 而是根据统计分析建 立一种分类方法, 并按接近程度对观测对象给出合理的分类, 这一类问题即是聚类分析所要 解决的问题。则Y的分布为 -NA(H)_(1), Av A^TA=则Y的分布为 -NA(H)_(1), Av A^TA=7•设X服从二维正态N2(»匚)分布,其中J-聚类分析根据分类对象的不同分为R型和Q型两大类。R型是对变量 (指标) 进行分类,Q型是对样品进行分类;R型聚类分析的目的是( 1)可以了解变量间及变量组合间的亲疏关 系。(2)对变量进行分类。 (3)根据分类结果及它们之间的关系,在每一类中选择有代表性 的变量作为重要变量, 利用少数几个重要变量进一步作分析计算;Q型聚类分析的目的主要是对样品进行分类。10、线性回归分析的主要内容及应用中应注意的问题 答:线性回归分析根据预报变量的多少可分为一元线性回归、 多元线性回归。 主要研究内容 包括如何确定响应变量和预报变量之间的回归模型, 如何根据样本观测值进行参数估计并检 验回归方程和回归系数的显著性; 从众多的预报变量中, 判断哪些变量对响应变量的影响时 显著的, 哪些变量的影响是不显著的; 根据预报变量的已知值或给定值来估计和预测响应变 量的平均值并给出预测精度。怎样选择自变量, 即能使回归方程有高的精确性, 又不含非显著因子, 这是线性回归分析在 应用中应注意的问题。(1)要从全部因子的所有可能的组合组成的回归方程中,挑选平均残差平方和小,负相关 系数大,自变量个数较少的方程,作为方程。(2)采用逐步回归法。11、系统聚类法的算法思想及步骤 答:算法思想:(1)首先将每个样品各视为一类,定义类与类之间的距离,将距离最短的两 类合并为一个新类( 2)再计算新类与其他类之间的距离,将距离最短的两类再合并为一个 新类。 如此进行下去, 直到所有样品全部合并为一个大类为止, 最后再根据事先给定的分类 临界值,确定分类,一般步骤为: (1)计算样品两两之间的距离; ( 2)将每个样品各作为一 类;( 3)将距离最近的两类合并为一个新类; ( 4)若类的个数等于 1,则转向步骤 5,否则 转向步骤 3;( 5)记录下全部合并过程,画类聚图; (6)根据给定的分类临界值,确定最终 分类结果。12、如何看待多元统计分析方法在实际数据处理中的作用和地位 答:多元统计分析方法在实际数据处理中有着重要的作用。 它不仅可以通过观察值对总体进 行参数估计和假设检验, 还可以通过相应的方法达到数据化简, 分类和研究变量间依赖关系 的目的,并能预测变量间关系,提出检验假设等目的。目前在医学、教育学、社会学、地质 学、考古学、环境保护等各个领域有极其广泛的作用。&某试验的极差分析结果如下表(设指标越大越好)表1 因素水平表表2极差分析数据表则(1)较好工艺条件应为a2b2c1d2e1(2) 方差分析中总离差平方和的自由度为______。(3) 上表中的第三列表示A B交互作用一。9.为了估计山上积雪溶化后对河流下游灌溉的影响,在山上建立观测站, 测得连续10年的观测数据如下表(见表 3)。表3最大积雪深度与灌溉面积的10年观测数据则y关于x的线性回归模型为0=2.356 *1.813x~N 0,1.611110设总体X1),Xi,X2,...,Xn为样本,则0的矩估计量为 —X,极大似2然估计量为1______n}。12设总体 X在区间[二―1]上服从均匀分布,则V的矩估计X--;DC?)二— 2 —______。2 213设…,Xn是来自正态总体N(.L,二)的样本,丄,二均未知,「-0.05.■-s-s1贝U4的置信度为1-«的置信区间为 —]x—〒tq(n—1),x+〒t^(n—1)—;若-Jn2Jn2一2 2 2 2 2•i为已知常数,则检验假设H0:二-c0比:二:::二0,(二0已知),的拒绝域为 —X2乞12_..(n-1)_。14设X服从p维正态Np(m分布,X「X2,…,Xn是来自X的样本,则3的最小方差Np0,2/n_分布。15设(X1,…,X)为来自正态总体X ~NpCM)的一个样本,、已知。对给定的检验水平为a,检验假设H0:4=卩0㈠比:卩式卩0,(卩0已知)的统计量为_,竝Jn拒绝域为k >ua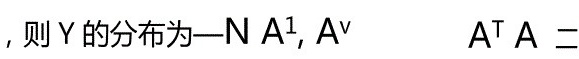
 7•设X服从二维正态N2(»匚)分布,其中J-
7•设X服从二维正态N2(»匚)分布,其中J-
