题目
若两个总体均服从正态分布,分别从两个总体中随机抽取样本,则两个样本均值之差服从的分布为( )A.标准正态分布 B.分 布 C. 分 布D.正态分布
若两个总体均服从正态分布,分别从两个总体中随机抽取样本,则两个样本均值之差服从的分布为( )
A.标准正态分布
B. 分 布
分 布
C.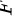 分 布
分 布
D.正态分布
题目解答
答案
由定理:设 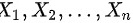 是来自正态总体
是来自正态总体 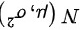 的样 本,
的样 本, 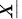 是样本均值, 则有
是样本均值, 则有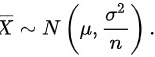
可得:若两个总体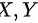 分别服从正态分体
分别服从正态分体 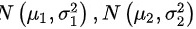 ,分别从两个总体中随机抽取样本和
,分别从两个总体中随机抽取样本和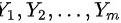 ,则两个样本均值都服从正态分布,即
,则两个样本均值都服从正态分布,即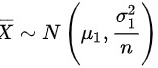 ‘
‘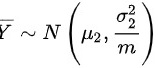
又由定理:有限个相互独立的正态随机变量的线性组合仍然服从正态分布
可知随机变量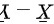 也服从正态分布
也服从正态分布
当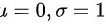 时,称随机变量
时,称随机变量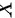 服从标准正态分布
服从标准正态分布
本题不知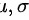 的值,不能判断是否为标准正态分布
的值,不能判断是否为标准正态分布
故本题答案选 D
解析
步骤 1:理解样本均值的分布
根据中心极限定理,如果从一个正态分布的总体中抽取样本,样本均值也将服从正态分布。具体来说,如果总体服从正态分布 $N(\mu, \sigma^2)$,那么样本均值 $\overline{X}$ 也将服从正态分布 $N(\mu, \frac{\sigma^2}{n})$,其中 $n$ 是样本大小。
步骤 2:考虑两个独立样本均值的分布
如果从两个独立的正态分布总体中分别抽取样本,那么这两个样本均值的差也将服从正态分布。具体来说,如果总体1服从正态分布 $N(\mu_1, \sigma_1^2)$,总体2服从正态分布 $N(\mu_2, \sigma_2^2)$,那么样本均值 $\overline{X}$ 和 $\overline{Y}$ 的差 $\overline{X} - \overline{Y}$ 将服从正态分布 $N(\mu_1 - \mu_2, \frac{\sigma_1^2}{n_1} + \frac{\sigma_2^2}{n_2})$,其中 $n_1$ 和 $n_2$ 分别是两个样本的大小。
步骤 3:确定分布类型
根据上述分析,两个样本均值之差 $\overline{X} - \overline{Y}$ 服从正态分布,但不一定是标准正态分布,因为标准正态分布的均值为0,标准差为1。由于我们不知道 $\mu_1$ 和 $\mu_2$ 的具体值,因此不能确定 $\overline{X} - \overline{Y}$ 是否为标准正态分布。
根据中心极限定理,如果从一个正态分布的总体中抽取样本,样本均值也将服从正态分布。具体来说,如果总体服从正态分布 $N(\mu, \sigma^2)$,那么样本均值 $\overline{X}$ 也将服从正态分布 $N(\mu, \frac{\sigma^2}{n})$,其中 $n$ 是样本大小。
步骤 2:考虑两个独立样本均值的分布
如果从两个独立的正态分布总体中分别抽取样本,那么这两个样本均值的差也将服从正态分布。具体来说,如果总体1服从正态分布 $N(\mu_1, \sigma_1^2)$,总体2服从正态分布 $N(\mu_2, \sigma_2^2)$,那么样本均值 $\overline{X}$ 和 $\overline{Y}$ 的差 $\overline{X} - \overline{Y}$ 将服从正态分布 $N(\mu_1 - \mu_2, \frac{\sigma_1^2}{n_1} + \frac{\sigma_2^2}{n_2})$,其中 $n_1$ 和 $n_2$ 分别是两个样本的大小。
步骤 3:确定分布类型
根据上述分析,两个样本均值之差 $\overline{X} - \overline{Y}$ 服从正态分布,但不一定是标准正态分布,因为标准正态分布的均值为0,标准差为1。由于我们不知道 $\mu_1$ 和 $\mu_2$ 的具体值,因此不能确定 $\overline{X} - \overline{Y}$ 是否为标准正态分布。