题目
用一机床制造大小相同的零件,由于随机误差,每个零件的质量(单位:Kg)在上服从均匀分布,设每个零件的质量相互独立,制造1200个零件,试用中心极限定理求总质量介于1198Kg与1209Kg之间的概率。()
用一机床制造大小相同的零件,由于随机误差,每个零件的质量(单位:Kg)在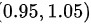 上服从均匀分布,设每个零件的质量相互独立,制造1200个零件,试用中心极限定理求总质量介于1198Kg与1209Kg之间的概率。(
上服从均匀分布,设每个零件的质量相互独立,制造1200个零件,试用中心极限定理求总质量介于1198Kg与1209Kg之间的概率。(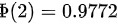 )
)
题目解答
答案
用X表示每个零件的质量,则X服从区间上服从均匀分布,则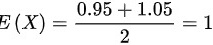 ,
,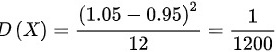 ,则
,则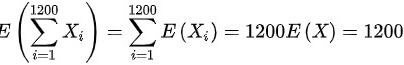 ,
,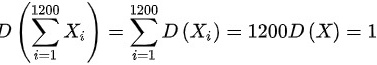 ,则
,则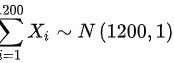 ,则
,则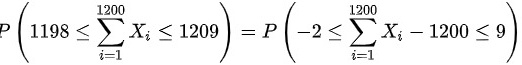
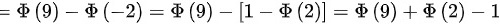
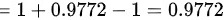 .
.
解析
步骤 1:确定单个零件质量的期望值和方差
每个零件的质量X在0.95到1.05之间服从均匀分布,因此其期望值E(X)和方差D(X)可以计算如下:
\[ E(X) = \frac{0.95 + 1.05}{2} = 1 \]
\[ D(X) = \frac{(1.05 - 0.95)^2}{12} = \frac{1}{1200} \]
步骤 2:计算1200个零件总质量的期望值和方差
由于每个零件的质量相互独立,1200个零件的总质量的期望值和方差分别为:
\[ E(\sum_{i=1}^{1200} X_i) = 1200 \times E(X) = 1200 \times 1 = 1200 \]
\[ D(\sum_{i=1}^{1200} X_i) = 1200 \times D(X) = 1200 \times \frac{1}{1200} = 1 \]
步骤 3:应用中心极限定理
根据中心极限定理,当样本量足够大时,样本均值的分布近似于正态分布。因此,1200个零件的总质量的分布近似于正态分布N(1200, 1)。我们需要计算总质量介于1198Kg与1209Kg之间的概率,即:
\[ P(1198 \leq \sum_{i=1}^{1200} X_i \leq 1209) \]
将这个概率转化为标准正态分布的概率:
\[ P\left(\frac{1198 - 1200}{\sqrt{1}} \leq \frac{\sum_{i=1}^{1200} X_i - 1200}{\sqrt{1}} \leq \frac{1209 - 1200}{\sqrt{1}}\right) \]
\[ = P(-2 \leq Z \leq 9) \]
其中Z是标准正态分布的随机变量。根据标准正态分布表,可以查得:
\[ P(Z \leq 9) = 1 \]
\[ P(Z \leq -2) = 1 - P(Z \leq 2) = 1 - 0.9772 = 0.0228 \]
因此:
\[ P(-2 \leq Z \leq 9) = P(Z \leq 9) - P(Z \leq -2) = 1 - 0.0228 = 0.9772 \]
每个零件的质量X在0.95到1.05之间服从均匀分布,因此其期望值E(X)和方差D(X)可以计算如下:
\[ E(X) = \frac{0.95 + 1.05}{2} = 1 \]
\[ D(X) = \frac{(1.05 - 0.95)^2}{12} = \frac{1}{1200} \]
步骤 2:计算1200个零件总质量的期望值和方差
由于每个零件的质量相互独立,1200个零件的总质量的期望值和方差分别为:
\[ E(\sum_{i=1}^{1200} X_i) = 1200 \times E(X) = 1200 \times 1 = 1200 \]
\[ D(\sum_{i=1}^{1200} X_i) = 1200 \times D(X) = 1200 \times \frac{1}{1200} = 1 \]
步骤 3:应用中心极限定理
根据中心极限定理,当样本量足够大时,样本均值的分布近似于正态分布。因此,1200个零件的总质量的分布近似于正态分布N(1200, 1)。我们需要计算总质量介于1198Kg与1209Kg之间的概率,即:
\[ P(1198 \leq \sum_{i=1}^{1200} X_i \leq 1209) \]
将这个概率转化为标准正态分布的概率:
\[ P\left(\frac{1198 - 1200}{\sqrt{1}} \leq \frac{\sum_{i=1}^{1200} X_i - 1200}{\sqrt{1}} \leq \frac{1209 - 1200}{\sqrt{1}}\right) \]
\[ = P(-2 \leq Z \leq 9) \]
其中Z是标准正态分布的随机变量。根据标准正态分布表,可以查得:
\[ P(Z \leq 9) = 1 \]
\[ P(Z \leq -2) = 1 - P(Z \leq 2) = 1 - 0.9772 = 0.0228 \]
因此:
\[ P(-2 \leq Z \leq 9) = P(Z \leq 9) - P(Z \leq -2) = 1 - 0.0228 = 0.9772 \]