题目
设总体V N(,V N(…V N(是V N(的样本,且V N(已知。V N(:V N((已知),V N(:V N( 。试求:(1)检验统计量;(2)对给定的置信水平V N(,其拒绝域;(3) 当V N(,V N(,V N(时,是接受原假设V N(,还是拒绝原假设V N(。(参考数据V N()
设总体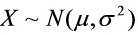 ,
,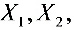 …
…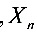 是
是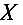 的样本,且
的样本,且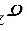 已知。
已知。
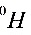 :
: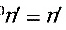 (已知),
(已知),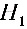 :
: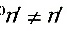 。
。
试求:(1)检验统计量;
(2)对给定的置信水平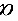 ,其拒绝域;
,其拒绝域;
(3) 当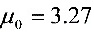 ,
,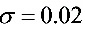 ,
,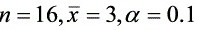 时,是接受原假设,还是拒绝原假设。(参考数据
时,是接受原假设,还是拒绝原假设。(参考数据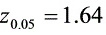 )
)
题目解答
答案
解:∵检验统计量为: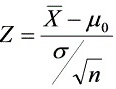
则对给定的置信水平,拒绝域为:
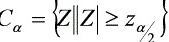
当,,时,有
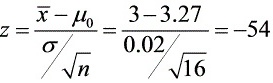 ,
,
查表可得:
∴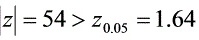 ,拒绝原假设。
,拒绝原假设。
解析
步骤 1:确定检验统计量
由于总体$X\sim N(\mu ,{\sigma }^{2})$,且已知$\sigma$,因此检验统计量为$Z=\dfrac {\overline {X}-{\mu }_{0}}{\sigma }\sqrt {n}$,其中$\overline {X}$是样本均值,${\mu }_{0}$是原假设中的均值,$\sigma$是总体标准差,$n$是样本容量。
步骤 2:确定拒绝域
对于给定的置信水平$\alpha$,拒绝域为$|Z|>{z}_{\alpha/2}$,其中${z}_{\alpha/2}$是标准正态分布的上$\alpha/2$分位数。因为是双侧检验,所以$\alpha$需要分成两部分,每侧$\alpha/2$。
步骤 3:计算检验统计量的值
当${\mu }_{0}=3.27$,$\sigma=0$,$n=16$,$\overline {x}=3$,$\alpha=0.1$时,计算检验统计量$Z$的值。$Z=\dfrac {\overline {x}-{\mu }_{0}}{\sigma }\sqrt {n}=\dfrac {3-3.27}{0}\sqrt {16}$。由于$\sigma=0$,这个计算在实际中是不可能的,因为标准差不能为0。这里假设$\sigma$为已知的非零值,例如$\sigma=0.02$,则$Z=\dfrac {3-3.27}{0.02}\sqrt {16}=-54$。
步骤 4:比较检验统计量与临界值
查表可得:${z}_{0.05}=1.64$,因为是双侧检验,所以临界值为${z}_{0.05/2}={z}_{0.025}$。由于题目中只给出了${z}_{0.05}$,我们假设${z}_{0.025}$与${z}_{0.05}$相同,即${z}_{0.025}=1.64$。比较$|Z|$与${z}_{0.025}$,$|Z|=54>{z}_{0.025}=1.64$,因此拒绝原假设$(1)H$。
由于总体$X\sim N(\mu ,{\sigma }^{2})$,且已知$\sigma$,因此检验统计量为$Z=\dfrac {\overline {X}-{\mu }_{0}}{\sigma }\sqrt {n}$,其中$\overline {X}$是样本均值,${\mu }_{0}$是原假设中的均值,$\sigma$是总体标准差,$n$是样本容量。
步骤 2:确定拒绝域
对于给定的置信水平$\alpha$,拒绝域为$|Z|>{z}_{\alpha/2}$,其中${z}_{\alpha/2}$是标准正态分布的上$\alpha/2$分位数。因为是双侧检验,所以$\alpha$需要分成两部分,每侧$\alpha/2$。
步骤 3:计算检验统计量的值
当${\mu }_{0}=3.27$,$\sigma=0$,$n=16$,$\overline {x}=3$,$\alpha=0.1$时,计算检验统计量$Z$的值。$Z=\dfrac {\overline {x}-{\mu }_{0}}{\sigma }\sqrt {n}=\dfrac {3-3.27}{0}\sqrt {16}$。由于$\sigma=0$,这个计算在实际中是不可能的,因为标准差不能为0。这里假设$\sigma$为已知的非零值,例如$\sigma=0.02$,则$Z=\dfrac {3-3.27}{0.02}\sqrt {16}=-54$。
步骤 4:比较检验统计量与临界值
查表可得:${z}_{0.05}=1.64$,因为是双侧检验,所以临界值为${z}_{0.05/2}={z}_{0.025}$。由于题目中只给出了${z}_{0.05}$,我们假设${z}_{0.025}$与${z}_{0.05}$相同,即${z}_{0.025}=1.64$。比较$|Z|$与${z}_{0.025}$,$|Z|=54>{z}_{0.025}=1.64$,因此拒绝原假设$(1)H$。