相关分析和回归分析的区别与联系(不知道要不要)联系:都是研究非确定性变量间的统计依赖关系,并能度量线性依赖程度的大小。区别:从研究目的上看:相关分析是研究变量间相互联系的方向和程度;回归分析是寻求变量间联系的具体数学形式,是要根据自变量的固定值去估计和预测[1]因变量的值。从对变量的处理来看:相关分析中的变量均为随机变量,不考虑两者的因果关系;回归分析是在变量因果关系的基础上研究自变量对因变量的具体影响,必须明确划分自变量和因变量,回归分析中通常假定自变量为非随机变量,因变量为随机变量。P26-27:随机干扰项:观察值Y围绕它的期望值[2]的离差,是一个不可观测的随机变量,又称为随机干扰项或随机误差[3]项。引入随机干扰项的原因1)代表未知的影响因素;2)代表残缺数据;3)代表众多细小影响因素;4)代表数据观测误差;5)代表模型设定[4]误差;6)变量的内在随机性。P26、28:样本回归函数和总体回归函数的公式总体回归函数:在给定解释变量[5]X条件下被解释变量Y的期望轨迹称为总体回归线,或更一般地称为总体回归曲线。相应的函数称为(双变量)总体回归函数(PRF)。确定形式:随机形式:样本回归函数SRF画一条直线以尽好地拟合该散点图,由于样本取自总体,可以该直线近似地代表总体回归线。该直线称为样本回归线(sample regression lines)。样本回归线的函数形式[6]称为样本回归函数.确定形式:随机形式:P29:图2.1.3回归分析的主要目的:根据样本回归函数SRF,估计总体回归函数PRF。这就要求设计一方法构造SRF使其尽可能接近PRF。这里的PRF可能永远无法知道。P30-32:一元线性回归模型的基本假设假设1、回归模型是正确的。(选择了正确的变量;选择了正确的函数形式。)假设2、解释变量X是确定性变量,不是随机变量,在重复抽样中取固定值。_(i)=(overline {Y)_(i)}+overline ({u)_(i)}=(P)_(0)+(overline {{P)_(1)}(X)_(i)+(e)_(i)假设3、解释变量X在所抽取的样本中具有变异性,而且随着样本容量的无限增加,解释变量X的方差趋于一个非零的有限常数。假设4、随机误差项具有给定X条件下的零均值、同方差和不序列相关性:E(i)=0Var (i)=2Cov(i,j)=0i≠j i,j= 1,2, …,n假设5、随机误差项与解释变量X之间不相关:Cov(Xi,i)=0 i=1,2, …,n_(i)=(overline {Y)_(i)}+overline ({u)_(i)}=(P)_(0)+(overline {{P)_(1)}(X)_(i)+(e)_(i)假设6、随机误差项服从零均值、同方差、零协方差的正态分布注意:如果假设1、2满足,则假设3也满足;如果假设4满足,则假设2也满足。i~N(0,2) i=1,2, …,nP33:最小二乘法的推导过程(推导至2.3.5)普通最小二乘法(OLS)给出的判断标准是:二者之差的平方和_(i)=(overline {Y)_(i)}+overline ({u)_(i)}=(P)_(0)+(overline {{P)_(1)}(X)_(i)+(e)_(i)最小。P38-40:最小二乘估计法的性质(重点看前三个,知道线性性和无偏性的推导)(1)线性性,即它是否是另一随机变量的线性函数;(2)无偏性,即它的均值或期望值是否等于总体的真实值;(3)有效性,即它是否在所有线性无偏估计量中具有最小方差。P44:图2.4.2区别那三个平方和(TSS,ESS,RSS)TSS=ESS+RSSY的观测值围绕其均值的总离差(total variation)可分解为两部分:一部分来自回归线(ESS),另一部分则来自随机势力(RSS)。总体平方和回归平方和残差平方和P45:可决系数R2统计量拟合优度检验:对样本回归直线与样本观测值之间拟合程度的检验。度量拟合优度的指标:判定系数(可决系数)R2_(i)=(overline {Y)_(i)}+overline ({u)_(i)}=(P)_(0)+(overline {{P)_(1)}(X)_(i)+(e)_(i)可决系数的取值范围:[0,1]R2________________________。P46-47:t检验(2.4.5)P49:如何才能缩小置信区间(2个)增大样本容量n。因为在同样的置信水平下,n越大,t分布表中的临界值越小;同时,增大样本容量,还可使样本参数估计量的标准差减小;提高模型的拟合优度。因为样本参数估计量的标准差与残差平方和呈正比,模型拟合优度越高,残差平方和应越小。
相关分析和回归分析的区别与联系(不知道要不要)
联系:都是研究非确定性变量间的统计依赖关系,并能度量线性依赖程度的大小。
区别:从研究目的上看:相关分析是研究变量间相互联系的方向和程度;回归分析是寻求变量间联系的具体数学形式,是要根据自变量的固定值去估计和预测[1]因变量的值。
从对变量的处理来看:相关分析中的变量均为随机变量,不考虑两者的因果关系;回归分析是在变量因果关系的基础上研究自变量对因变量的具体影响,必须明确划分自变量和因变量,回归分析中通常假定自变量为非随机变量,因变量为随机变量。
P26-27:随机干扰项:观察值Y围绕它的期望值[2]的离差,是一个不可观测的随机变量,又称为随机干扰项或随机误差[3]项。
引入随机干扰项的原因
1)代表未知的影响因素;
2)代表残缺数据;
3)代表众多细小影响因素;
4)代表数据观测误差;
5)代表模型设定[4]误差;
6)变量的内在随机性。
P26、28:样本回归函数和总体回归函数的公式
总体回归函数:在给定解释变量[5]X条件下被解释变量Y的期望轨迹称为总体回归线,或更一般地称为总体回归曲线。相应的函数称为(双变量)总体回归函数(PRF)。
确定形式:
随机形式:
样本回归函数SRF画一条直线以尽好地拟合该散点图,由于样本取自总体,可以该直线近似地代表总体回归线。该直线称为样本回归线(sample regression lines)。样本回归线的函数形式[6]称为样本回归函数.
