题目
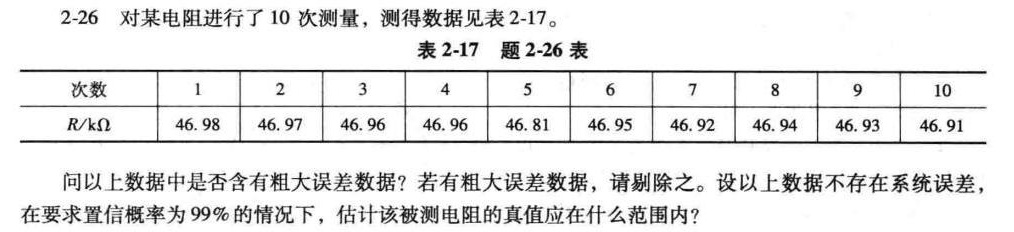
2-26 对某电阻进行了10次测量,测得数据见表 -17-|||-表 2-17 题 2-26 表-|||-次数 1 2 3 4 5 6 7 8 9 10-|||-R/kΩ 46.98 46.97 46.96 46.96 46.81 46.95 46.92 46.94 46.93 46.91-|||-问以上数据中是否含有粗大误差数据?若有粗大误差数据,请剔除之。设以上数据不存在系统误差,-|||-在要求置信概率为99%的情况下,估计该被测电阻的真值应在什么范围内?
题目解答
答案
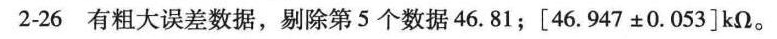
解析
步骤 1:计算平均值
首先,计算所有测量值的平均值。平均值计算公式为:
$$
\bar{R} = \frac{1}{n} \sum_{i=1}^{n} R_i
$$
其中,$n$ 是测量次数,$R_i$ 是第 $i$ 次测量值。将表中的数据代入公式计算平均值。
步骤 2:计算标准偏差
计算标准偏差,公式为:
$$
s = \sqrt{\frac{1}{n-1} \sum_{i=1}^{n} (R_i - \bar{R})^2}
$$
其中,$s$ 是标准偏差,$\bar{R}$ 是平均值。将表中的数据代入公式计算标准偏差。
步骤 3:判断粗大误差
根据格拉布斯准则,判断是否存在粗大误差。格拉布斯准则的公式为:
$$
G = \frac{|R_{max} - \bar{R}|}{s}
$$
其中,$G$ 是格拉布斯统计量,$R_{max}$ 是最大测量值。将表中的数据代入公式计算格拉布斯统计量。如果 $G$ 大于临界值,则认为存在粗大误差。
步骤 4:剔除粗大误差数据
如果存在粗大误差数据,将其剔除,并重新计算平均值和标准偏差。
步骤 5:计算置信区间
根据置信概率为99%,计算置信区间。置信区间的公式为:
$$
\bar{R} \pm t_{\alpha/2} \cdot \frac{s}{\sqrt{n}}
$$
其中,$t_{\alpha/2}$ 是t分布的临界值,$\alpha$ 是显著性水平,$n$ 是测量次数。将表中的数据代入公式计算置信区间。
首先,计算所有测量值的平均值。平均值计算公式为:
$$
\bar{R} = \frac{1}{n} \sum_{i=1}^{n} R_i
$$
其中,$n$ 是测量次数,$R_i$ 是第 $i$ 次测量值。将表中的数据代入公式计算平均值。
步骤 2:计算标准偏差
计算标准偏差,公式为:
$$
s = \sqrt{\frac{1}{n-1} \sum_{i=1}^{n} (R_i - \bar{R})^2}
$$
其中,$s$ 是标准偏差,$\bar{R}$ 是平均值。将表中的数据代入公式计算标准偏差。
步骤 3:判断粗大误差
根据格拉布斯准则,判断是否存在粗大误差。格拉布斯准则的公式为:
$$
G = \frac{|R_{max} - \bar{R}|}{s}
$$
其中,$G$ 是格拉布斯统计量,$R_{max}$ 是最大测量值。将表中的数据代入公式计算格拉布斯统计量。如果 $G$ 大于临界值,则认为存在粗大误差。
步骤 4:剔除粗大误差数据
如果存在粗大误差数据,将其剔除,并重新计算平均值和标准偏差。
步骤 5:计算置信区间
根据置信概率为99%,计算置信区间。置信区间的公式为:
$$
\bar{R} \pm t_{\alpha/2} \cdot \frac{s}{\sqrt{n}}
$$
其中,$t_{\alpha/2}$ 是t分布的临界值,$\alpha$ 是显著性水平,$n$ 是测量次数。将表中的数据代入公式计算置信区间。