题目
第七章练习题选择题7.1.在线性回归模型._(i)=(P)_(1)+(P)_(2)(X)_(i)+(C)_(i)中,._(i)=(P)_(1)+(P)_(2)(X)_(i)+(C)_(i)反映的是( )A. X变动一个单位时Y的实际变动量 B. 由于Y的变化引起的X的线性变化部分 C. X变动一个单位时Y的平均变动量 D. Y变动一个单位时X的平均变动量 E. ) F. 7.2在回归模型._(i)=(P)_(1)+(P)_(2)(X)_(i)+(C)_(i)中,._(i)=(P)_(1)+(P)_(2)(X)_(i)+(C)_(i)反映的是( ) G. 由于x的变化引起的Y的线性变化部分由于Y的变化引起的X的线性变化部分除了X和Y的线性关系之外的其他因素对Y的影响由于X和Y的线性关系对Y的影响)7.3在用普通最小二乘法估计模型中参数时,要求模型满足一些基本假定,根本原因是( )为了使回归方程更为简化,便于计算模型参数的估计值为了便于确定所估计参数的均值为了使估计的参数具有良好的统计性质,得出最佳线性无偏估计。为了使因变量更容易控制,保证因变量和自变量有稳定的相关性)7.4在多元线性回归中,计算了可决系数后还要计算修正的可决系数,这是为了( )可决系数的计算不很准确,需要加以修正。便于比较自变量个数不同的模型的拟合程度。为了使其与F检验结论一致。为了不损失模型的自由度。)7.5利用回归模型作区间预测时, 因变量的预测区间的宽度( )。随自变量X 的值增大而增大随自变量X 的值增大而缩小在._(i)=(P)_(1)+(P)_(2)(X)_(i)+(C)_(i)处最小在._(i)=(P)_(1)+(P)_(2)(X)_(i)+(C)_(i) 处最大)判断题7.1样本容量为n=35,作两个回归模型:模型1:._(i)=(P)_(1)+(P)_(2)(X)_(i)+(C)_(i),可决系数为._(i)=(P)_(1)+(P)_(2)(X)_(i)+(C)_(i)0.8850;模型2:._(i)=(P)_(1)+(P)_(2)(X)_(i)+(C)_(i),可决系数为._(i)=(P)_(1)+(P)_(2)(X)_(i)+(C)_(i)0.9012。