题目
2.设X1,···X2,···,Nn为总体的一个样本,x1,x2,···xn为一相应的样本值.求下列各总体-|||-的概率密度或分布律中的未知参数的矩估计量和矩估计值.-|||-(1) f(x)= { { ^-(theta +1), xgt c 0, 其他 ,其中 lt plt 1 ,p为未知参数.

题目解答
答案
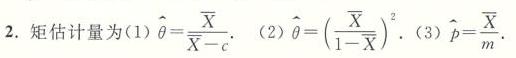
解析
步骤 1:求解总体的期望
对于给定的概率密度函数,我们首先需要求出总体的期望。对于第一种情况,总体的期望为:
$$
E(X) = \int_{c}^{\infty} x \cdot \theta c^{\theta} x^{-(\theta + 1)} dx = \theta c^{\theta} \int_{c}^{\infty} x^{-\theta} dx = \theta c^{\theta} \left[ \frac{x^{-\theta + 1}}{-\theta + 1} \right]_{c}^{\infty} = \frac{\theta c}{\theta - 1}
$$
步骤 2:求解矩估计量
根据矩估计量的定义,我们用样本均值 $\overline{X}$ 来估计总体的期望 $E(X)$,即:
$$
\overline{X} = \frac{\theta c}{\theta - 1}
$$
解这个方程,得到 $\theta$ 的矩估计量:
$$
\hat{\theta} = \frac{\overline{X}}{\overline{X} - c}
$$
步骤 3:求解矩估计值
将样本值 $x_1, x_2, \cdots, x_n$ 代入矩估计量公式,得到 $\theta$ 的矩估计值:
$$
\hat{\theta} = \frac{\overline{x}}{\overline{x} - c}
$$
步骤 4:求解第二种情况的矩估计量和矩估计值
对于第二种情况,总体的期望为:
$$
E(X) = \int_{0}^{1} x \cdot \sqrt{\theta} x^{\sqrt{\theta} - 1} dx = \sqrt{\theta} \int_{0}^{1} x^{\sqrt{\theta}} dx = \sqrt{\theta} \left[ \frac{x^{\sqrt{\theta} + 1}}{\sqrt{\theta} + 1} \right]_{0}^{1} = \frac{\sqrt{\theta}}{\sqrt{\theta} + 1}
$$
用样本均值 $\overline{X}$ 来估计总体的期望 $E(X)$,即:
$$
\overline{X} = \frac{\sqrt{\theta}}{\sqrt{\theta} + 1}
$$
解这个方程,得到 $\theta$ 的矩估计量:
$$
\hat{\theta} = \left( \frac{\overline{X}}{1 - \overline{X}} \right)^2
$$
将样本值 $x_1, x_2, \cdots, x_n$ 代入矩估计量公式,得到 $\theta$ 的矩估计值:
$$
\hat{\theta} = \left( \frac{\overline{x}}{1 - \overline{x}} \right)^2
$$
步骤 5:求解第三种情况的矩估计量和矩估计值
对于第三种情况,总体的期望为:
$$
E(X) = \sum_{x=0}^{m} x \cdot \binom{m}{x} p^x (1-p)^{m-x} = mp
$$
用样本均值 $\overline{X}$ 来估计总体的期望 $E(X)$,即:
$$
\overline{X} = mp
$$
解这个方程,得到 $p$ 的矩估计量:
$$
\hat{p} = \frac{\overline{X}}{m}
$$
将样本值 $x_1, x_2, \cdots, x_n$ 代入矩估计量公式,得到 $p$ 的矩估计值:
$$
\hat{p} = \frac{\overline{x}}{m}
$$
对于给定的概率密度函数,我们首先需要求出总体的期望。对于第一种情况,总体的期望为:
$$
E(X) = \int_{c}^{\infty} x \cdot \theta c^{\theta} x^{-(\theta + 1)} dx = \theta c^{\theta} \int_{c}^{\infty} x^{-\theta} dx = \theta c^{\theta} \left[ \frac{x^{-\theta + 1}}{-\theta + 1} \right]_{c}^{\infty} = \frac{\theta c}{\theta - 1}
$$
步骤 2:求解矩估计量
根据矩估计量的定义,我们用样本均值 $\overline{X}$ 来估计总体的期望 $E(X)$,即:
$$
\overline{X} = \frac{\theta c}{\theta - 1}
$$
解这个方程,得到 $\theta$ 的矩估计量:
$$
\hat{\theta} = \frac{\overline{X}}{\overline{X} - c}
$$
步骤 3:求解矩估计值
将样本值 $x_1, x_2, \cdots, x_n$ 代入矩估计量公式,得到 $\theta$ 的矩估计值:
$$
\hat{\theta} = \frac{\overline{x}}{\overline{x} - c}
$$
步骤 4:求解第二种情况的矩估计量和矩估计值
对于第二种情况,总体的期望为:
$$
E(X) = \int_{0}^{1} x \cdot \sqrt{\theta} x^{\sqrt{\theta} - 1} dx = \sqrt{\theta} \int_{0}^{1} x^{\sqrt{\theta}} dx = \sqrt{\theta} \left[ \frac{x^{\sqrt{\theta} + 1}}{\sqrt{\theta} + 1} \right]_{0}^{1} = \frac{\sqrt{\theta}}{\sqrt{\theta} + 1}
$$
用样本均值 $\overline{X}$ 来估计总体的期望 $E(X)$,即:
$$
\overline{X} = \frac{\sqrt{\theta}}{\sqrt{\theta} + 1}
$$
解这个方程,得到 $\theta$ 的矩估计量:
$$
\hat{\theta} = \left( \frac{\overline{X}}{1 - \overline{X}} \right)^2
$$
将样本值 $x_1, x_2, \cdots, x_n$ 代入矩估计量公式,得到 $\theta$ 的矩估计值:
$$
\hat{\theta} = \left( \frac{\overline{x}}{1 - \overline{x}} \right)^2
$$
步骤 5:求解第三种情况的矩估计量和矩估计值
对于第三种情况,总体的期望为:
$$
E(X) = \sum_{x=0}^{m} x \cdot \binom{m}{x} p^x (1-p)^{m-x} = mp
$$
用样本均值 $\overline{X}$ 来估计总体的期望 $E(X)$,即:
$$
\overline{X} = mp
$$
解这个方程,得到 $p$ 的矩估计量:
$$
\hat{p} = \frac{\overline{X}}{m}
$$
将样本值 $x_1, x_2, \cdots, x_n$ 代入矩估计量公式,得到 $p$ 的矩估计值:
$$
\hat{p} = \frac{\overline{x}}{m}
$$