随机变量的数字特征利用分布函数或分布密度函数可以完全确定一个随机变量,但在实际问题中求分布函数或分布密度函数不仅十分困难,而且常常没有必要。例如:测量零件的长度得到了一系列的观测值,人们往往只需要知道零件长度这个随机变量的一些特征量就够了,诸如长度的平均值(近似地代表长度的真值)及测量标准(偏]差(观测值对平均值的分散程度)。用一些数字来描述随机变量的主要特征,显然十分方便、直观、实用,在概率论和数理统计中就称它们为随机变量的数字特征。这些特征量有数学期望、方差、矩等。(1)数学期望随机变量X的数学期望值记为E(X)或简记为段,用它可以表示随机变量本身的大小,说明X的取值中心或在数轴上的位置,也称期望值。数学期望表征随机变量分布的中心位置,随机变量围绕着数学期望取值。数学期望的估计值,即为若干个测量结果或一系列观测值的算术平均值。也就是说数学期望是一个平均的大约数值,随机变量的所有可能值围绕着它而变化。①离散型随机变量的数学期望设某机械加工车间有M台机床,它们时而工作时而停顿(如为了调换刀具、零件和进行测量等),为了精确估计车间的电力负荷,需要知道同时工作着的机床的台数。为此作了 N次观察,记下诸独立事件(所有机床都不工作,有1台工作,有2台工作,……,M台都工作)的出现次数分别为m0,m1,…,优M。显然,m0十ml+…+77zM=N,则该车间同时工作的机床的平均数i为overline (n)=dfrac (sum _{i=1)^n({x)_(i)}^n(m)_(i)}=overline (N),(x)_(i)dfrac ({m)_(i)}(N)=sum _(i=1)^n(x)_(i)式中:cUi表示zi台机床同时工作的频率。当N很大时,频率∞i趋于稳定而等于概率A,故有overline (n)=dfrac (sum _{i=1)^n({x)_(i)}^n(m)_(i)}=overline (N),(x)_(i)dfrac ({m)_(i)}(N)=sum _(i=1)^n(x)_(i)南卜所沭.本例中同时工作的机床台数X是一个随机变量,其可能值为overline (n)=dfrac (sum _{i=1)^n({x)_(i)}^n(m)_(i)}=overline (N),(x)_(i)dfrac ({m)_(i)}(N)=sum _(i=1)^n(x)_(i)本例中overline (n)=dfrac (sum _{i=1)^n({x)_(i)}^n(m)_(i)}=overline (N),(x)_(i)dfrac ({m)_(i)}(N)=sum _(i=1)^n(x)_(i)相应的概率为overline (n)=dfrac (sum _{i=1)^n({x)_(i)}^n(m)_(i)}=overline (N),(x)_(i)dfrac ({m)_(i)}(N)=sum _(i=1)^n(x)_(i),则其均值overline (n)=dfrac (sum _{i=1)^n({x)_(i)}^n(m)_(i)}=overline (N),(x)_(i)dfrac ({m)_(i)}(N)=sum _(i=1)^n(x)_(i)即称为随机变量的数学期望的估计值。它的一般形式为overline (n)=dfrac (sum _{i=1)^n({x)_(i)}^n(m)_(i)}=overline (N),(x)_(i)dfrac ({m)_(i)}(N)=sum _(i=1)^n(x)_(i)。而级数overline (n)=dfrac (sum _{i=1)^n({x)_(i)}^n(m)_(i)}=overline (N),(x)_(i)dfrac ({m)_(i)}(N)=sum _(i=1)^n(x)_(i)应绝对收敛。②连续型随机变量的数学期望设连续型随机变量X的分布密度函数为overline (n)=dfrac (sum _{i=1)^n({x)_(i)}^n(m)_(i)}=overline (N),(x)_(i)dfrac ({m)_(i)}(N)=sum _(i=1)^n(x)_(i)收敛,根据类似的定义,则X的数学期望为overline (n)=dfrac (sum _{i=1)^n({x)_(i)}^n(m)_(i)}=overline (N),(x)_(i)dfrac ({m)_(i)}(N)=sum _(i=1)^n(x)_(i)式中:overline (n)=dfrac (sum _{i=1)^n({x)_(i)}^n(m)_(i)}=overline (N),(x)_(i)dfrac ({m)_(i)}(N)=sum _(i=1)^n(x)_(i)表示随机变量X在任意一点z取值的概率。