因为模型2的可决系数大于模型1 ,所以模型2比模型1的拟合优度更好。判断:( )参考答:判断:(错)原因:由于在样本容量一定的条件下,总离差平方和与自变量的个数无关,而残差平方和会随着模型中自变量个数的增加而减少,至少不会增加。也就是说,随着模型中自变量的增加,多重可决系数._(i)=(P)_(1)+(P)_(2)(X)_(i)+(C)_(i)会随着自变量个数增加而增大。因此,多元线性回归模型中,在比较因变量相同而自变量个数不同的模型的拟合程度时,不能简单地对比多重可决系数。在样本容量一定的情况下,增加自变量必定使得待估参数的个数增加,从而损失自由度;而且在实际应用中,有时所增加的自变量并非必要。为此,需要用自由度去修正多重可决系数._(i)=(P)_(1)+(P)_(2)(X)_(i)+(C)_(i)中的残差平方和与回归平方和,引入修正的可决系数。7.2在回归模型参数估计方法的基本假定中,涉及对随机误差项._(i)=(P)_(1)+(P)_(2)(X)_(i)+(C)_(i)分布性质的假定,但是随机误差项._(i)=(P)_(1)+(P)_(2)(X)_(i)+(C)_(i)是未知的,在具体作回归分时不必考虑其分布。判断:( )参考答:判断:( 错 )原因: ①只有具备一定的假定条件,对模型所作出的估计才可能具有良好的统计性质,所估计的参数才能"尽可能地接近"(即"尽可能准确地估计")参数的真实值。在普通最小二乘估计的统计性质的证明中,基本假定中关于随机误差项._(i)=(P)_(1)+(P)_(2)(X)_(i)+(C)_(i)的分布性质是必备的条件。也就是说如果基本假定不成立,参数估计的无偏性、有效性或者一致性也就不一定成立。