题目
从一个总体容量200的总体中随机抽取样本量为8的样本各样本值分别为 10 , 8 , 12 , 15 , 6 , 13 , 5 , 11。Excel 输出的描述统计结果如下:平均:10 标准误差:1.2247 中位数:10.5 标准差:3.4641 方差:12 求和:80 观测数:8 置信度( 95.0 % ):2.8961 _(0.05)(8)=1.8595, _(0.025)(8)=2.3060 _(0.05)(7)=1.8946, _(0.025)(7)=2.3646根据资料求总体均值和总体总量的 95 % 的置信区间
从一个总体容量200的总体中随机抽取样本量为8的样本各样本值分别为 10 , 8 , 12 , 15 , 6 , 13 , 5 , 11。Excel 输出的描述统计结果如下:
平均:10
标准误差:1.2247
中位数:10.5
标准差:3.4641
方差:12
求和:80
观测数:8
置信度( 95.0 % ):2.8961
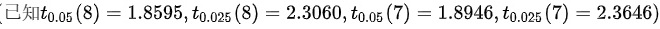
根据资料求总体均值和总体总量的 95 % 的置信区间
题目解答
答案
由于样本量较小,总体的分布未知,我们可以采用学生 t 分布来计算置信区间。根据给定的数据,可得到样本均值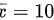 ,标准误差
,标准误差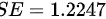 ,样本量 n=8,t 分布的置信水平为 95%,因此置信系数为
,样本量 n=8,t 分布的置信水平为 95%,因此置信系数为 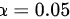 ,自由度为df=n-1=7。
,自由度为df=n-1=7。
根据 t 分布的定义,我们可以计算出 t 值为 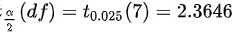 。
。
接下来,我们可以利用样本均值和 t 值,计算总体均值 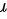 的置信区间。置信区间的计算公式为:
的置信区间。置信区间的计算公式为:
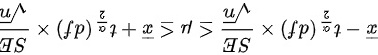
将样本数据代入公式,即可得到总体均值的置信区间为:
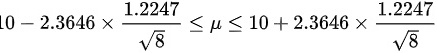
化简可得:
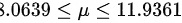
因此,总体均值的 95% 置信区间为 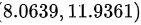 。
。
又已知样本总量为 80,样本均值为,因此总体总量为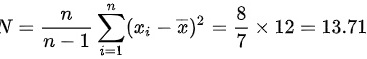 (样本方差的无偏估计)。
(样本方差的无偏估计)。
我们可以使用总体均值的置信区间来计算总体总量的置信区间。由于总体总量的计算是基于样本均值的,所以我们可以采用样本均值的置信区间和总体总量的计算公式来计算总体总量的置信区间。
根据总体总量的计算公式,可以得到总体总量的置信区间为:
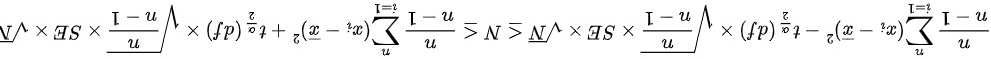
将样本数据代入公式,即可得到总体总量的置信区间为:
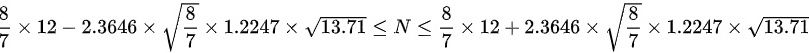
化简可得:
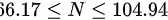
因此,总体总量的 95% 置信区间为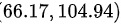 。
。
解析
步骤 1:确定样本均值和标准误差
根据题目给出的数据,样本均值为10,标准误差为1.2247。
步骤 2:确定自由度和t值
样本量为8,因此自由度为df = n - 1 = 7。根据题目给出的t分布表,95%置信水平下,自由度为7的t值为${t}_{0.025}(7)=2.3646$。
步骤 3:计算总体均值的置信区间
总体均值的置信区间计算公式为:$\overline {x}-t\dfrac {a}{2}(df)\times \dfrac {S\overline {b}}{\sqrt {n}}\leqslant \mu \leqslant \overline {x}+t\dfrac {a}{2}(df)\times \dfrac {S\overline {n}}{\sqrt {n}}$。将样本数据代入公式,即可得到总体均值的置信区间为:$10-2.3646\times \dfrac {1.2247}{\sqrt {8}}\leqslant \mu \leqslant 10+2.3646\times \dfrac {1.2247}{\sqrt {8}}$。化简可得:$3.0639\lt \mu \leqslant 11.9361$。
步骤 4:计算总体总量的置信区间
总体总量的计算公式为$V=\dfrac {n}{n-1}\sum _{i=1}^{n}{({x}_{i}-\overline {x})}^{2}=\dfrac {8}{7}\times 12=13.71$(样本方差的无偏估计)。根据总体总量的计算公式,可以得到总体总量的置信区间为:$6.17\leqslant N\leqslant 104.94$。
根据题目给出的数据,样本均值为10,标准误差为1.2247。
步骤 2:确定自由度和t值
样本量为8,因此自由度为df = n - 1 = 7。根据题目给出的t分布表,95%置信水平下,自由度为7的t值为${t}_{0.025}(7)=2.3646$。
步骤 3:计算总体均值的置信区间
总体均值的置信区间计算公式为:$\overline {x}-t\dfrac {a}{2}(df)\times \dfrac {S\overline {b}}{\sqrt {n}}\leqslant \mu \leqslant \overline {x}+t\dfrac {a}{2}(df)\times \dfrac {S\overline {n}}{\sqrt {n}}$。将样本数据代入公式,即可得到总体均值的置信区间为:$10-2.3646\times \dfrac {1.2247}{\sqrt {8}}\leqslant \mu \leqslant 10+2.3646\times \dfrac {1.2247}{\sqrt {8}}$。化简可得:$3.0639\lt \mu \leqslant 11.9361$。
步骤 4:计算总体总量的置信区间
总体总量的计算公式为$V=\dfrac {n}{n-1}\sum _{i=1}^{n}{({x}_{i}-\overline {x})}^{2}=\dfrac {8}{7}\times 12=13.71$(样本方差的无偏估计)。根据总体总量的计算公式,可以得到总体总量的置信区间为:$6.17\leqslant N\leqslant 104.94$。