对于任意一个具有分布函数F(x)的随机变量X而言,则有overline (n)=dfrac (sum _{i=1)^n({x)_(i)}^n(m)_(i)}=overline (N),(x)_(i)dfrac ({m)_(i)}(N)=sum _(i=1)^n(x)_(i)因此,数学期望是均值这一概念在随机变量上的推广,它不是简单的算术平均值,而是以概率为权的加权平均值。(2)方差只用数学期望还不能充分描述一个随机变量。例如:对于测量而言,数学期望可用来表示被测量本身的大小,但是关于测量的可信程度或品质高低(比如各个测得值对数学期望的分散程度),就要用另一个特征量——方差来表示。下面以两种方法对某一量进行测量所得的测量结果(列于表5—1和表5—2)为例,看一下哪种方法更为可信或品质更高。表5—1 按方法I所得的测量结果 测量值 2829303132偏差绝对值 012 概率 0.10.150.50.150.1 概 率 0.50.30.2表5—2 按方法Ⅱ所得的测量结果注:①质量管理是各级管理者的职责,但必须由最高管理者领导。质量管理的实施涉及到组织中的所有成员。②在质量管理中要考虑到经济性因素。(3)质量控制quality control为达到质量要求所采取的作业技术和活动。注:①质量控制包括作业技术和活动,其目的在于监视过程并排除质量环中所有阶段中导致不满意的原因,以取得经济效益。②质量控制和质量保证的某些活动是相互关联的。(4)质量保证quality assurance为了提供足够的信任表明实体能够满足质量要求,而在质量体系中实施并根据需要进行证实的全部有计划和有系统的活动。注:①质量保证有内部和外部两种目的。A. 内部质量保证:在组织内部,质量保证向管理者提供信任。 B. 外部质量保证:在合同或其他情况下,质量保证向顾客或他方提供信任。 C. ②质量控制和质量保证的某些活动是相互关联的。 D. ③只有质量要求全面反映了用户的要求,质量保证才能提供足够的信任。 ’ E. lity system F. 为实施质量管理所需的组织结构、程序、过程和资源。 G. 注:①质量体系的内容应以满足质量目标的需要为准。 ②一个组织的质量体系,主要是为满足该组织内部管理的需要而设计的。它比特定 顾客的要求更为广泛。顾客仅仅评价质量体系中的有关部分。 ③为了合同或强制性质量评价的目的,可要求对已确定的质量体系要素的实施进行 证实。 nagement review 由最高管理者就质量方针和目标,对质量体系的现状和适应性进行的正式评价。 注:①管理评审可以包括质量方针评审。 ②质量审核的结果可作为管理评审的一种输入 ③“最高管理者”指的是其质量体系受到评审的组织的管理者。 ct review I的测量品质比表5—2方法Ⅱ要高。同时,也可以要看出它们的数学期望却是相等的,均为 overline (n)=dfrac (sum _{i=1)^n({x)_(i)}^n(m)_(i)}=overline (N),(x)_(i)dfrac ({m)_(i)}(N)=sum _(i=1)^n(x)_(i) (X)的偏差的平方的数学期望。它描述了随机变量X对数学期望E(X)的分散程度,即 overline (n)=dfrac (sum _{i=1)^n({x)_(i)}^n(m)_(i)}=overline (N),(x)_(i)dfrac ({m)_(i)}(N)=sum _(i=1)^n(x)_(i) ①离散型随机变量的方差 overline (n)=dfrac (sum _{i=1)^n({x)_(i)}^n(m)_(i)}=overline (N),(x)_(i)dfrac ({m)_(i)}(N)=sum _(i=1)^n(x)_(i) 对于上述的测量实例,由表中的数据可以算出方差为 I overline (n)=dfrac (sum _{i=1)^n({x)_(i)}^n(m)_(i)}=overline (N),(x)_(i)dfrac ({m)_(i)}(N)=sum _(i=1)^n(x)_(i) 按测量方法Ⅱ overline (n)=dfrac (sum _{i=1)^n({x)_(i)}^n(m)_(i)}=overline (N),(x)_(i)dfrac ({m)_(i)}(N)=sum _(i=1)^n(x)_(i) 由此可知,若方差小,各测得值对其均值的分散程度就小,则在不考虑系统效应情况下其测量品质高,或更为可信、有效。 ②连续型随机变量的方差 overline (n)=dfrac (sum _{i=1)^n({x)_(i)}^n(m)_(i)}=overline (N),(x)_(i)dfrac ({m)_(i)}(N)=sum _(i=1)^n(x)_(i) (X)的量纲是随机变量X量纲的平方。为了更为实用和易于理解起见,最好用与随机变量同量纲的量来说明或表述分散性,故将方差开方取正值得 overline (n)=dfrac (sum _{i=1)^n({x)_(i)}^n(m)_(i)}=overline (N),(x)_(i)dfrac ({m)_(i)}(N)=sum _(i=1)^n(x)_(i) 式中盯,可简记为口,称为测量列的标准差,亦称标准偏差或均方根偏差。
随机变量的数字特征
利用分布函数或分布密度函数可以完全确定一个随机变量,但在实际问题中求分布函数或分布密度函数不仅十分困难,而且常常没有必要。例如:测量零件的长度得到了一系列的观测值,人们往往只需要知道零件长度这个随机变量的一些特征量就够了,诸如长度的平均值(近似地代表长度的真值)及测量标准(偏]差(观测值对平均值的分散程度)。用一些数字来描述随机变量的主要特征,显然十分方便、直观、实用,在概率论和数理统计中就称它们为随机变量的数字特征。这些特征量有数学期望、方差、矩等。
(1)数学期望
随机变量X的数学期望值记为E(X)或简记为段,用它可以表示随机变量本身的大小,说明X的取值中心或在数轴上的位置,也称期望值。数学期望表征随机变量分布的中心位置,随机变量围绕着数学期望取值。数学期望的估计值,即为若干个测量结果或一系列观测值的算术平均值。也就是说数学期望是一个平均的大约数值,随机变量的所有可能值围绕着它而变化。
①离散型随机变量的数学期望
设某机械加工车间有M台机床,它们时而工作时而停顿(如为了调换刀具、零件和进行测量等),为了精确估计车间的电力负荷,需要知道同时工作着的机床的台数。为此作了 N次观察,记下诸独立事件(所有机床都不工作,有1台工作,有2台工作,……,M台都工作)的出现次数分别为m0,m1,…,优M。显然,m0十ml+…+77zM=N,则该车间同时工作的机床的平均数i为
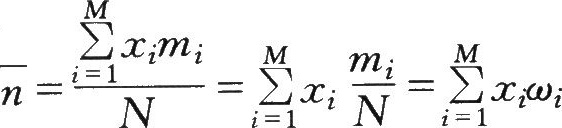
式中:cUi表示zi台机床同时工作的频率。当N很大时,频率∞i趋于稳定而等于概率A,故有
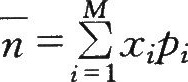
南卜所沭.本例中同时工作的机床台数X是一个随机变量,其可能值为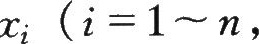
本例中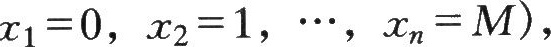 相应的概率为
相应的概率为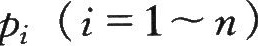 ,则其均值
,则其均值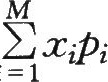
即称为随机变量的数学期望的估计值。它的一般形式为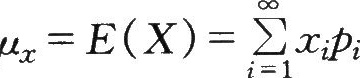
。而级数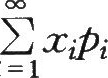 应绝对收敛。
应绝对收敛。
②连续型随机变量的数学期望
设连续型随机变量X的分布密度函数为
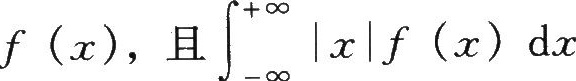
收敛,根据类似
的定义,则X的数学期望为
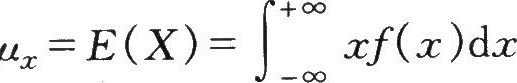
式中:
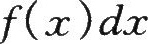
表示随机变量X在任意一点z取值的概率。
对于任意一个具有分布函数F(x)的随机变量X而言,则有
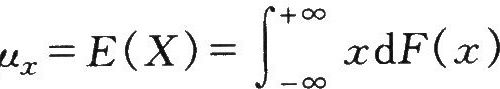
因此,数学期望是均值这一概念在随机变量上的推广,它不是简单的算术平均值,而是以概率为权的加权平均值。
(2)方差
