题目
4.(1)设总体X具有分布律-|||-x 1 2-|||-Pk θ^2 2θ(1-θ)(1-θ)^2-|||-其中 theta (0lt 0lt 1) 为未知参数.已知取得了样本值 _(1)=1 _(2)=2 _(3)=1.-|||-试求θ的矩估计值和最大似然估计值.-|||-(2)设X1,X2,···,Nn是来自参数为λ的泊松分布总体的一个样本,试求λ-|||-的最大似然估计量及矩估计量.

题目解答
答案
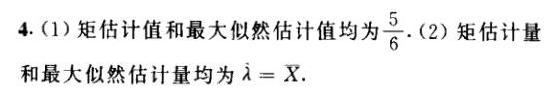
解析
步骤 1:矩估计值
矩估计法是利用样本矩来估计总体中相应的参数。首先,根据总体的分布律,计算总体的一阶矩(即期望值)。
总体的期望值为:
$$
E(X) = 1 \cdot \theta^2 + 2 \cdot 2\theta(1-\theta) + 2 \cdot (1-\theta)^2 = \theta^2 + 4\theta(1-\theta) + 2(1-\theta)^2
$$
简化后得到:
$$
E(X) = \theta^2 + 4\theta - 4\theta^2 + 2 - 4\theta + 2\theta^2 = 2 - \theta^2
$$
样本均值为:
$$
\overline{X} = \frac{1+2+1}{3} = \frac{4}{3}
$$
令总体期望等于样本均值,得到:
$$
2 - \theta^2 = \frac{4}{3}
$$
解得:
$$
\theta^2 = \frac{2}{3}
$$
$$
\theta = \sqrt{\frac{2}{3}} = \frac{\sqrt{6}}{3}
$$
步骤 2:最大似然估计值
最大似然估计法是通过最大化似然函数来估计参数。似然函数为:
$$
L(\theta) = \theta^2 \cdot 2\theta(1-\theta) \cdot \theta^2 = 2\theta^5(1-\theta)
$$
对似然函数取对数,得到对数似然函数:
$$
\ln L(\theta) = \ln(2\theta^5(1-\theta)) = \ln 2 + 5\ln\theta + \ln(1-\theta)
$$
对对数似然函数求导,得到:
$$
\frac{d}{d\theta} \ln L(\theta) = \frac{5}{\theta} - \frac{1}{1-\theta}
$$
令导数等于0,得到:
$$
\frac{5}{\theta} - \frac{1}{1-\theta} = 0
$$
解得:
$$
5(1-\theta) = \theta
$$
$$
5 - 5\theta = \theta
$$
$$
6\theta = 5
$$
$$
\theta = \frac{5}{6}
$$
步骤 3:泊松分布的矩估计量和最大似然估计量
泊松分布的期望值为λ,样本均值为:
$$
\overline{X} = \frac{1}{n} \sum_{i=1}^{n} X_i
$$
令总体期望等于样本均值,得到:
$$
\lambda = \overline{X}
$$
矩估计法是利用样本矩来估计总体中相应的参数。首先,根据总体的分布律,计算总体的一阶矩(即期望值)。
总体的期望值为:
$$
E(X) = 1 \cdot \theta^2 + 2 \cdot 2\theta(1-\theta) + 2 \cdot (1-\theta)^2 = \theta^2 + 4\theta(1-\theta) + 2(1-\theta)^2
$$
简化后得到:
$$
E(X) = \theta^2 + 4\theta - 4\theta^2 + 2 - 4\theta + 2\theta^2 = 2 - \theta^2
$$
样本均值为:
$$
\overline{X} = \frac{1+2+1}{3} = \frac{4}{3}
$$
令总体期望等于样本均值,得到:
$$
2 - \theta^2 = \frac{4}{3}
$$
解得:
$$
\theta^2 = \frac{2}{3}
$$
$$
\theta = \sqrt{\frac{2}{3}} = \frac{\sqrt{6}}{3}
$$
步骤 2:最大似然估计值
最大似然估计法是通过最大化似然函数来估计参数。似然函数为:
$$
L(\theta) = \theta^2 \cdot 2\theta(1-\theta) \cdot \theta^2 = 2\theta^5(1-\theta)
$$
对似然函数取对数,得到对数似然函数:
$$
\ln L(\theta) = \ln(2\theta^5(1-\theta)) = \ln 2 + 5\ln\theta + \ln(1-\theta)
$$
对对数似然函数求导,得到:
$$
\frac{d}{d\theta} \ln L(\theta) = \frac{5}{\theta} - \frac{1}{1-\theta}
$$
令导数等于0,得到:
$$
\frac{5}{\theta} - \frac{1}{1-\theta} = 0
$$
解得:
$$
5(1-\theta) = \theta
$$
$$
5 - 5\theta = \theta
$$
$$
6\theta = 5
$$
$$
\theta = \frac{5}{6}
$$
步骤 3:泊松分布的矩估计量和最大似然估计量
泊松分布的期望值为λ,样本均值为:
$$
\overline{X} = \frac{1}{n} \sum_{i=1}^{n} X_i
$$
令总体期望等于样本均值,得到:
$$
\lambda = \overline{X}
$$