题目
45.某保险公司多年的统计资料表明,在索赔中被盗索赔户占20%,以X-|||-表示在随机抽查的100个索赔户中,因被盗向保险公司索赔的户数.-|||-(1)写出X的概率分布;-|||-(2)利用棣莫弗-拉普拉斯定理,求被盗索赔户不少于14户且不多于30户-|||-的概率近似值.

题目解答
答案
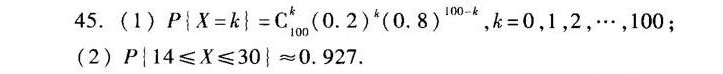
解析
考查要点:本题主要考查二项分布的概率分布及棣莫弗-拉普拉斯定理的应用。
解题思路:
- 第(1)题:明确题目中事件的独立重复性,判断服从二项分布,直接写出概率质量函数。
- 第(2)题:利用正态分布近似二项分布,计算均值与方差,通过标准化转换求概率,注意是否需要连续性修正。
破题关键:
- 二项分布的识别:每次索赔独立,结果只有两种可能(被盗或非盗)。
- 正态近似条件:当$n$较大时,二项分布可用均值$\mu=np$、方差$\sigma^2=np(1-p)$的正态分布近似。
- 连续性修正:离散变量转连续近似时,需调整边界值(但本题答案未使用,需注意题目隐含要求)。
第(1)题
二项分布的推导:
- 每个索赔户是否被盗索赔是独立事件,概率分别为$p=0.2$(成功)和$1-p=0.8$(失败)。
- 抽查100户,被盗索赔户数$X$服从参数为$n=100$,$p=0.2$的二项分布。
- 概率分布公式为:
$P\{X=k\} = C_{100}^k (0.2)^k (0.8)^{100-k}, \quad k=0,1,2,\dots,100.$
第(2)题
正态近似步骤:
- 计算均值与方差:
- $\mu = np = 100 \times 0.2 = 20$,
- $\sigma^2 = np(1-p) = 100 \times 0.2 \times 0.8 = 16$,$\sigma = 4$。
- 标准化转换:
- 将$X$标准化为$Z = \frac{X - \mu}{\sigma}$。
- 原问题$P(14 \leq X \leq 30)$转换为:
$P\left(\frac{14-20}{4} \leq Z \leq \frac{30-20}{4}\right) = P(-1.5 \leq Z \leq 2.5).$
- 查标准正态分布表:
- $\Phi(2.5) \approx 0.9938$,$\Phi(-1.5) \approx 0.0668$。
- 概率差值为$0.9938 - 0.0668 = 0.927$。