通过对高斯定理的数学证明能深刻体会到。②因为模型中有随机扰动项,所估计的参数也是随机变量,显然参数估计量的分布与随机扰动项的分布有关,只有对随机扰动项的分布作出某些假定,才能比较方便地确定参数估计量的分布性质,才可能在此基础上去对参数进行假设检验和区间估计等统计推断,也才可能对因变量作区间预测。7.3回归模型参数估计方法的基本假定主要应用于数学证明,在具体作回归分时不必考虑基本假定。判断:( )参考答:判断:( 错 )原因: ①只有具备一定的假定条件,对模型所作出的估计才可能具有良好的统计性质。所估计的参数才能"尽可能地接近"(即"尽可能准确地估计")参数的真实值。在普通最小二乘估计的统计性质的证明中,基本假定是必备的条件。也就是说如果基本假定不成立,参数估计的无偏性、有效性或者一致性也就不一定成立。通过对高斯定理的数学证明能深刻体会到。②因为模型中有随机扰动项,所估计的参数也是随机变量,显然参数估计量的分布与随机扰动项的分布有关,只有对随机扰动项的分布作出某些假定,才能比较方便地确定参数估计量的分布性质,才可能在此基础上去对参数进行假设检验和区间估计等统计推断,也才可能对因变量作区间预测。Y作区间预测,可以得到可靠的预测结果。判断:( )参考答:判断(错)原因:利用回归模型对自变量的预测区间不是常数。预测区间的上下限与以下因素有关:因为预测区间是 ._(i)=(P)_(1)+(P)_(2)(X)_(i)+(C)_(i)①样本容量n越小,预测区间将越大,②样本容量越小,._(i)=(P)_(1)+(P)_(2)(X)_(i)+(C)_(i)也越小,预测区间则越大;③随._(i)=(P)_(1)+(P)_(2)(X)_(i)+(C)_(i)的变化而变化,当._(i)=(P)_(1)+(P)_(2)(X)_(i)+(C)_(i)时,预测区间最小,随着._(i)=(P)_(1)+(P)_(2)(X)_(i)+(C)_(i)对._(i)=(P)_(1)+(P)_(2)(X)_(i)+(C)_(i)的愈加偏离,预测区间将愈宽。