确定形式:
随机形式:
P29:图2.1.3
回归分析的主要目的:根据样本回归函数SRF,估计总体回归函数PRF。这就要求设计一方法构造SRF使其尽可能接近PRF。这里的PRF可能永远无法知道。
P30-32:一元线性回归模型的基本假设
假设1、回归模型是正确的。(选择了正确的变量;选择了正确的函数形式。)
假设2、解释变量X是确定性变量,不是随机变量,在重复抽样中取固定值。
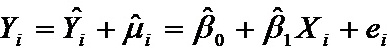 假设3、解释变量X在所抽取的样本中具有变异性,而且随着样本容量的无限增加,解释变量X的方差趋于一个非零的有限常数。
假设3、解释变量X在所抽取的样本中具有变异性,而且随着样本容量的无限增加,解释变量X的方差趋于一个非零的有限常数。
假设4、随机误差项具有给定X条件下的零均值、同方差和不序列相关性:
E(i)=0
Var (i)=2
Cov(i,j)=0i≠j i,j= 1,2, …,n
假设5、随机误差项与解释变量X之间不相关:
Cov(Xi,i)=0 i=1,2, …,n
 假设6、随机误差项服从零均值、同方差、零协方差的正态分布
假设6、随机误差项服从零均值、同方差、零协方差的正态分布
注意:
如果假设1、2满足,则假设3也满足;
如果假设4满足,则假设2也满足。
i~N(0,2) i=1,2, …,n
P33:最小二乘法的推导过程(推导至2.3.5)
普通最小二乘法(OLS)给出的判断标准是:二者之差的平方和最小。
P38-40:最小二乘估计法的性质(重点看前三个,知道线性性和无偏性的推导)
(1)线性性,即它是否是另一随机变量的线性函数;
(2)无偏性,即它的均值或期望值是否等于总体的真实值;
(3)有效性,即它是否在所有线性无偏估计量中具有最小方差。
P44:图2.4.2区别那三个平方和(TSS,ESS,RSS)
TSS=ESS+RSS
Y的观测值围绕其均值的总离差(total variation)可分解为两部分:一部分来自回归线(ESS),另一部分则来自随机势力(RSS)。
总体平方和
回归平方和
残差平方和
P45:可决系数R2统计量
拟合优度检验:对样本回归直线与样本观测值之间拟合程度的检验。
度量拟合优度的指标:判定系数(可决系数)R2

可决系数的取值范围:[0,1]
R2________________________。
P46-47:t检验(2.4.5)
P49:如何才能缩小置信区间(2个)
增大样本容量n。因为在同样的置信水平下,n越大,t分布表中的临界值越小;同时,增大样本容量,还可使样本参数估计量的标准差减小;
提高模型的拟合优度。因为样本参数估计量的标准差与残差平方和呈正比,模型拟合优度越高,残差平方和应越小。
题目解答
答案
越接近 1 ,说明实际观测点离样本线越近,拟合优度[7]越高
解析
可决系数(R²)是衡量回归模型拟合效果的重要指标。它的核心作用是反映模型对因变量变化的解释能力。R²的取值范围在0到1之间,越接近1,说明模型对数据的拟合效果越好。具体来说,R²表示回归平方和(ESS)占总平方和(TSS)的比例,即模型解释了多大比例的因变量变化。
1. 可决系数的定义
可决系数(R²)的计算公式为:
$R^2 = \frac{ESS}{TSS} = \frac{\text{回归平方和}}{\text{总平方和}}$
其中:
- 总平方和(TSS):反映因变量所有观测值与其均值的总离差。
- 回归平方和(ESS):反映回归线对因变量观测值的拟合程度。
- 残差平方和(RSS):反映观测值与回归线之间的残差大小。
2. R²的实际意义
- R²越接近1:说明ESS占TSS的比例越大,即回归模型能解释因变量的大部分变化,实际观测点更接近样本回归线,拟合优度高。
- R²越接近0:说明模型解释能力弱,观测点分散在回归线周围,拟合效果差。
3. 关键结论
- R²的取值范围:$0 \leq R^2 \leq 1$。
- R²与残差的关系:R²越大,残差平方和(RSS)越小,模型预测误差越小。