聚类分析根据分类对象的不同分为R型和Q型两大类。R型是对变量 (指标) 进行分类,Q型是对样品进行分类;R型聚类分析的目的是( 1)可以了解变量间及变量组合间的亲疏关 系。(2)对变量进行分类。 (3)根据分类结果及它们之间的关系,在每一类中选择有代表性 的变量作为重要变量, 利用少数几个重要变量进一步作分析计算;Q型聚类分析的目的主要
是对样品进行分类。
10、线性回归分析的主要内容及应用中应注意的问题 答:线性回归分析根据预报变量的多少可分为一元线性回归、 多元线性回归。 主要研究内容 包括如何确定响应变量和预报变量之间的回归模型, 如何根据样本观测值进行参数估计并检 验回归方程和回归系数的显著性; 从众多的预报变量中, 判断哪些变量对响应变量的影响时 显著的, 哪些变量的影响是不显著的; 根据预报变量的已知值或给定值来估计和预测响应变 量的平均值并给出预测精度。
怎样选择自变量, 即能使回归方程有高的精确性, 又不含非显著因子, 这是线性回归分析在 应用中应注意的问题。
(1)要从全部因子的所有可能的组合组成的回归方程中,挑选平均残差平方和小,负相关 系数大,自变量个数较少的方程,作为方程。
(2)采用逐步回归法。
11、系统聚类法的算法思想及步骤 答:算法思想:(1)首先将每个样品各视为一类,定义类与类之间的距离,将距离最短的两 类合并为一个新类( 2)再计算新类与其他类之间的距离,将距离最短的两类再合并为一个 新类。 如此进行下去, 直到所有样品全部合并为一个大类为止, 最后再根据事先给定的分类 临界值,确定分类,一般步骤为: (1)计算样品两两之间的距离; ( 2)将每个样品各作为一 类;( 3)将距离最近的两类合并为一个新类; ( 4)若类的个数等于 1,则转向步骤 5,否则 转向步骤 3;( 5)记录下全部合并过程,画类聚图; (6)根据给定的分类临界值,确定最终 分类结果。
12、如何看待多元统计分析方法在实际数据处理中的作用和地位 答:多元统计分析方法在实际数据处理中有着重要的作用。 它不仅可以通过观察值对总体进 行参数估计和假设检验, 还可以通过相应的方法达到数据化简, 分类和研究变量间依赖关系 的目的,并能预测变量间关系,提出检验假设等目的。目前在医学、教育学、社会学、地质 学、考古学、环境保护等各个领域有极其广泛的作用。
&某试验的极差分析结果如下表(设指标越大越好)
表1 因素水平表
表2极差分析数据表
则(1)较好工艺条件应为a2b2c1d2e1
(2) 方差分析中总离差平方和的自由度为______。
(3) 上表中的第三列表示A B交互作用一。
9.为了估计山上积雪溶化后对河流下游灌溉的影响,在山上建立观测站, 测得连续10年的
观测数据如下表(见表 3)。
表3最大积雪深度与灌溉面积的10年观测数据
则y关于x的线性回归模型为0=2.356 *1.813x~N 0,1.611
1
10设总体X1),Xi,X2,...,Xn为样本,则0的矩估计量为 —X,极大似
2
然估计量为1______n}。
12设总体 X在区间[二―1]上服从均匀分布,则V的矩估计X--;DC?)二
— 2 —
______。
2 2
13设…,Xn是来自正态总体N(.L,二)的样本,丄,二均未知,「-0.05.
■-s-s1
贝U4的置信度为1-«的置信区间为 —]x—〒tq(n—1),x+〒t^(n—1)—;若
-Jn2Jn2一
2 2 2 2 2
•i为已知常数,则检验假设H0:二-c0比:二:::二0,(二0已知),的拒绝域为 —
X2乞12_..(n-1)_。
14设X服从p维正态Np(m分布,X「X2,…,Xn是来自X的样本,则3的最小方差
Np0,2/n_分布。
15设(X1,…,X)为来自正态总体X ~NpCM)的一个样本,、已知。对给定的检
验水平为a,检验假设H0:4=卩0㈠比:卩式卩0,(卩0已知)的统计量为$_,竝Jn
拒绝域为k >ua!
[列
二计算及证明题
2
1设X1,X2是来自总体X~N(u,;「)的一个样本。
(1)证明X1X2,X1-x2相互独立
2
(2)假设u= 0,求(X1 X2)2的分布
(X1-X2)2
生N 0,1
CT
』.x^+x2- 2 I』.
N 0,2,―2N 0,2
cr
即:x x2L N2七2匚2
L N 0,2 ,为-X2 _ N 0,2二2
2「0,N X2LnOf,x^ -X2_N 0,-
题目解答
答案
7.X2.…,X 1/12n