题目
11.我们知道营业税税收总额y与社会商品零售总额x有关.为能从社会商品零售-|||-总额去预测税收总额,需要了解两者之间的关系.现收集了如下9组数据:-|||-单位:亿元-|||-序号 社会商品零售总额 营业税税收总额-|||-1 142.08 3.93-|||-2 177.30 5.96-|||-3 204.68 7.85-|||-4 242.68 9.82-|||-5 316.24 12.50-|||-6 341.99 15.55-|||-7 332.69 15.79-|||-8 389.29 16.39-|||-9 453.40 18.45-|||-(1)画散点图;-|||-(2)建立一元线性回归方程,并作显著性检验(取 alpha =0.05, 列出方差分析表;-|||-(3)若已知某年社会商品零售额为300亿元,试给出营业税税收总额的概率为-|||-0.95的预测区间;-|||-(4)若已知回归直线过原点,试求回归方程,并在显著性水平0.05下作显著性-|||-检验.
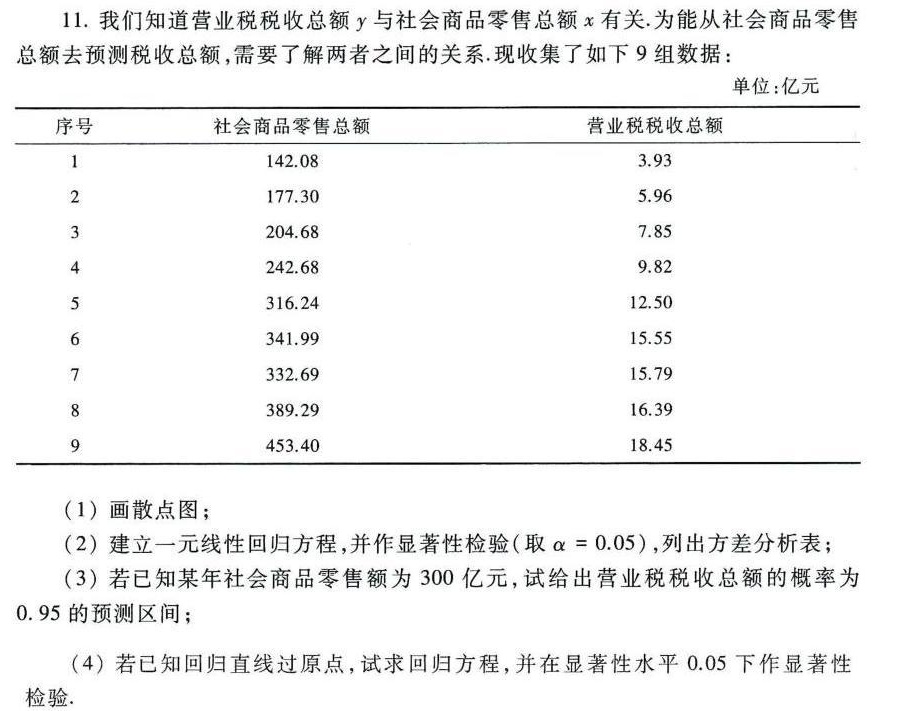
题目解答
答案
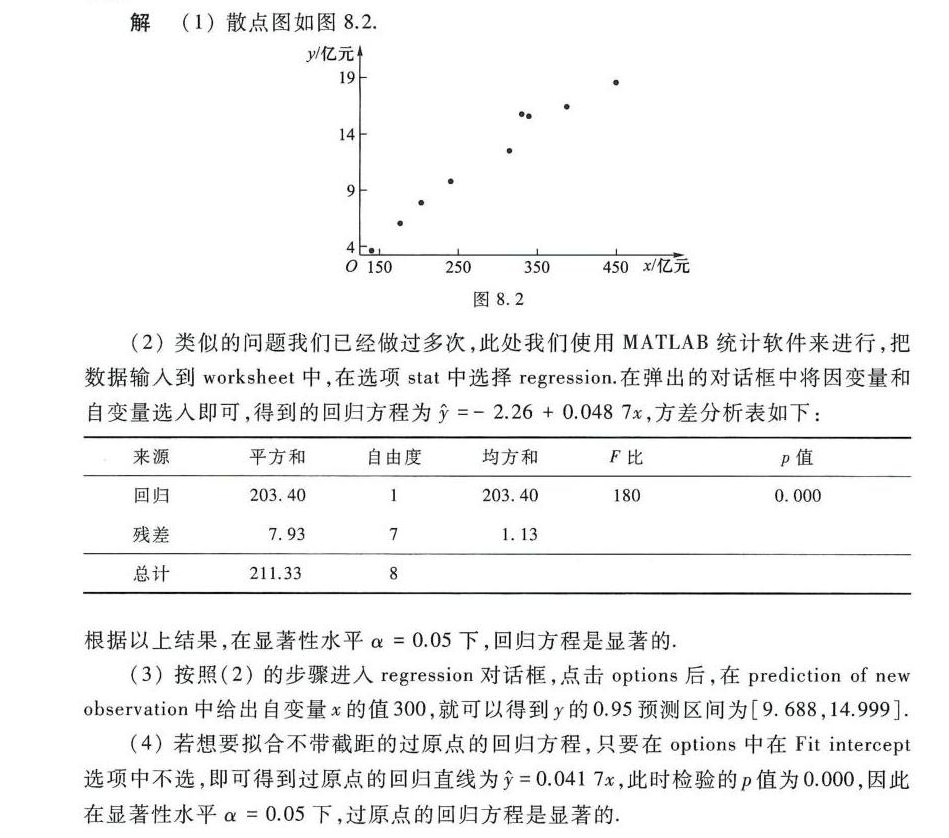
解析
本题主要主要考查一元线性回归分析,包括绘制散点图、建立一元线性回归方程、进行显著性检验、计算预测区间以及过原点的回归方程求解与检验。解题思路如下:
- 绘制散点图:
- 以社会商品零售总额 $x$ 为横坐标,营业税税收总额 $y$ 为纵坐标,将给定的 9 组数据在平面直角坐标系中描点,从而得到散点图。通过散点图能直观展示两个变量之间的大致关系。
- 建立一元线性回归方程并作显著性检验:
- 设一元线性回归方程为 $\hat{y}=\hat{\beta}_{0}+\hat{\beta}_{1}x$,其中 $\hat{\hat{\beta}_{0},\hat{\beta}_{1}\}$ 是待估计的参数。
- 利用最小二乘法来估计参数估计,公式为:
- $\hat{\beta}_{1}=\frac{\sum_{i = 1}^{n}(x_{i}-\bar{x}})(y_{i}-\bar{y})}{\sum_{i = 1}^{n}(x_{i}-\bar{x})^{2}}$
- $\hat{\beta}_{0}=\bar{y}-\hat{\beta}_{1}\bar{x}$
- 其中 $\bar{x}=\frac{1}{n}\sum_{i = 1}^{n}x_{i}$,$\bar{y}=\frac{1{n}\sum_{i = 1}^{n}y_{i}$,$n = 9$。
- 本题使用 MATLAB 统计软件,将数据输入到 worksheet 中,在选项 stat 中选择 regression,把因变量 $y$ 和自变量 $x$ 选入,可得到回归方程 $\hat{y}=-2.26 + 0.047x$。