本例中,2000年—2010年样本容量为n=11;._(i)=(P)_(1)+(P)_(2)(X)_(i)+(C)_(i)=6,预测期2020年的序号21,._(i)=(P)_(1)+(P)_(2)(X)_(i)+(C)_(i)=21-6=15。本例中样本容量较小,预测区间较大;此外,本例的预测期偏离样本期的._(i)=(P)_(1)+(P)_(2)(X)_(i)+(C)_(i)过远,._(i)=(P)_(1)+(P)_(2)(X)_(i)+(C)_(i)较大,此时预测区间将会很宽,预测的可靠性会非常低。检验与t 检验是两种完全不同的检验,在一元回归分._(i)=(P)_(1)+(P)_(2)(X)_(i)+(C)_(i)中,对模型的F检验已得到F=155.11,P值为3.66E-13,为了检验自变量._(i)=(P)_(1)+(P)_(2)(X)_(i)+(C)_(i)的显著性,还必须作t检验。判断( )参考答案:判断(错)检验。事实上,在一元回归情形下容易证明F=t2,F检验与t检验是等价的。所以已经有F检验显著的结论,就不是必须再作t 检验。7.6 一项对多个国家心脏病死亡率与市场葡萄酒销售量回归分的研究表明,市场葡萄酒销售量上升有助于降低心脏病死亡率,这就是说每个人只要多喝葡萄酒就都会降低心脏病死亡的风险。判断( )参考答案:判断(错)原因:回归分的本质是关于一个变量(因变量)对另一个或另外多个变量(自变量)依存关系的研究,是用适当的回归模型去近似地表达或估计变量之间的平均变化关系,也就是要根据自变量的固定值去估计和预测因变量的平均值。虽然从平均意义上说,市场葡萄酒销售量上升有利于有助于降低心脏病死亡率,但是并不是对每个个人都是这样。
第七章练习题
选择题
7.1.在线性回归模型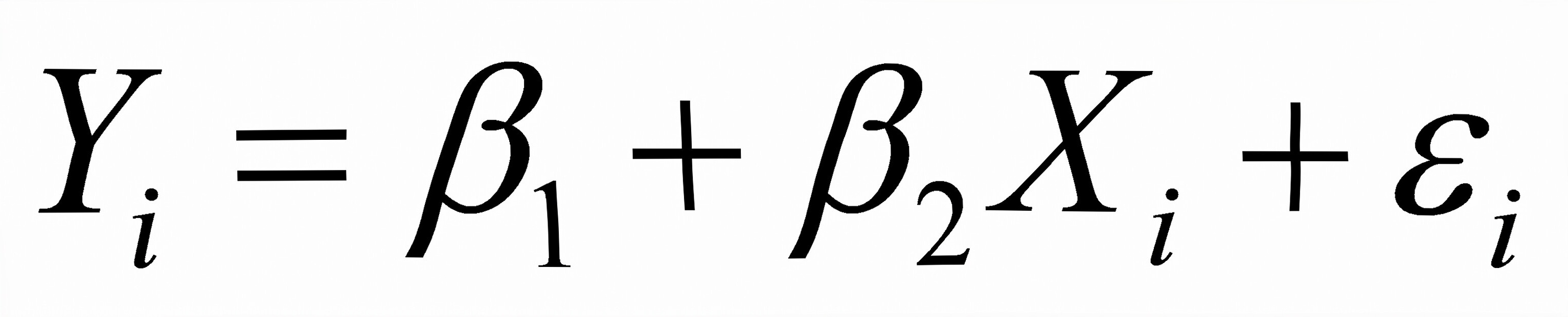 中,
