题目
设总体X的分布律为X 1 2 3 _-|||-P α^2 alpha (1-alpha ) ((1-a))^2其中X 1 2 3 _-|||-P α^2 alpha (1-alpha ) ((1-a))^2是非负未知参数,利用总体X的如下样本值1 , 2 , 3 , 2 , 1,试求(1)X 1 2 3 _-|||-P α^2 alpha (1-alpha ) ((1-a))^2的矩估计值;(2)X 1 2 3 _-|||-P α^2 alpha (1-alpha ) ((1-a))^2的最大似然估计值.
设总体X的分布律为

其中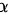 是非负未知参数,利用总体X的如下样本值1 , 2 , 3 , 2 , 1,试求(1)的矩估计值;(2)的最大似然估计值.
是非负未知参数,利用总体X的如下样本值1 , 2 , 3 , 2 , 1,试求(1)的矩估计值;(2)的最大似然估计值.
题目解答
答案
(1)X的数学期望为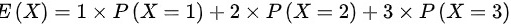
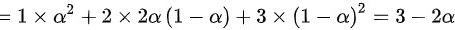 ,样本均值
,样本均值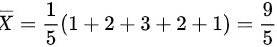 ,令
,令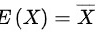 ,则的矩估计值为
,则的矩估计值为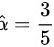 ;
;
(2)的似然函数为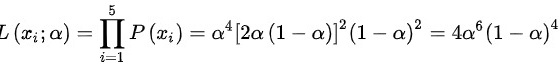 ,似然函数取对数,则
,似然函数取对数,则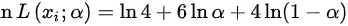 ,似然函数对参数求偏导,则
,似然函数对参数求偏导,则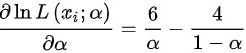 ,令
,令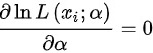 ,则的最大似然估计值为.
,则的最大似然估计值为.
解析
步骤 1:求解总体X的数学期望
总体X的数学期望$E(X)$可以通过分布律计算,即$E(X)=\sum_{i=1}^{3}x_iP(X=x_i)$,其中$x_i$是X的取值,$P(X=x_i)$是对应的概率。根据题目给出的分布律,我们有:
$E(X)=1\times P(X=1)+2\times P(X=2)+3\times P(X=3)$
$=1\times a^2+2\times 2a(1-a)+3\times (1-a)^2$
$=a^2+4a(1-a)+3(1-a)^2$
$=a^2+4a-4a^2+3-6a+3a^2$
$=3-2a$
步骤 2:求解样本均值
样本均值$\overline{X}$是样本值的平均值,即$\overline{X}=\frac{1}{n}\sum_{i=1}^{n}x_i$,其中$n$是样本数量,$x_i$是第$i$个样本值。根据题目给出的样本值1, 2, 3, 2, 1,我们有:
$\overline{X}=\frac{1}{5}(1+2+3+2+1)=\frac{9}{5}$
步骤 3:求解矩估计值
矩估计值是通过令总体的数学期望等于样本均值来求解的,即$E(X)=\overline{X}$。根据步骤1和步骤2的结果,我们有:
$3-2a=\frac{9}{5}$
解这个方程,得到$a=\frac{3}{5}$
步骤 4:求解最大似然估计值
最大似然估计值是通过最大化似然函数来求解的。似然函数$L(a)$是参数$a$的函数,表示在给定样本值的情况下,参数$a$的似然性。根据题目给出的分布律,我们有:
$L(a)=P(X=1)^{n_1}P(X=2)^{n_2}P(X=3)^{n_3}$
其中$n_1$,$n_2$,$n_3$分别是样本值1,2,3出现的次数。根据题目给出的样本值1, 2, 3, 2, 1,我们有$n_1=2$,$n_2=2$,$n_3=1$。因此,似然函数为:
$L(a)=a^{2\times2}(2a(1-a))^{2\times2}(1-a)^{1\times1}$
$=a^4(2a(1-a))^4(1-a)$
$=16a^6(1-a)^5$
对似然函数取对数,得到对数似然函数$\ln L(a)$:
$\ln L(a)=\ln(16a^6(1-a)^5)$
$=\ln 16+6\ln a+5\ln(1-a)$
对对数似然函数求导,得到导数$\frac{\partial \ln L(a)}{\partial a}$:
$\frac{\partial \ln L(a)}{\partial a}=\frac{6}{a}-\frac{5}{1-a}$
令导数等于0,得到最大似然估计值$a$:
$\frac{6}{a}-\frac{5}{1-a}=0$
解这个方程,得到$a=\frac{3}{5}$
总体X的数学期望$E(X)$可以通过分布律计算,即$E(X)=\sum_{i=1}^{3}x_iP(X=x_i)$,其中$x_i$是X的取值,$P(X=x_i)$是对应的概率。根据题目给出的分布律,我们有:
$E(X)=1\times P(X=1)+2\times P(X=2)+3\times P(X=3)$
$=1\times a^2+2\times 2a(1-a)+3\times (1-a)^2$
$=a^2+4a(1-a)+3(1-a)^2$
$=a^2+4a-4a^2+3-6a+3a^2$
$=3-2a$
步骤 2:求解样本均值
样本均值$\overline{X}$是样本值的平均值,即$\overline{X}=\frac{1}{n}\sum_{i=1}^{n}x_i$,其中$n$是样本数量,$x_i$是第$i$个样本值。根据题目给出的样本值1, 2, 3, 2, 1,我们有:
$\overline{X}=\frac{1}{5}(1+2+3+2+1)=\frac{9}{5}$
步骤 3:求解矩估计值
矩估计值是通过令总体的数学期望等于样本均值来求解的,即$E(X)=\overline{X}$。根据步骤1和步骤2的结果,我们有:
$3-2a=\frac{9}{5}$
解这个方程,得到$a=\frac{3}{5}$
步骤 4:求解最大似然估计值
最大似然估计值是通过最大化似然函数来求解的。似然函数$L(a)$是参数$a$的函数,表示在给定样本值的情况下,参数$a$的似然性。根据题目给出的分布律,我们有:
$L(a)=P(X=1)^{n_1}P(X=2)^{n_2}P(X=3)^{n_3}$
其中$n_1$,$n_2$,$n_3$分别是样本值1,2,3出现的次数。根据题目给出的样本值1, 2, 3, 2, 1,我们有$n_1=2$,$n_2=2$,$n_3=1$。因此,似然函数为:
$L(a)=a^{2\times2}(2a(1-a))^{2\times2}(1-a)^{1\times1}$
$=a^4(2a(1-a))^4(1-a)$
$=16a^6(1-a)^5$
对似然函数取对数,得到对数似然函数$\ln L(a)$:
$\ln L(a)=\ln(16a^6(1-a)^5)$
$=\ln 16+6\ln a+5\ln(1-a)$
对对数似然函数求导,得到导数$\frac{\partial \ln L(a)}{\partial a}$:
$\frac{\partial \ln L(a)}{\partial a}=\frac{6}{a}-\frac{5}{1-a}$
令导数等于0,得到最大似然估计值$a$:
$\frac{6}{a}-\frac{5}{1-a}=0$
解这个方程,得到$a=\frac{3}{5}$