- 进行显著性检验,构建方差分析表。方差分析表包含来源(回归、残差、总计)、平方和($SS$、自由度$df$、均方和$MS$、$F$比和$p\(p$值。
- 总平方和 $SST=\sum_{i = 1}^{n}(y_{i}-\bar{y})^{2}$
- 回归平方和 $SSR=\sum_{i = 1}^{n}(\hat{y}_{i}-\bar{y})^{2}$
- 残差平方和 $SSE=\sum_{i = 1}^{n}(y_{i}-\hat{y}_{i})^{2}$
- 自由度:回归自由度 $df_{R}=1$,残差自由度 $df_{E}= \(n - 2=7$,总自由度 $df_{T}=n - 1 = 8$。
- 均方和 $MS_{R}=\frac{SSR}{df_{R}}$,$MS_{E}=\frac{SSE}{df_{E}}$。
- $F$比 $F=\frac{MS_{R}}{MS_{E}}$。
- 根据 $p$值与显著性水平 $\alpha = 0.05$ 比较,若 $p<\alpha$,则回归方程显著。本题中 $p = 0.000<0.05$,所以回归方程显著。
- 计算预测区间:
- 已知回归方程 $\hat{y}=-2.26 + 0.047x$。
- 当 $x = 300$ 时,$\hat{y}=-2.26+0.047\times300 = 10.32$。
- 利用 MATLAB 软件,按照 (2) 的步骤步骤进入 regression 对话框,点击 options 后,在 prediction of new observation 中给出自变量 $x$ 的值 300,就可以得到 $y$ 的 0.95 预测区间为 $[9.688,14.999]$。
- 过原点的回归方程求解与检验:
- 设过原点的回归方程为 $\hat{y}=\hat{\hat{\beta}_{1}}x$,其中 $\hat{\beta}_{1}$ 是待估计的参数。
- 利用最小二乘法进行参数估计,公式为 $\hat{\beta}_{1}=\frac{\sum_{i = 1}^{n}(x_{i}-\bar{x})(y_{i}-\bar{y})}{\sum_{i = 1}^{n}(x_{i}-\bar{x})^{2}}$。
- 使用 MATLAB 软件,在 options 中在 Fit intercept 选项中不选,得到过原点的回归直线为 $\hat{y}=0.0417x$。
- 进行显著性检验,得到检验的 $p$ 值为 0.000。
- 因为 $p = 0.000<0.05=\alpha$,所以在显著性水平 $\alpha = 0.05$ 下,过原点的回归方程是显著的。