下列关于相关系数的叙述,正确的有( )。A.是在线性相关条件下测定两个变量间相关关系密切程度的指标B.对相关性的判断带有较强的主观性C.是测定两个变量间是否独立的指标D.可以表明两个变量之间相关关系的方向E.可以体现两个变量之间相关关系的类型
下列关于相关系数的叙述,正确的有( )。
A.是在线性相关条件下测定两个变量间相关关系密切程度的指标
B.对相关性的判断带有较强的主观性
C.是测定两个变量间是否独立的指标
D.可以表明两个变量之间相关关系的方向
E.可以体现两个变量之间相关关系的类型
题目解答
答案
相关系数是在线性相关条件下测定两个变量间相关关系密切程度的指标。它是用数值来准确地衡量两个变量之间线性关系的紧密程度。例如,对于变量X和Y,相关系数r的取值范围是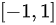 。当
。当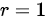 时,表示X和Y之间存在完全正线性相关;当
时,表示X和Y之间存在完全正线性相关;当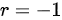 时,表示X和Y之间存在完全负线性相关;当
时,表示X和Y之间存在完全负线性相关;当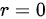 时,表示X和Y之间不存在线性相关关系。所以,选项A正确。
时,表示X和Y之间不存在线性相关关系。所以,选项A正确。
相关系数的计算是基于数据的客观计算,不是主观判断。它是根据样本数据通过特定的公式计算得出的,如对于样本数据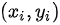 ,
,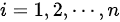 ,样本相关系数
,样本相关系数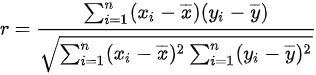 ,所以不是带有较强的主观性。所以,选项B错误。
,所以不是带有较强的主观性。所以,选项B错误。
相关系数不是测定两个变量是否独立的指标。两个变量独立意味着它们的联合概率等于各自概率的乘积,而相关系数为0只是说明不存在线性相关关系,但变量之间可能存在其他非线性关系,所以不能简单地用相关系数来判断变量是否独立。所以,选项C错误。
相关系数可以表明两个变量之间相关关系的方向。当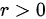 0" data-width="46" data-height="19" data-size="674" data-format="png" style="">时,表明两个变量是正相关关系,即一个变量增加,另一个变量也倾向于增加;当
0" data-width="46" data-height="19" data-size="674" data-format="png" style="">时,表明两个变量是正相关关系,即一个变量增加,另一个变量也倾向于增加;当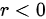 时,表明两个变量是负相关关系,即一个变量增加,另一个变量倾向于减少。所以,选项D正确。
相关系数主要体现的是线性相关关系的紧密程度,不能完全体现两个变量之间相关关系的类型。例如,两个变量可能存在二次函数关系等非线性关系,但相关系数可能为0,因为它主要针对线性关系。所以,选项E错误。
时,表明两个变量是负相关关系,即一个变量增加,另一个变量倾向于减少。所以,选项D正确。
相关系数主要体现的是线性相关关系的紧密程度,不能完全体现两个变量之间相关关系的类型。例如,两个变量可能存在二次函数关系等非线性关系,但相关系数可能为0,因为它主要针对线性关系。所以,选项E错误。
综上,正确的是A和D。
解析
相关系数是在线性相关条件下测定两个变量间相关关系密切程度的指标。它是用数值来准确地衡量两个变量之间线性关系的紧密程度。例如,对于变量X和Y,相关系数r的取值范围是$[ -1,1] $。当$I=d$时,表示X和Y之间存在完全正线性相关;当r=-1时,表示X和Y之间存在完全负线性相关;当$0=d$时,表示X和Y之间不存在线性相关关系。所以,选项A正确。
步骤 2:相关系数的计算
相关系数的计算是基于数据的客观计算,不是主观判断。它是根据样本数据通过特定的公式计算得出的,如对于样本数据$({x}_{i},{y}_{i})$,$\dot {2}=1,2,\cdots $ ,n,样本相关系数$r=\dfrac {\sum _{i=1}^{n-1}({x}_{i}-\overline {x})({y}_{i}-\overline {y})}{\sqrt {\sum _{i=1}^{n-1}{({x}_{i}-\overline {x})}^{2}{\sum _{i=1}^{n}{({y}_$,所以不是带有较强的主观性。所以,选项B错误。
步骤 3:相关系数与变量独立性
相关系数不是测定两个变量是否独立的指标。两个变量独立意味着它们的联合概率等于各自概率的乘积,而相关系数为0只是说明不存在线性相关关系,但变量之间可能存在其他非线性关系,所以不能简单地用相关系数来判断变量是否独立。所以,选项C错误。
步骤 4:相关系数与相关关系的方向
相关系数可以表明两个变量之间相关关系的方向。当$0\lt d$0" data-width="46" data-height="19" data-size="674" data-format="png" style="">时,表明两个变量是正相关关系,即一个变量增加,另一个变量也倾向于增加;当$0\gt d$时,表明两个变量是负相关关系,即一个变量增加,另一个变量倾向于减少。所以,选项D正确。
步骤 5:相关系数与相关关系的类型
相关系数主要体现的是线性相关关系的紧密程度,不能完全体现两个变量之间相关关系的类型。例如,两个变量可能存在二次函数关系等非线性关系,但相关系数可能为0,因为它主要针对线性关系。所以,选项E错误。