题目
某公共汽车站从上午7时起每15分钟发一班车,即在7:00,7:15,7:30,…有汽车发出,如果乘客到达此汽车站的时间是在7:007:30的均匀随机变量,试求乘客在车站等候(1)不到5分钟的概率。(2)超过10分钟的概率。
某公共汽车站从上午7时起每15分钟发一班车,即在7:00,7:15,7:30,…有汽车发出,如果乘客到达此汽车站的时间是在7:007:30的均匀随机变量,试求乘客在车站等候(1)不到5分钟的概率。(2)超过10分钟的概率。
题目解答
答案
解 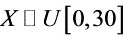
(1)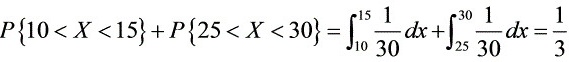 。
。
(2)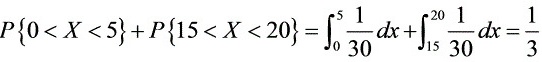 。
。
解析
考查要点:本题主要考查均匀分布的概率计算,以及如何根据实际问题确定有效区间。
解题思路:
- 明确发车规律:每15分钟一班车,乘客到达时间在7:00到7:30之间(即区间$[0,30]$分钟)。
- 划分时间段:根据发车时间点(0,15,30分钟),将乘客到达时间分为两段:$[0,15)$和$[15,30)$。
- 确定等候时间表达式:
- 在$[0,15)$到达,等候时间为$15 - X$;
- 在$[15,30)$到达,等候时间为$30 - X$。
- 建立不等式求区间:根据题目要求的等候时间条件,解不等式得到有效区间,最后计算区间长度占总时间的比例。
(1) 不到5分钟的概率
- 确定有效区间:
- 在$[0,15)$到达:要求$15 - X < 5 \Rightarrow X > 10$,即区间$(10,15)$。
- 在$[15,30)$到达:要求$30 - X < 5 \Rightarrow X > 25$,即区间$(25,30)$。
- 计算概率:
- 有效区间总长度:$5 + 5 = 10$分钟。
- 概率:$\dfrac{10}{30} = \dfrac{1}{3}$。
(2) 超过10分钟的概率
- 确定有效区间:
- 在$[0,15)$到达:要求$15 - X > 10 \Rightarrow X < 5$,即区间$(0,5)$。
- 在$[15,30)$到达:要求$30 - X > 10 \Rightarrow X < 20$,即区间$(15,20)$。
- 计算概率:
- 有效区间总长度:$5 + 5 = 10$分钟。
- 概率:$\dfrac{10}{30} = \dfrac{1}{3}$。