题目
某工厂生产的灯泡的平均寿命为2000小时,改进工艺后,平均寿命提高到2250小时,标准差仍为250小时.为鉴定此项新工艺,特规定:任意抽取若干只灯泡,若平均寿命超过2200小时,就可承认此项新工艺.工厂为使此项新工艺通过鉴定的概率不小于0.997,问至少应抽检多少只灯泡?
某工厂生产的灯泡的平均寿命为2000小时,改进工艺后,平均寿命提高到2250小时,标准差仍为250小时.为鉴定此项新工艺,特规定:任意抽取若干只灯泡,若平均寿命超过2200小时,就可承认此项新工艺.工厂为使此项新工艺通过鉴定的概率不小于0.997,问至少应抽检多少只灯泡?
题目解答
答案
解:设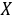 为改进后的灯泡的寿命,由题设,
为改进后的灯泡的寿命,由题设,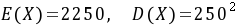 ,又设
,又设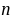 为使检验通过所需抽取的灯泡数,依题意可建立如下不等式
为使检验通过所需抽取的灯泡数,依题意可建立如下不等式 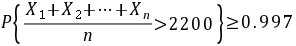 ,
,
或 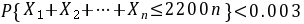 ,
,
由林德贝格—列维中心极限定理知,
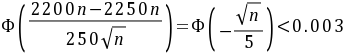 ,
,
查表可得如下不等式
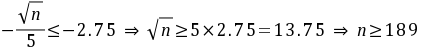 ,
,
即需随机抽取189只灯泡进行寿命检验,测得的平均寿命才能以95%的概率保证超过2200小时.
解析
步骤 1:定义随机变量
设 $X_i$ 为改进工艺后第 $i$ 只灯泡的寿命,$i=1,2,\cdots,n$。由题设,$E(X_i)=2250$,$D(X_i)=250^2$。
步骤 2:建立不等式
设 $n$ 为需要抽取的灯泡数,依题意,要使平均寿命超过2200小时的概率不小于0.997,即
$$
P\left(\frac{X_1+X_2+\cdots+X_n}{n} > 2200\right) \geqslant 0.997
$$
步骤 3:应用中心极限定理
由林德贝格—列维中心极限定理知,当 $n$ 足够大时,$\frac{X_1+X_2+\cdots+X_n}{n}$ 近似服从正态分布 $N(2250, \frac{250^2}{n})$。因此,上述不等式可以转化为
$$
P\left(\frac{X_1+X_2+\cdots+X_n}{n} \leqslant 2200\right) < 0.003
$$
步骤 4:标准化并查表
将上述不等式标准化,得到
$$
\Phi\left(\frac{2200n-2250n}{250\sqrt{n}}\right) = \Phi\left(-\frac{\sqrt{n}}{5}\right) < 0.003
$$
查标准正态分布表,得到
$$
-\frac{\sqrt{n}}{5} \leqslant -2.75
$$
步骤 5:求解不等式
解上述不等式,得到
$$
\sqrt{n} \geqslant 5 \times 2.75 = 13.75
$$
$$
n \geqslant 189
$$
设 $X_i$ 为改进工艺后第 $i$ 只灯泡的寿命,$i=1,2,\cdots,n$。由题设,$E(X_i)=2250$,$D(X_i)=250^2$。
步骤 2:建立不等式
设 $n$ 为需要抽取的灯泡数,依题意,要使平均寿命超过2200小时的概率不小于0.997,即
$$
P\left(\frac{X_1+X_2+\cdots+X_n}{n} > 2200\right) \geqslant 0.997
$$
步骤 3:应用中心极限定理
由林德贝格—列维中心极限定理知,当 $n$ 足够大时,$\frac{X_1+X_2+\cdots+X_n}{n}$ 近似服从正态分布 $N(2250, \frac{250^2}{n})$。因此,上述不等式可以转化为
$$
P\left(\frac{X_1+X_2+\cdots+X_n}{n} \leqslant 2200\right) < 0.003
$$
步骤 4:标准化并查表
将上述不等式标准化,得到
$$
\Phi\left(\frac{2200n-2250n}{250\sqrt{n}}\right) = \Phi\left(-\frac{\sqrt{n}}{5}\right) < 0.003
$$
查标准正态分布表,得到
$$
-\frac{\sqrt{n}}{5} \leqslant -2.75
$$
步骤 5:求解不等式
解上述不等式,得到
$$
\sqrt{n} \geqslant 5 \times 2.75 = 13.75
$$
$$
n \geqslant 189
$$