只用数学期望还不能充分描述一个随机变量。例如:对于测量而言,数学期望可用来表示被测量本身的大小,但是关于测量的可信程度或品质高低(比如各个测得值对数学期望的分散程度),就要用另一个特征量——方差来表示。下面以两种方法对某一量进行测量所得的测量结果(列于表5—1和表5—2)为例,看一下哪种方法更为可信或品质更高。
表5—1 按方法I所得的测量结果
测量值
2829303132
偏差绝对值
012
概率
0.10.150.50.150.1
概 率
0.50.30.2
表5—2 按方法Ⅱ所得的测量结果
注:①质量管理是各级管理者的职责,但必须由最高管理者领导。质量管理的实施涉及
到组织中的所有成员。
②在质量管理中要考虑到经济性因素。
(3)质量控制quality control
为达到质量要求所采取的作业技术和活动。
注:①质量控制包括作业技术和活动,其目的在于监视过程并排除质量环中所有阶段中
导致不满意的原因,以取得经济效益。
②质量控制和质量保证的某些活动是相互关联的。
(4)质量保证quality assurance
为了提供足够的信任表明实体能够满足质量要求,而在质量体系中实施并根据需要进行
证实的全部有计划和有系统的活动。
注:①质量保证有内部和外部两种目的。
A. 内部质量保证:在组织内部,质量保证向管理者提供信任。B. 外部质量保证:在合同或其他情况下,质量保证向顾客或他方提供信任。
C. ②质量控制和质量保证的某些活动是相互关联的。
D. ③只有质量要求全面反映了用户的要求,质量保证才能提供足够的信任。 ’
E. lity system
F. 为实施质量管理所需的组织结构、程序、过程和资源。
G. 注:①质量体系的内容应以满足质量目标的需要为准。
②一个组织的质量体系,主要是为满足该组织内部管理的需要而设计的。它比特定
顾客的要求更为广泛。顾客仅仅评价质量体系中的有关部分。
③为了合同或强制性质量评价的目的,可要求对已确定的质量体系要素的实施进行
证实。
nagement review
由最高管理者就质量方针和目标,对质量体系的现状和适应性进行的正式评价。
注:①管理评审可以包括质量方针评审。
②质量审核的结果可作为管理评审的一种输入
③“最高管理者”指的是其质量体系受到评审的组织的管理者。
ct review
I的测量品质比表5—2方法Ⅱ要高。同时,也可以要看出它们的数学期望却是相等的,均为
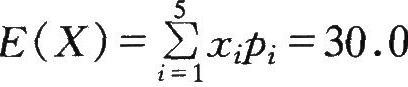
(X)的偏差的平方的数学期望。它描述了随机变量X对数学期望E(X)的分散程度,即
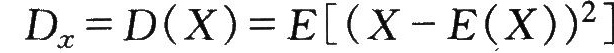
①离散型随机变量的方差
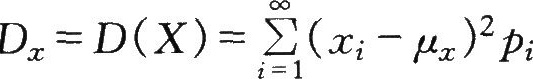
对于上述的测量实例,由表中的数据可以算出方差为
I
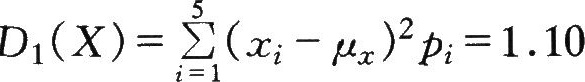
按测量方法Ⅱ
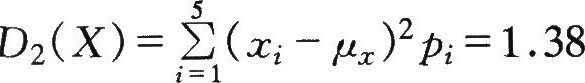
由此可知,若方差小,各测得值对其均值的分散程度就小,则在不考虑系统效应情况下其测量品质高,或更为可信、有效。
②连续型随机变量的方差
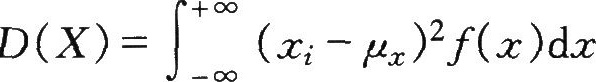
(X)的量纲是随机变量X量纲的平方。为了更为实用和易于理解起见,最好用与随机变量同量纲的量来说明或表述分散性,故将方差开方取正值得
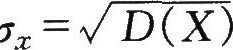
式中盯,可简记为口,称为测量列的标准差,亦称标准偏差或均方根偏差。
题目解答
答案
5)质量体系quality system 为实施质量管理所需的组织结构、程序、过程和资源。 注:①质量体系的内容应以满足质量 目标的需要为准。 ②一个组织的质量体系,主要是为满足该组织内部管理的需要而设计的。它比特定 顾客的要求更为广泛。顾客仅仅评价质量体系中的有关部分。 ③为了合同或强制性质量评价的目的,可要求对已确定的质量体系要素的实施进行 证实。 (6)管理评审management review 由最高管理者就质量方针和目标,对质量体系的现状和适应性进行的正式评价 。 注: ①管理评审可以包括质量方针评审。 ②质量审核的结果可作为管理评审的一种输入 ③“最高管理者” 指的是其质量体系受到评审的组织的管理者。 (7)合同评审contract review