中,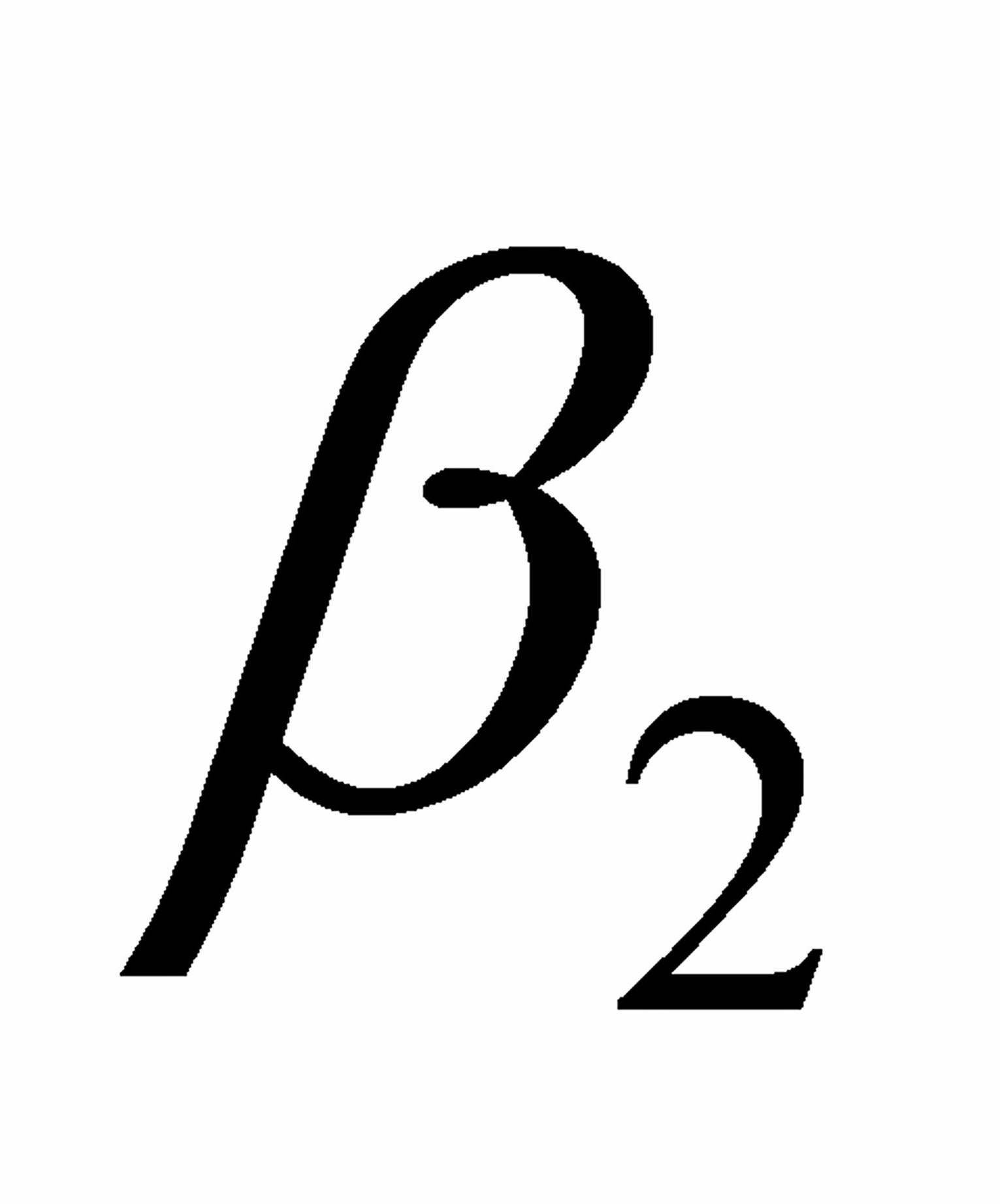 反映的是( )
反映的是( )
B. 由于Y的变化引起的X的线性变化部分
C. X变动一个单位时Y的平均变动量
D. Y变动一个单位时X的平均变动量
E. )
F. 7.2在回归模型
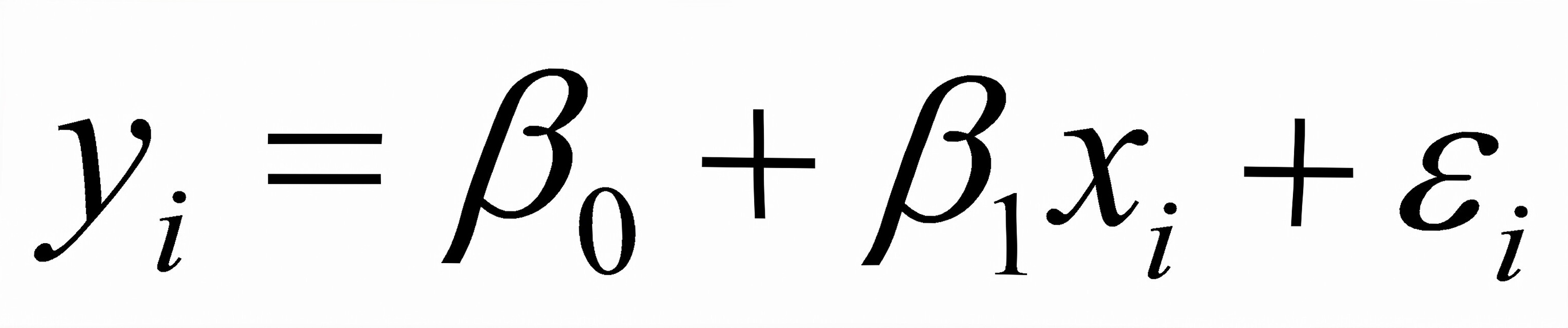 中,
中,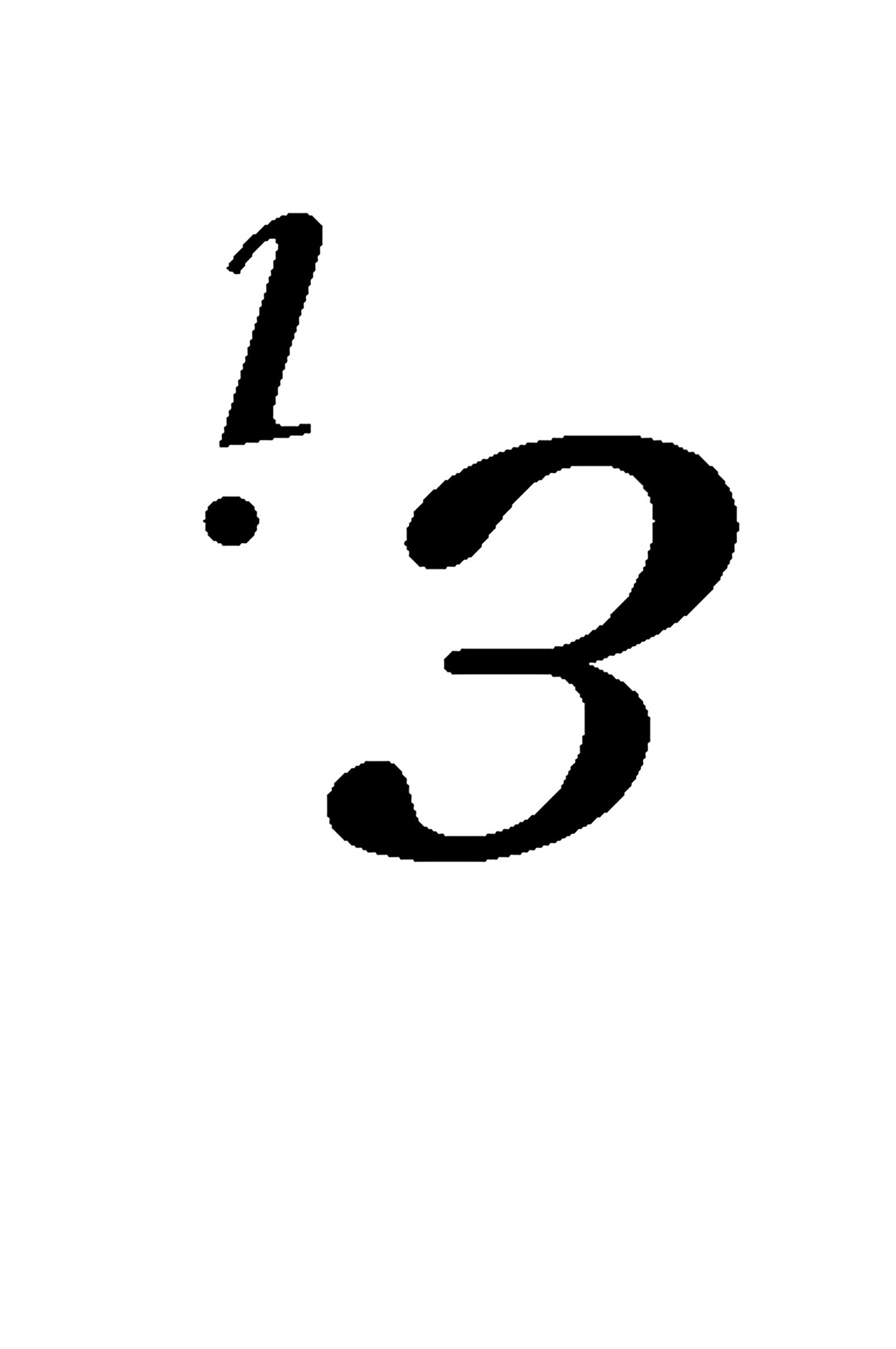 反映的是( )
反映的是( )G. 由于x的变化引起的Y的线性变化部分
由于Y的变化引起的X的线性变化部分
除了X和Y的线性关系之外的其他因素对Y的影响
由于X和Y的线性关系对Y的影响
)
7.3在用普通最小二乘法估计模型中参数时,要求模型满足一些基本假定,根本原因是( )
为了使回归方程更为简化,便于计算模型参数的估计值
为了便于确定所估计参数的均值
为了使估计的参数具有良好的统计性质,得出最佳线性无偏估计。
为了使因变量更容易控制,保证因变量和自变量有稳定的相关性
)
7.4在多元线性回归中,计算了可决系数后还要计算修正的可决系数,这是为了( )
可决系数的计算不很准确,需要加以修正。
便于比较自变量个数不同的模型的拟合程度。
为了使其与F检验结论一致。
为了不损失模型的自由度。
)
7.5利用回归模型作区间预测时, 因变量的预测区间的宽度( )。
随自变量X 的值增大而增大
随自变量X 的值增大而缩小
在
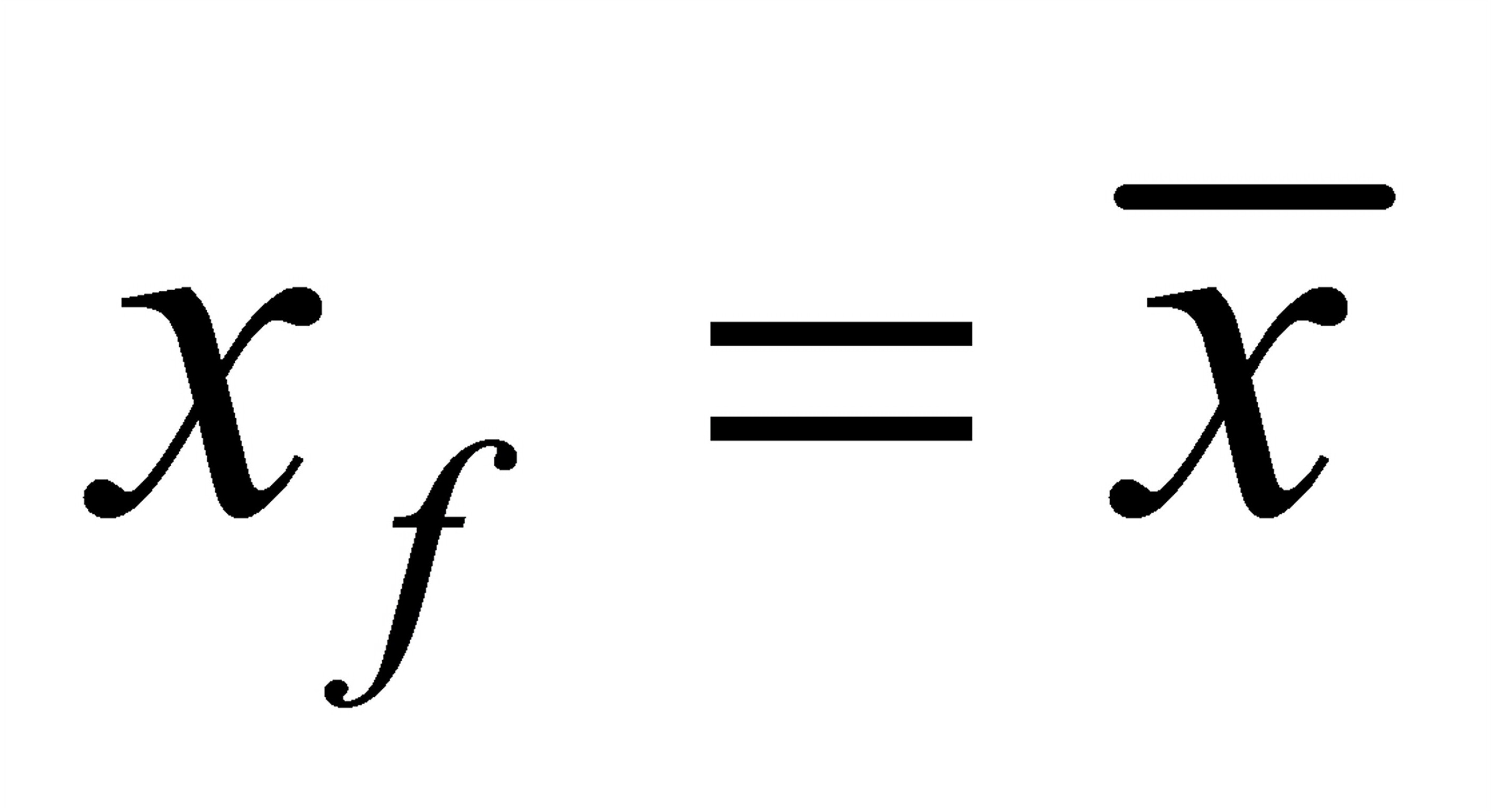 处最小
处最小在
处最大)
判断题
7.1样本容量为n=35,作两个回归模型:
模型1:
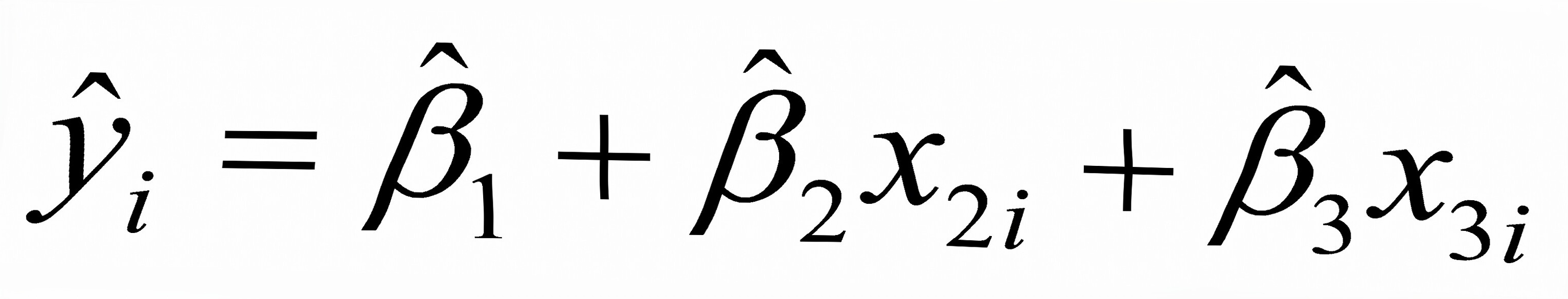 ,可决系数为
,可决系数为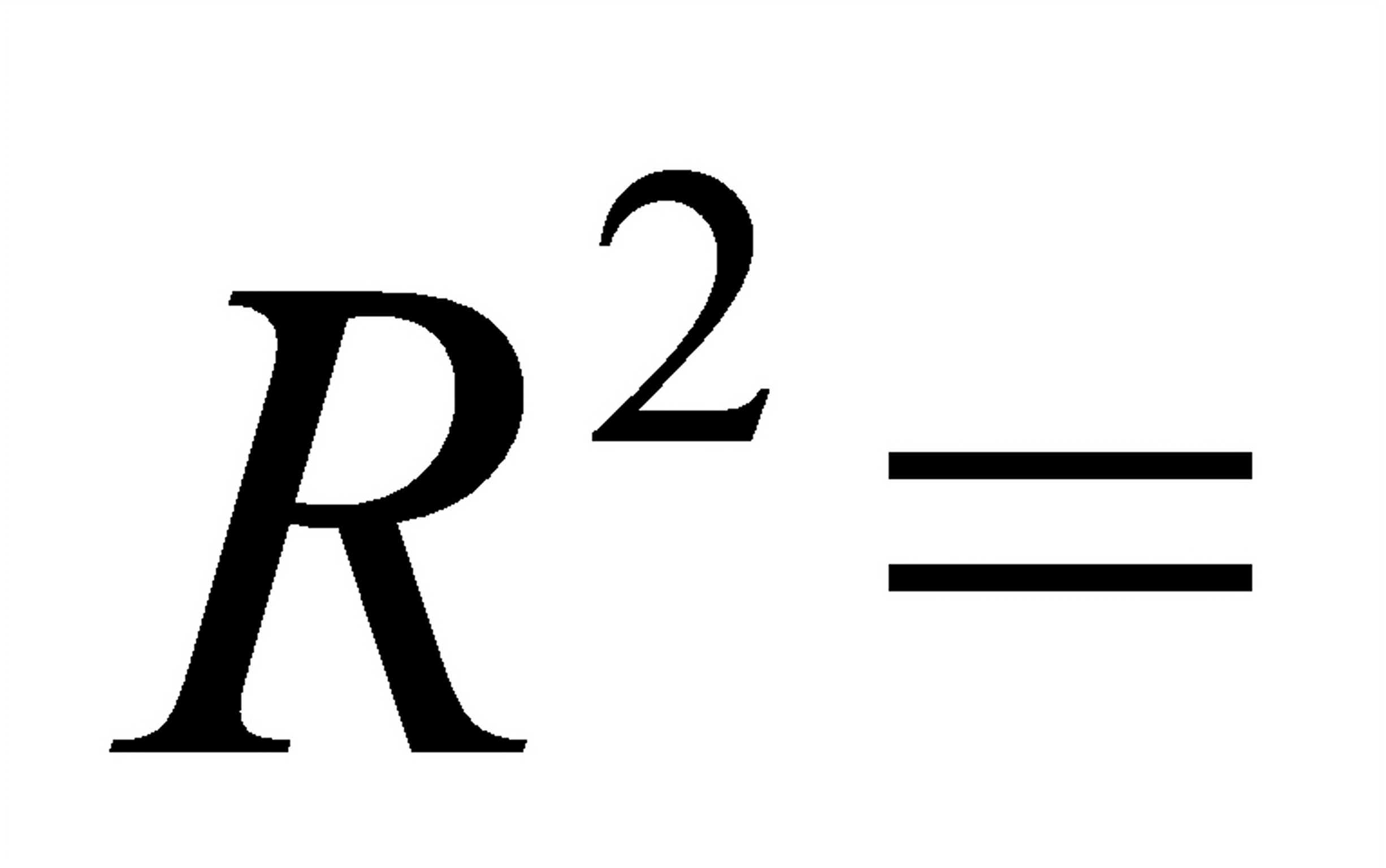 0.8850;
