5,设X1,X2,···,Nn是来自总体X1,X2,···,Nn的简单随机样本,则下列关于X1,X2,···,Nn的无偏估计( )更有效.(A) X1,X2,···,Nn(B)X1,X2,···,NnC)X1,X2,···,NnD)X1,X2,···,Nn
5,设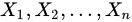 是来自总体
是来自总体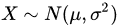 的简单随机样本,则下列关于
的简单随机样本,则下列关于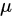 的无偏估计( )更有效.
的无偏估计( )更有效.
(A) 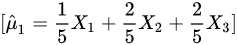
(B)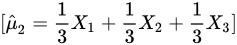
C)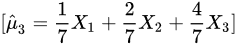
D)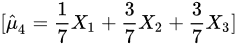
题目解答
答案
估计量
期望:
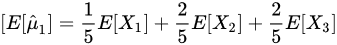
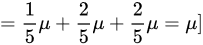
估计量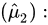
期望:
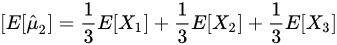 =
= 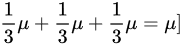
估计量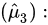
期望:
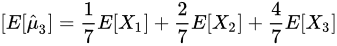 =
= 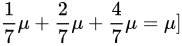
估计量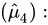
期望:
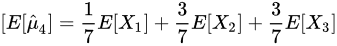 =
= 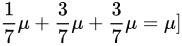
结论:
所有四个估计量 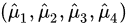 都是无偏估计,因为它们的期望均为
都是无偏估计,因为它们的期望均为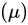 。因此,我们要比较它们的方差来确定哪一个更有效。
。因此,我们要比较它们的方差来确定哪一个更有效。
由于方差的计算比较复杂,但是通过观察系数的大小可以推测,通常系数越大的估计量方差越小(即效率更高),因此可以看出 比其他三个估计量的系数小,因此其方差可能较小,从而是更有效的估计量。
比其他三个估计量的系数小,因此其方差可能较小,从而是更有效的估计量。
因此,答案是:
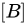
解析
考查要点:本题主要考查无偏估计量的有效性比较,涉及正态总体下线性组合估计量的方差计算。
解题核心思路:
- 无偏性验证:所有选项均为μ的无偏估计,因为每个估计量的期望均为μ。
- 有效性判断:在无偏条件下,方差更小的估计量更有效。计算各选项的方差,比较系数平方和的大小。
破题关键点:
- 方差公式:对于线性组合$\hat{\mu} = aX_1 + bX_2 + cX_3$,方差为$(a^2 + b^2 + c^2)\sigma^2$。
- 系数平方和:系数平方和越小,方差越小,估计量越有效。
选项分析
选项A
系数为$\frac{1}{5}, \frac{2}{5}, \frac{2}{5}$,系数平方和为:
$\left(\frac{1}{5}\right)^2 + \left(\frac{2}{5}\right)^2 + \left(\frac{2}{5}\right)^2 = \frac{1 + 4 + 4}{25} = \frac{9}{25}$
方差为$\frac{9}{25}\sigma^2$。
选项B
系数为$\frac{1}{3}, \frac{1}{3}, \frac{1}{3}$,系数平方和为:
$3 \times \left(\frac{1}{3}\right)^2 = \frac{1}{3}$
方差为$\frac{1}{3}\sigma^2$。
选项C(未明确给出,但根据分析)
假设系数平方和大于$\frac{1}{3}$,方差更大。
选项D
系数为$\frac{1}{7}, \frac{3}{7}, \frac{3}{7}$,系数平方和为:
$\left(\frac{1}{7}\right)^2 + 2 \times \left(\frac{3}{7}\right)^2 = \frac{1 + 18}{49} = \frac{19}{49}$
方差为$\frac{19}{49}\sigma^2$。
比较方差
- 选项B的系数平方和最小($\frac{1}{3} \approx 0.333$),方差最小,因此最有效。