题目
从某地难产儿中随机抽取20名新生儿进行研究, 得平均体重为 20 , 该地新生儿的平均体重为20, 为了解该地难产儿和一般新生儿出生体重有无差别, 选取( )合适。A. 单样本20检验B. 配对样本均数 20 检验C. 两独立样本均数比较的20 检验D. 20检验
从某地难产儿中随机抽取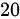 名新生儿进行研究, 得平均体重为
名新生儿进行研究, 得平均体重为 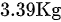 , 该地新生儿的平均体重为
, 该地新生儿的平均体重为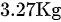 , 为了解该地难产儿和一般新生儿出生体重有无差别, 选取( )合适。
, 为了解该地难产儿和一般新生儿出生体重有无差别, 选取( )合适。
A. 单样本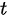 检验
检验
B. 配对样本均数 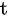 检验
检验
C. 两独立样本均数比较的 检验
D. 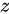 检验
检验
题目解答
答案
首先,我们需要明确题目中的研究背景和目的。题目中给出了某地难产儿的平均体重和该地一般新生儿的平均体重,并询问为了解该地难产儿和一般新生儿出生体重有无差别,应该选取哪种统计方法。
接下来,我们逐一分析选项:
A. 单样本检验:这种检验通常用于检验一个样本的均值是否与已知的某个总体均值有显著差异。但在这里,我们有两个不同的样本(难产儿和一般新生儿),所以单样本检验不适用。
B. 配对样本均数检验:这种检验通常用于检验两个样本(通常是同一组对象在不同时间或条件下的测量值)的均值是否有显著差异。但在这里,难产儿和一般新生儿是两个不同的群体,不是配对样本,所以配对样本均数t检验不适用。
C. 两独立样本均数比较的t检验:这种检验正是用于检验两个独立样本的均值是否有显著差异。在这里,难产儿和一般新生儿是两个独立的群体,所以两独立样本均数比较的检验是合适的。
D. 检验:检验通常用于大样本(通常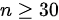 )的情况,并且要求数据服从正态分布。但在这里,我们只知道样本量
)的情况,并且要求数据服从正态分布。但在这里,我们只知道样本量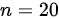 ,并且没有给出数据分布的信息,所以检验可能不适用。
,并且没有给出数据分布的信息,所以检验可能不适用。
综上所述,为了解该地难产儿和一般新生儿出生体重有无差别,应该选取两独立样本均数比较的t检验。
故答案为:C. 两独立样本均数比较的t检验。
解析
步骤 1:理解问题背景
题目中提到从某地难产儿中随机抽取20名新生儿进行研究,得到平均体重为3.39Kg,而该地新生儿的平均体重为3.27Kg。目的是了解该地难产儿和一般新生儿出生体重有无差别。
步骤 2:分析选项
A. 单样本检验:单样本检验用于检验一个样本的均值是否与已知的某个总体均值有显著差异。但在这里,我们有两个不同的样本(难产儿和一般新生儿),所以单样本检验不适用。
B. 配对样本均数检验:配对样本均数检验通常用于检验两个样本(通常是同一组对象在不同时间或条件下的测量值)的均值是否有显著差异。但在这里,难产儿和一般新生儿是两个不同的群体,不是配对样本,所以配对样本均数t检验不适用。
C. 两独立样本均数比较的t检验:两独立样本均数比较的t检验用于检验两个独立样本的均值是否有显著差异。在这里,难产儿和一般新生儿是两个独立的群体,所以两独立样本均数比较的检验是合适的。
D. 检验:检验通常用于大样本(通常$n\geqslant 30$)的情况,并且要求数据服从正态分布。但在这里,我们只知道样本量n=20,并且没有给出数据分布的信息,所以检验可能不适用。
步骤 3:选择合适的统计方法
根据上述分析,为了解该地难产儿和一般新生儿出生体重有无差别,应该选取两独立样本均数比较的t检验。
题目中提到从某地难产儿中随机抽取20名新生儿进行研究,得到平均体重为3.39Kg,而该地新生儿的平均体重为3.27Kg。目的是了解该地难产儿和一般新生儿出生体重有无差别。
步骤 2:分析选项
A. 单样本检验:单样本检验用于检验一个样本的均值是否与已知的某个总体均值有显著差异。但在这里,我们有两个不同的样本(难产儿和一般新生儿),所以单样本检验不适用。
B. 配对样本均数检验:配对样本均数检验通常用于检验两个样本(通常是同一组对象在不同时间或条件下的测量值)的均值是否有显著差异。但在这里,难产儿和一般新生儿是两个不同的群体,不是配对样本,所以配对样本均数t检验不适用。
C. 两独立样本均数比较的t检验:两独立样本均数比较的t检验用于检验两个独立样本的均值是否有显著差异。在这里,难产儿和一般新生儿是两个独立的群体,所以两独立样本均数比较的检验是合适的。
D. 检验:检验通常用于大样本(通常$n\geqslant 30$)的情况,并且要求数据服从正态分布。但在这里,我们只知道样本量n=20,并且没有给出数据分布的信息,所以检验可能不适用。
步骤 3:选择合适的统计方法
根据上述分析,为了解该地难产儿和一般新生儿出生体重有无差别,应该选取两独立样本均数比较的t检验。