0.8850;模型2:
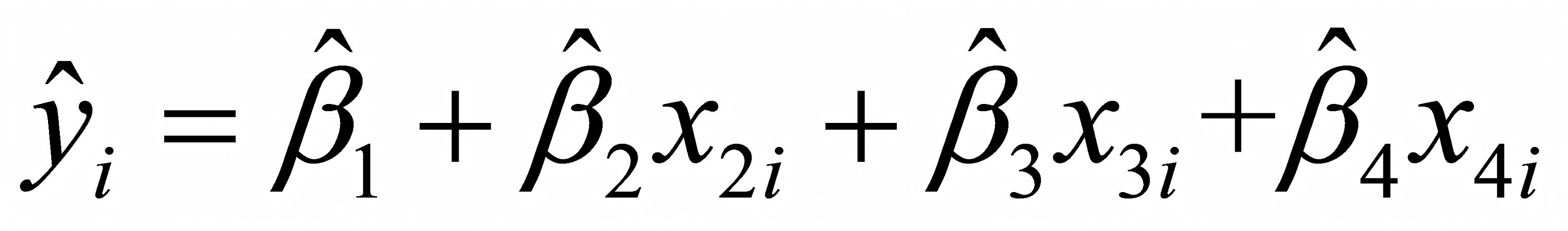 ,可决系数为0.9012。
,可决系数为0.9012。因为模型2的可决系数大于模型1 ,所以模型2比模型1的拟合优度更好。
判断:( )
参考答:判断:(错)
原因:由于在样本容量一定的条件下,总离差平方和与自变量的个数无关,而残差平方和会随着模型中自变量个数的增加而减少,至少不会增加。也就是说,随着模型中自变量的增加,多重可决系数
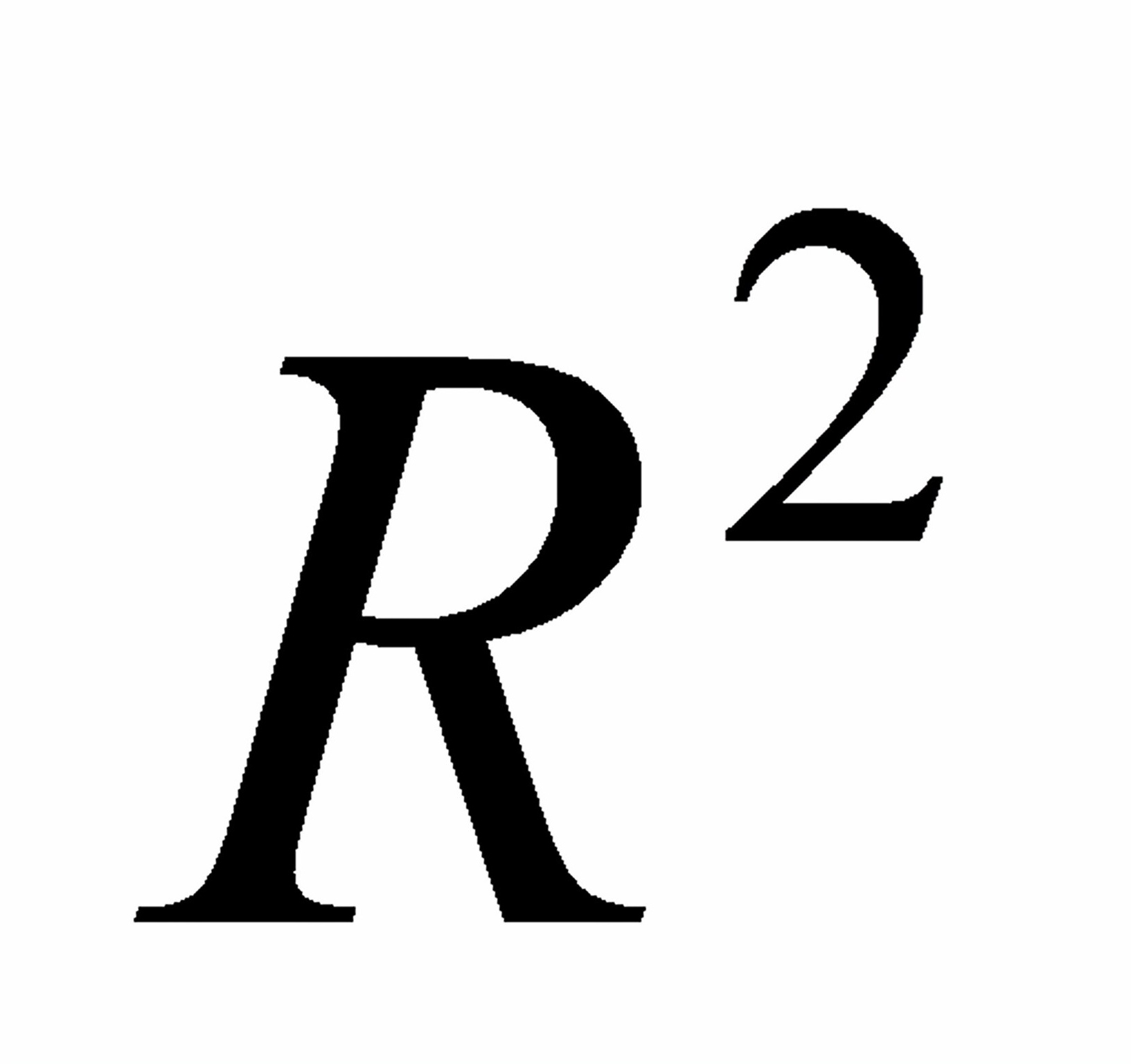 会随着自变量个数增加而增大。因此,多元线性回归模型中,在比较因变量相同而自变量个数不同的模型的拟合程度时,不能简单地对比多重可决系数。在样本容量一定的情况下,增加自变量必定使得待估参数的个数增加,从而损失自由度;而且在实际应用中,有时所增加的自变量并非必要。为此,需要用自由度去修正多重可决系数中的残差平方和与回归平方和,引入修正的可决系数。
会随着自变量个数增加而增大。因此,多元线性回归模型中,在比较因变量相同而自变量个数不同的模型的拟合程度时,不能简单地对比多重可决系数。在样本容量一定的情况下,增加自变量必定使得待估参数的个数增加,从而损失自由度;而且在实际应用中,有时所增加的自变量并非必要。为此,需要用自由度去修正多重可决系数中的残差平方和与回归平方和,引入修正的可决系数。7.2在回归模型参数估计方法的基本假定中,涉及对随机误差项
分布性质的假定,但是随机误差项是未知的,在具体作回归分时不必考虑其分布。判断:( )参考答:判断:( 错 )
原因: ①只有具备一定的假定条件,对模型所作出的估计才可能具有良好的统计性质,所估计的参数才能"尽可能地接近"(即"尽可能准确地估计")参数的真实值。在普通最小二乘估计的统计性质的证明中,基本假定中关于随机误差项
的分布性质是必备的条件。也就是说如果基本假定不成立,参数估计的无偏性、有效性或者一致性也就不一定成立。通过对高斯定理的数学证明能深刻体会到。②因为模型中有随机扰动项,所估计的参数也是随机变量,显然参数估计量的分布与随机扰动项的分布有关,只有对随机扰动项的分布作出某些假定,才能比较方便地确定参数估计量的分布性质,才可能在此基础上去对参数进行假设检验和区间估计等统计推断,也才可能对因变量作区间预测。
7.3回归模型参数估计方法的基本假定主要应用于数学证明,在具体作回归分时不必考虑基本假定。判断:( )
参考答:判断:( 错 )
原因: ①只有具备一定的假定条件,对模型所作出的估计才可能具有良好的统计性质。所估计的参数才能"尽可能地接近"(即"尽可能准确地估计")参数的真实值。在普通最小二乘估计的统计性质的证明中,基本假定是必备的条件。也就是说如果基本假定不成立,参数估计的无偏性、有效性或者一致性也就不一定成立。通过对高斯定理的数学证明能深刻体会到。
②因为模型中有随机扰动项,所估计的参数也是随机变量,显然参数估计量的分布与随机扰动项的分布有关,只有对随机扰动项的分布作出某些假定,才能比较方便地确定参数估计量的分布性质,才可能在此基础上去对参数进行假设检验和区间估计等统计推断,也才可能对因变量作区间预测。
Y作区间预测,可以得到可靠的预测结果。
判断:( )
参考答:判断(错)
原因:利用回归模型对自变量的预测区间不是常数。预测区间的上下限与以下因素有关:
因为预测区间是
①样本容量n越小,预测区间将越大,
②样本容量越小,
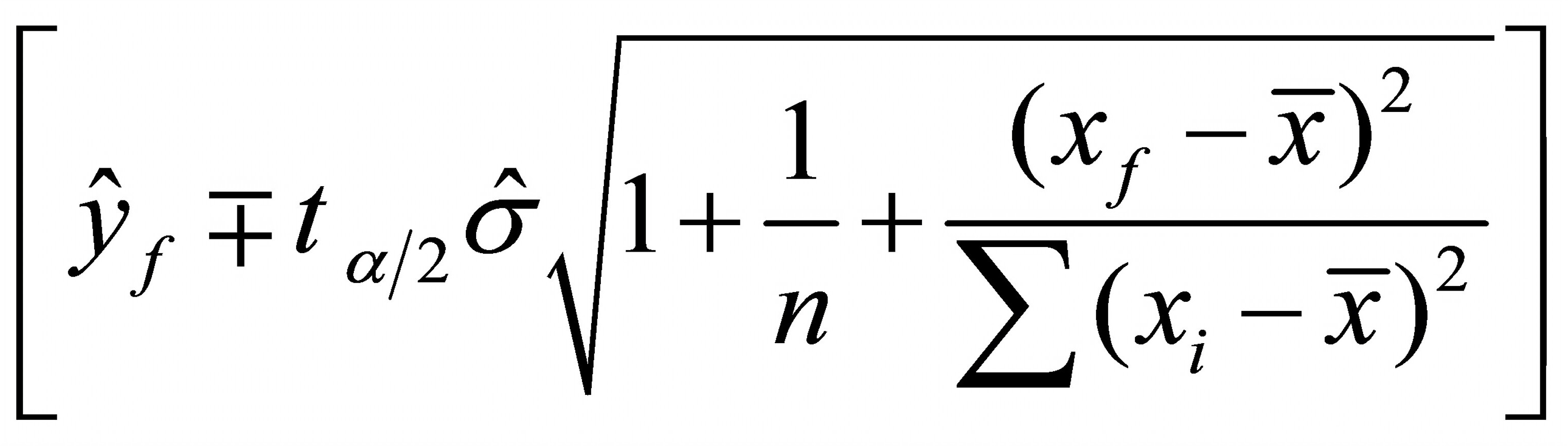 也越小,预测区间则越大;
也越小,预测区间则越大;③随
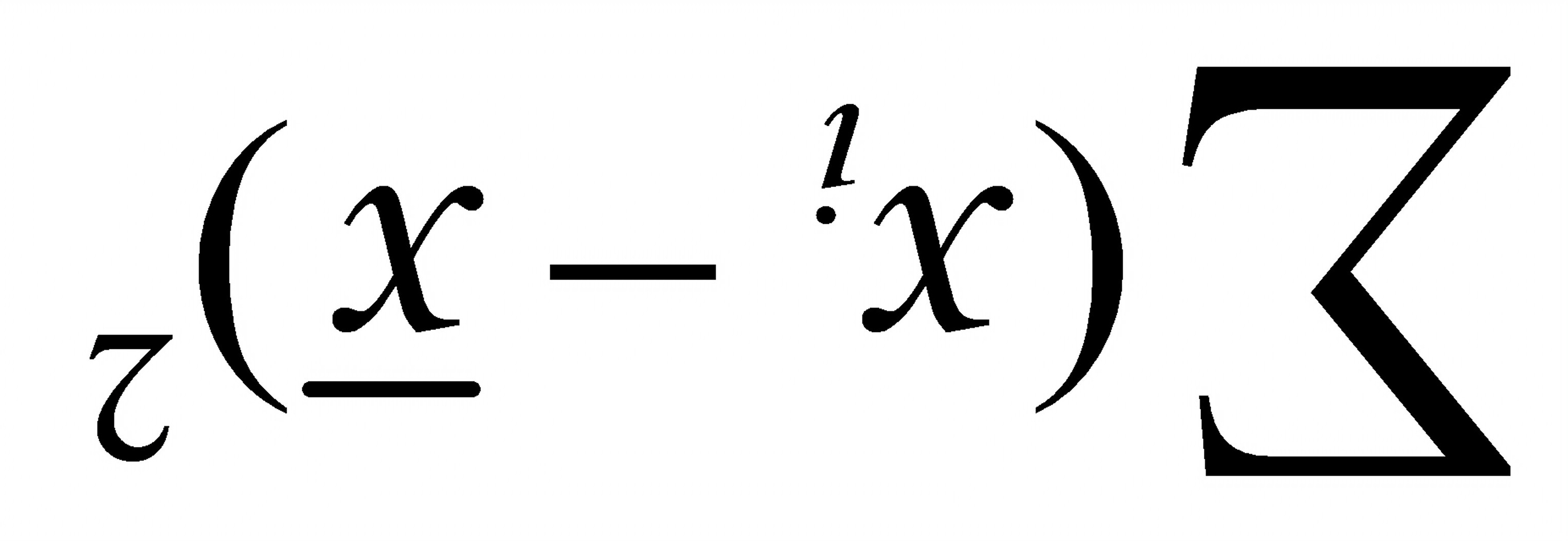 的变化而变化,当
的变化而变化,当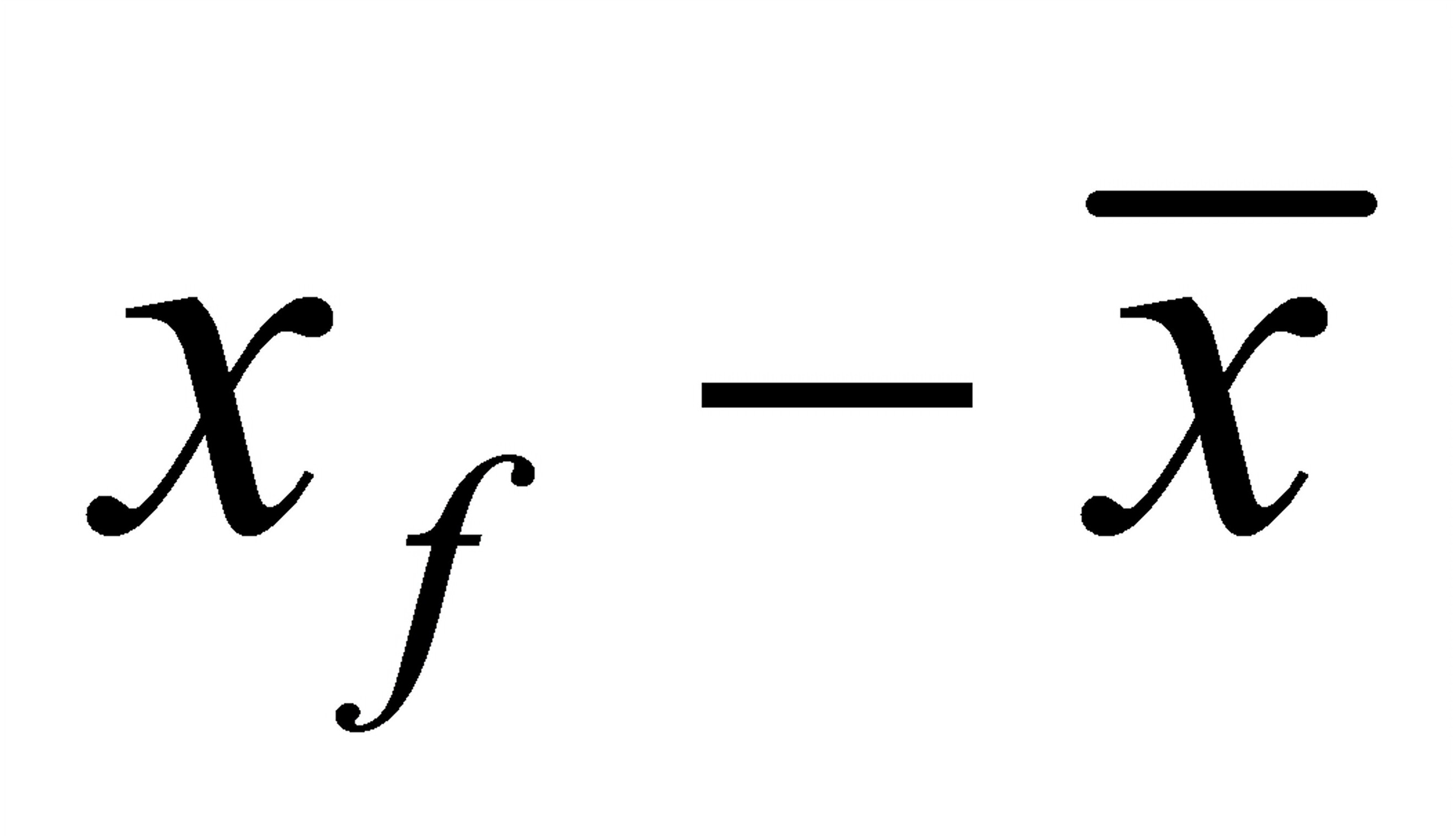 时,预测区间最小,随着对
时,预测区间最小,随着对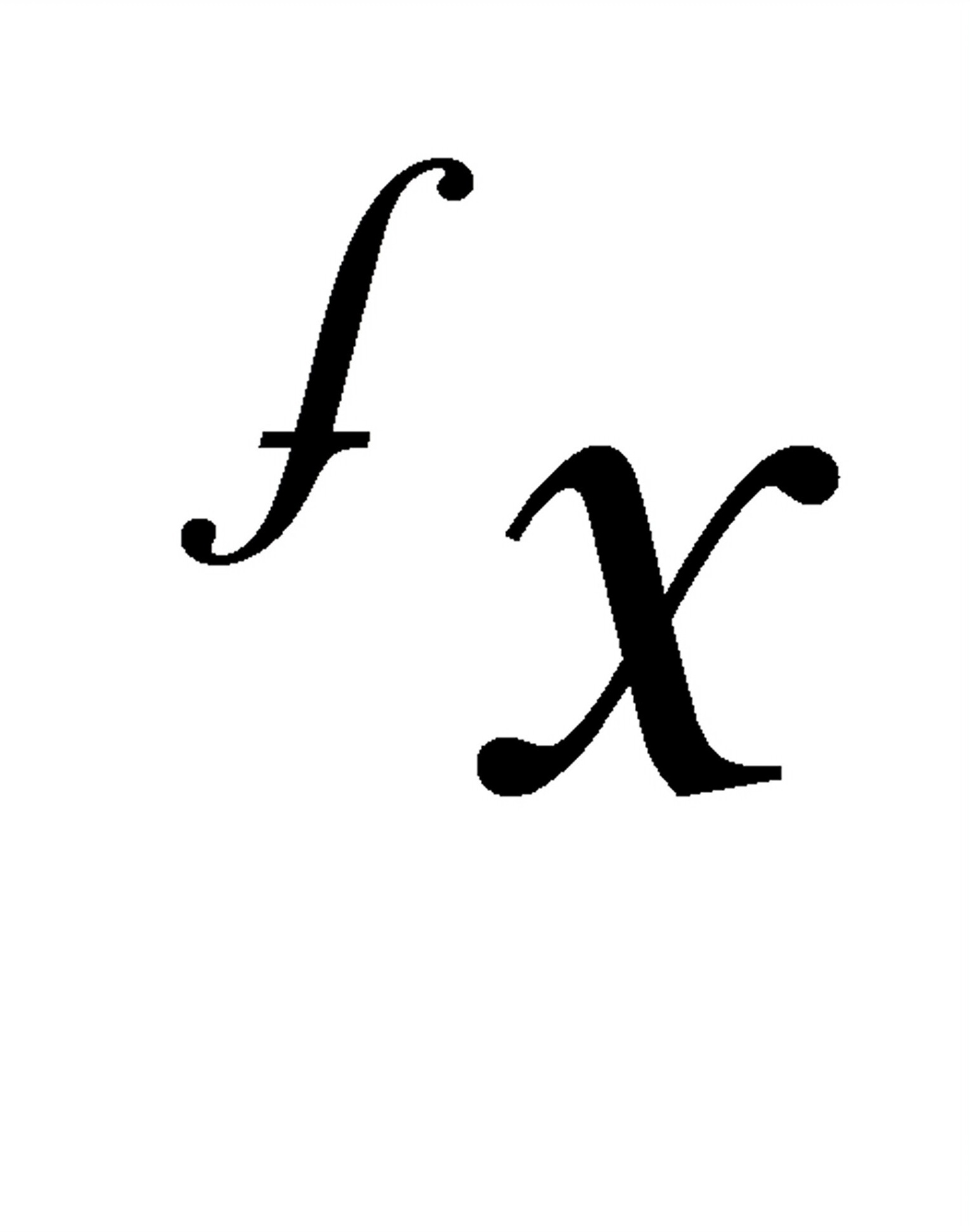 的愈加偏离,预测区间将愈宽。
的愈加偏离,预测区间将愈宽。本例中,2000年—2010年样本容量为n=11;
 =6,预测期2020年的序号21,=21-6=15。
=6,预测期2020年的序号21,=21-6=15。本例中样本容量较小,预测区间较大;此外,本例的预测期偏离样本期的
过远,较大,此时预测区间将会很宽,预测的可靠性会非常低。检验与t 检验是两种完全不同的检验,在一元回归分
中,对模型的F检验已得到F=155.11,P值为3.66E-13,为了检验自变量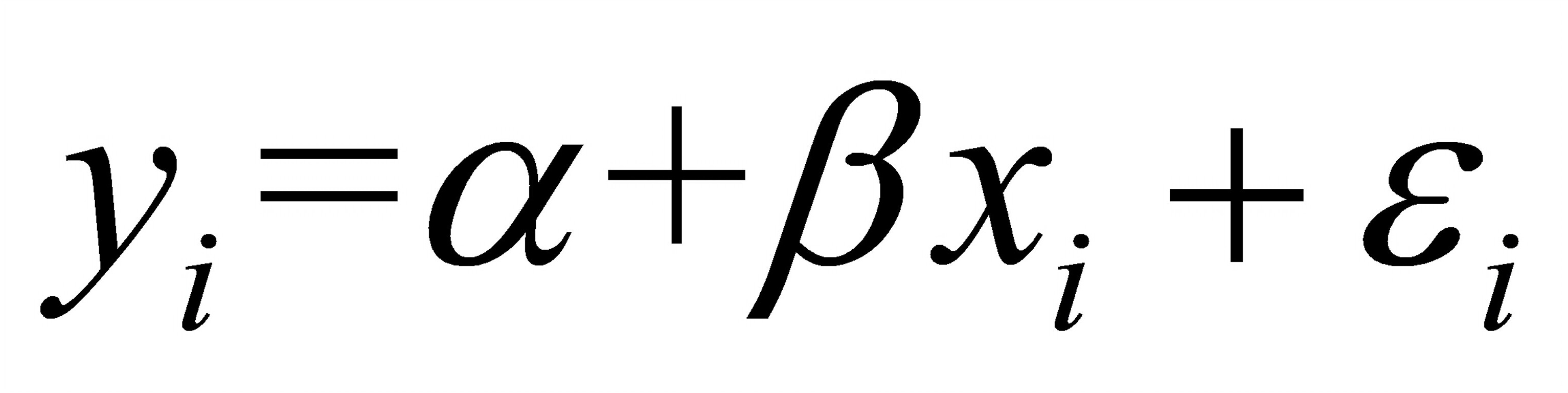 的显著性,还必须作t检验。判断( )
的显著性,还必须作t检验。判断( )参考答案:判断(错)
检验。事实上,在一元回归情形下容易证明F=t2,F检验与t检验是等价的。所以已经有F检验显著的结论,就不是必须再作t 检验。
7.6 一项对多个国家心脏病死亡率与市场葡萄酒销售量回归分的研究表明,市场葡萄酒销售量上升有助于降低心脏病死亡率,这就是说每个人只要多喝葡萄酒就都会降低心脏病死亡的风险。判断( )
参考答案:判断(错)
原因:回归分的本质是关于一个变量(因变量)对另一个或另外多个变量(自变量)依存关系的研究,是用适当的回归模型去近似地表达或估计变量之间的平均变化关系,也就是要根据自变量的固定值去估计和预测因变量的平均值。虽然从平均意义上说,市场葡萄酒销售量上升有利于有助于降低心脏病死亡率,但是并不是对每个个人都是这样。
题目解答
答案
参考答( C ) 参考答( C ) 参考答( C ) 参考答( B ) 参考答( C ) 参考 答 : 判断: (错) 原因: 参考 判断: ( 错 ) 原因: 参考答 : 判断: ( 错 ) 原因: 参考 答 : 判断(错) 原因: 参考答案 : 判断(错) 原因 : 参考答案 : 判断(错) 原因: