违背基本假设的情况4.1 试举例说明产生异方差的原因。答:由于实际问题是错综负责的,因而在建立实际问题的回归分析模型时,经常会出现某一因素或一些因素随着解释变量[1]观测值的变化对被解释变量产生不同的影响,导致随机误差[2]项产生不同方差。引起异方差的原因很多,但样本数据为截面数据(微观数据)时容易出现异方差。例如:研究居民家庭的储蓄行为Yi=b0+b1Xi+其中:Yi表示第i个家庭的储蓄额,Xi表示第i个家庭的可支配收入。由于高收入家庭储蓄额的差异较大,低收入家庭的储蓄额则更有规律性,差异较小,所以的方差呈现单调递增型变化。4.2 异方差带来的后果有哪些?答:回归模型一旦出现异方差性,如果仍采用OLS估计模型参数,会产生下列不良后果:1)、参数估计量非有效2)、变量的显著性检验失去意义3)、回归方程的应用效果极不理想总的来说,当模型出现异方差性时,参数OLS估计值的变异程度增大,从而造成对Y的预测误差变大,降低预测精度,预测功能失效。4.3 简述用加权最小二乘法消除一元线性回归中异方差性的思想与方法。答:普通最小二乘估计就是寻找参数的估计值使离差平方和达极小。其中每个平方项的权数相同,是普通最小二乘回归参数估计方法。在误差项等方差不相关的条件下,普通最小二乘估计是回归参数的最小方差线性无偏估计。然而在异方差的条件下,平方和中的每一项的地位是不相同的,误差项的方差大的项,在残差平方和中的取值就偏大,作用就大,因而普通最小二乘估计的回归线就被拉向方差大的项,方差大的项的拟合程度就好,而方差小的项的拟合程度就差。由OLS求出的仍然是的无偏估计,但不再是最小方差线性无偏估计。所以就是:对较大的残差平方赋予较小的权数,对较小的残差平方赋予较大的权数。这样对残差所提供信息的重要程度作一番校正,以提高参数估计的精度。4.5(4.5)式一元加权最小二乘回归系数估计公式。 474.6验证(4.8)式多元加权最小二乘回归系数估计公式。 474.7 有同学认为当数据存在异方差时,加权最小二乘回归方程与普通最小二乘回归方程之间必然有很大的差异,异方差越严重,两者之间的差异就越大。你是否同意这位同学的观点?说明原因。 484.8 对例4.3的数据,用公式计算出加权变换残差,绘制加权变换残差图,根据绘制出的图形说明加权最小二乘估计的效果。 484.9 表4.12是用电高峰期每小时用电量y与每月总用电量x的数据。 491)用普通最小二乘法建立y与x的回归方程,并画出残差散点图; 502)诊断该问题是否存在异方差 513)如果存在异方差,用幂指数型的权函数建立加权最小二乘回 归方程 524)用方差稳定变换=消除异方差 534.10 试举一可能产生随机误差项序列相关的经济例子。 554.11 序列相关性带来的严重后果是什么? 554.12 结DW检验的优缺点。 564.13 表4.13为某软件公司月销售额数据,其中,x为总公司的月销售额(万元);y为某分公司的月销售额(万元)。 561)用普通最小二乘法建立y关于x的回归方程 572)用残差图及DW检验诊断序列的相关性 573)用迭代法处理序列相关,并建立回归方程 584)用一阶差分法处理数据,建立回归方程 605)比较普通最小二乘法所得回归方程和迭代法,一阶差分法所建立回归方程的优良性 614.14某乐队经理研究其乐队CD盘的销售额(y),两个有关的影响变量是每周演出场次 631)用普通最小二乘法建立y与和的回归方程,用残差图及DW检验诊断序列的自相性 642)用迭代法处理序列相关,建立回归方程 663)用一阶差分法处理序列相关,建立回归方程 664)用最大似然法处理序列相关,建立回归方程 675)用科克伦-奥克特迭代法处理序列相关,建立回归方程 686)用普莱斯-温斯登迭代法处理序列相关,建立回归方程 684.4简述用加权最小二乘法消除多元线性回归中异方差性的思想与方法。答:加权最小二乘估计的方法是在平方和加入一个适当的权数,以调整各项在平方和中的作用。一元线性回归的加权最小二乘的离差平方和为:其中,为给定的第i个观测值的权数。加权最小二乘估计就是寻找参数的估计值,使得上述离差平方和达到极小。如果所有的权数都相等,则都等于某个常数,此时问题就成为了普通最小二乘法。可以证明最小二乘估计为:加权最小二乘估计的计算可以用SPSS软件完成。有关权数的确定:(1)为了使离差平方和中各项的地位相同,观测值的权数应该是观测值误差项方差的倒数,即:(2)在实际问题的研究中,误差项的方差通常是未知的,但是误差项方差随自变量水平以系统的形式变化时,我们可以利用这种关系。如,已知误差项方差与成比例,那么=k,其中k为比例系数。权数为:=1/(k),因为比例系数k在参数估计中可以消去,所以我们可以直接使用权数:=1/(3)在社会,经济研究中,经常会遇到这种特殊的权数,即误差项方差与x的幂函数成比例,其中,m为待定的未知数。此时的权函数为:=1/4.5(4.5)式一元加权最小二乘回归系数估计公式。证明:4.6验证(4.8)式多元加权最小二乘回归系数估计公式。证明:对于多元线性回归模型 (1),即存在异方差。设,用左乘(1)式两边,得到一个新的的模型:,即。因为,故新的模型具有同方差性,故可以用广义最小二乘法估计该模型,得原式得证。4.7 有同学认为当数据存在异方差时,加权最小二乘回归方程与普通最小二乘回归方程之间必然有很大的差异,异方差越严重,两者之间的差异就越大。你是否同意这位同学的观点?说明原因。答:不同意。当回归模型存在异方差时,加权最小二乘估计(WLS)只是普通最小二乘估计(OLS)的改进,这种改进可能是细微的,不能理解为WLS一定会得到与OLS截然不同的方程来,或者大幅度的改进。实际上可以构造这样的数据,回归模型存在很强的异方差,但WLS 与OLS的结果一样。加权最小二乘法不会消除异方差,只是消除异方差的不良影响,从而对模型进行一点改进。4.8 对例4.3的数据,用公式计算出加权变换残差,绘制加权变换残差图,根据绘制出的图形说明加权最小二乘估计的效果。
违背基本假设的情况
4.1 试举例说明产生异方差的原因。
答:由于实际问题是错综负责的,因而在建立实际问题的回归分析模型时,经常会出现某一因素或一些因素随着解释变量[1]观测值的变化对被解释变量产生不同的影响,导致随机误差[2]项产生不同方差。引起异方差的原因很多,但样本数据为截面数据(微观数据)时容易出现异方差。
例如:研究居民家庭的储蓄行为
Yi=b0+b1Xi+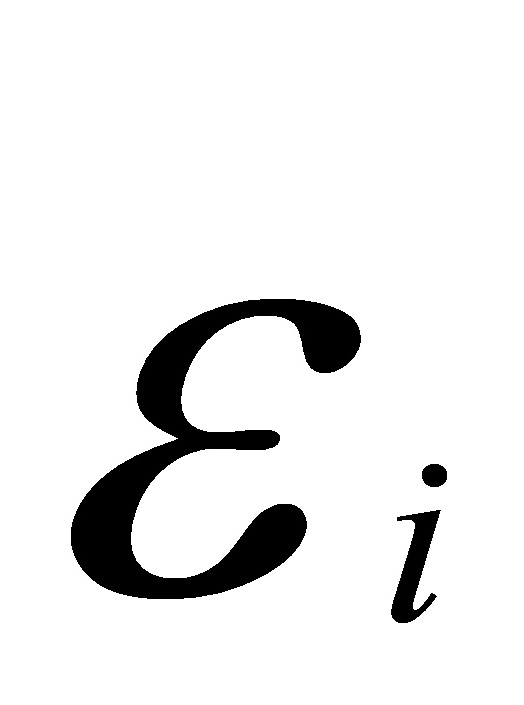
其中:Yi表示第i个家庭的储蓄额,Xi表示第i个家庭的可支配收入。
由于高收入家庭储蓄额的差异较大,低收入家庭的储蓄额则更有规律性,差异较小,所以的方差呈现单调递增型变化。
4.2 异方差带来的后果有哪些?
答:回归模型一旦出现异方差性,如果仍采用OLS估计模型参数,会产生下列不良后果:
1)、参数估计量非有效
2)、变量的显著性检验失去意义
3)、回归方程的应用效果极不理想
总的来说,当模型出现异方差性时,参数OLS估计值的变异程度增大,从而造成对Y的预测误差变大,降低预测精度,预测功能失效。
4.3 简述用加权最小二乘法消除一元线性回归中异方差性的思想与方法。
答:普通最小二乘估计就是寻找参数的估计值使离差平方和达极小。其中每个平方项的权数相同,是普通最小二乘回归参数估计方法。在误差项等方差不相关的条件下,普通最小二乘估计是回归参数的最小方差线性无偏估计。然而在异方差的条件下,平方和中的每一项的地位是不相同的,误差项的方差大的项,在残差平方和中的取值就偏大,作用就大,因而普通最小二乘估计的回归线就被拉向方差大的项,方差大的项的拟合程度就好,而方差小的项的拟合程度就差。由OLS求出的仍然是的无偏估计,但不再是最小方差线性无偏估计。所以就是:对较大的残差平方赋予较小的权数,对较小的残差平方赋予较大的权数。这样对残差所提供信息的重要程度作一番校正,以提高参数估计的精度。
4.5(4.5)式一元加权最小二乘回归系数估计公式。 47
4.6验证(4.8)式多元加权最小二乘回归系数估计公式。 47
4.7 有同学认为当数据存在异方差时,加权最小二乘回归方程与普通最小二乘回归方程之间必然有很大的差异,异方差越严重,两者之间的差异就越大。你是否同意这位同学的观点?说明原因。 48
4.8 对例4.3的数据,用公式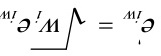 计算出加权变换残差
计算出加权变换残差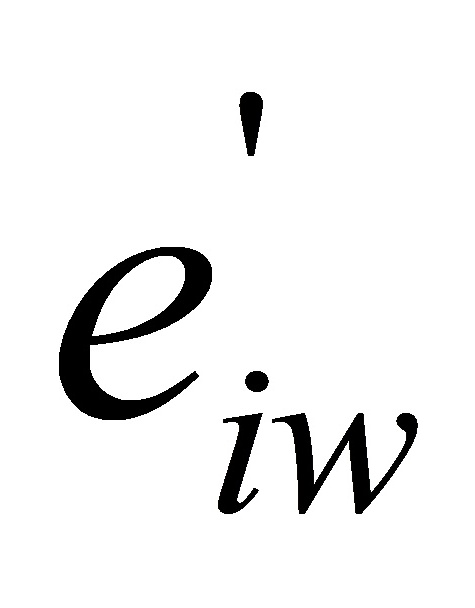 ,绘制加权变换残差图,根据绘制出的图形说明加权最小二乘估计的效果。 48
,绘制加权变换残差图,根据绘制出的图形说明加权最小二乘估计的效果。 48
4.9 表4.12是用电高峰期每小时用电量y与每月总用电量x的数据。 49
1)用普通最小二乘法建立y与x的回归方程,并画出残差散点图; 50
2)诊断该问题是否存在异方差 51
3)如果存在异方差,用幂指数型的权函数建立加权最小二乘回 归方程 52
4)用方差稳定变换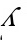 =
=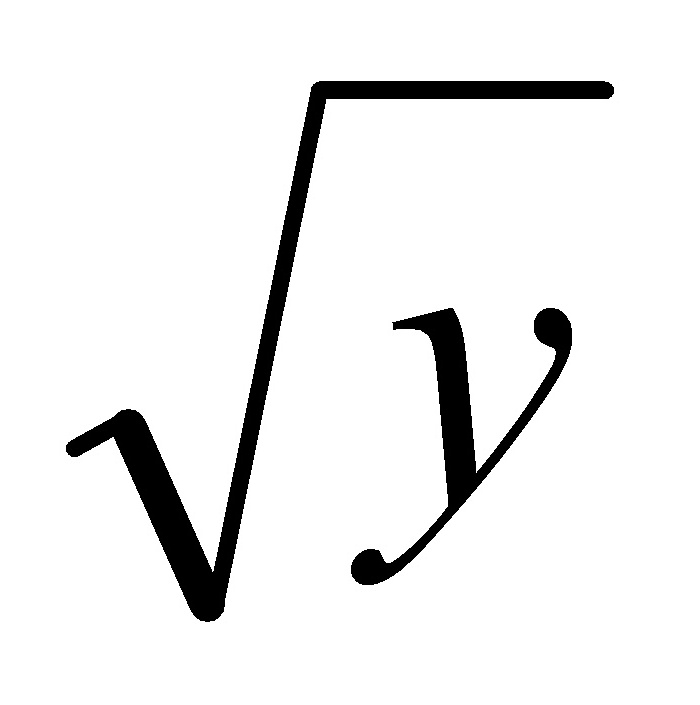 消除异方差 53
消除异方差 53
4.10 试举一可能产生随机误差项序列相关的经济例子。 55
4.11 序列相关性带来的严重后果是什么? 55
4.12 结DW检验的优缺点。 56
4.13 表4.13为某软件公司月销售额数据,其中,x为总公司的月销售额(万元);y为某分公司的月销售额(万元)。 56
1)用普通最小二乘法建立y关于x的回归方程 57
2)用残差图及DW检验诊断序列的相关性 57
3)用迭代法处理序列相关,并建立回归方程 58
4)用一阶差分法处理数据,建立回归方程 60
5)比较普通最小二乘法所得回归方程和迭代法,一阶差分法所建立回归方程的优良性 61
4.14某乐队经理研究其乐队CD盘的销售额(y),两个有关的影响变量是每周演出场次 63
1)用普通最小二乘法建立y与 和
和 的回归方程,用残差图及DW检验诊断序列的自相性 64
的回归方程,用残差图及DW检验诊断序列的自相性 64
2)用迭代法处理序列相关,建立回归方程 66
3)用一阶差分法处理序列相关,建立回归方程 66
4)用最大似然法处理序列相关,建立回归方程 67
5)用科克伦-奥克特迭代法处理序列相关,建立回归方程 68
6)用普莱斯-温斯登迭代法处理序列相关,建立回归方程 68
4.4简述用加权最小二乘法消除多元线性回归中异方差性的思想与方法。
答:加权最小二乘估计的方法是在平方和加入一个适当的权数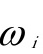 ,以调整各项在平方和中的作用。一元线性回归的加权最小二乘的离差平方和为:
,以调整各项在平方和中的作用。一元线性回归的加权最小二乘的离差平方和为:
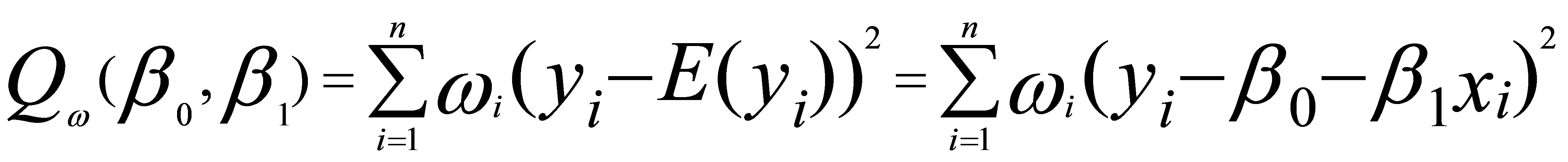 其中,为给定的第i个观测值的权数。加权最小二乘估计就是寻找参数的估计值
其中,为给定的第i个观测值的权数。加权最小二乘估计就是寻找参数的估计值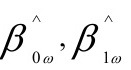 ,使得上述离差平方和
,使得上述离差平方和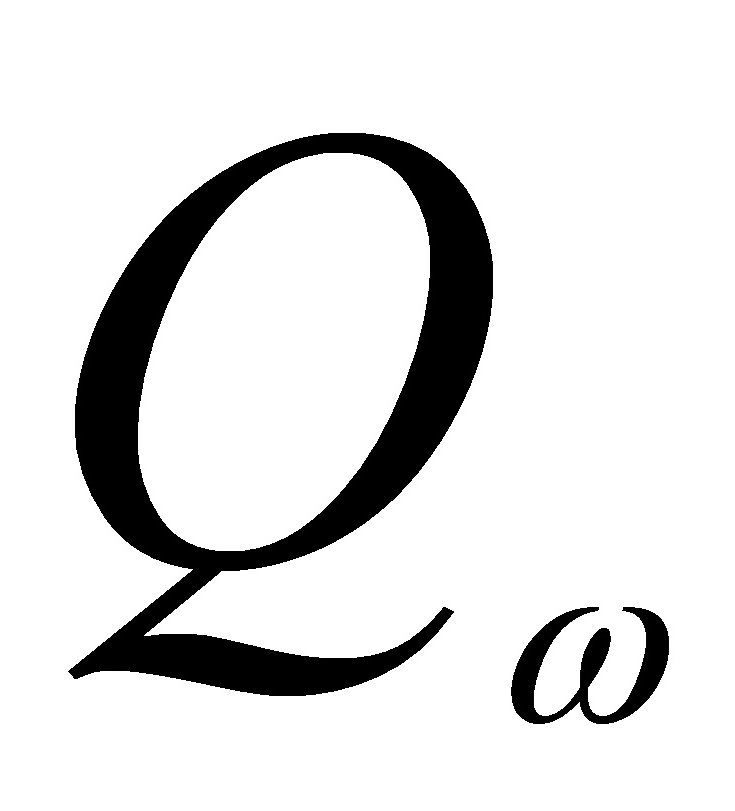 达到极小。如果所有的权数都相等,则都等于某个常数,此时问题就成为了普通最小二乘法。
达到极小。如果所有的权数都相等,则都等于某个常数,此时问题就成为了普通最小二乘法。
可以证明最小二乘估计为:
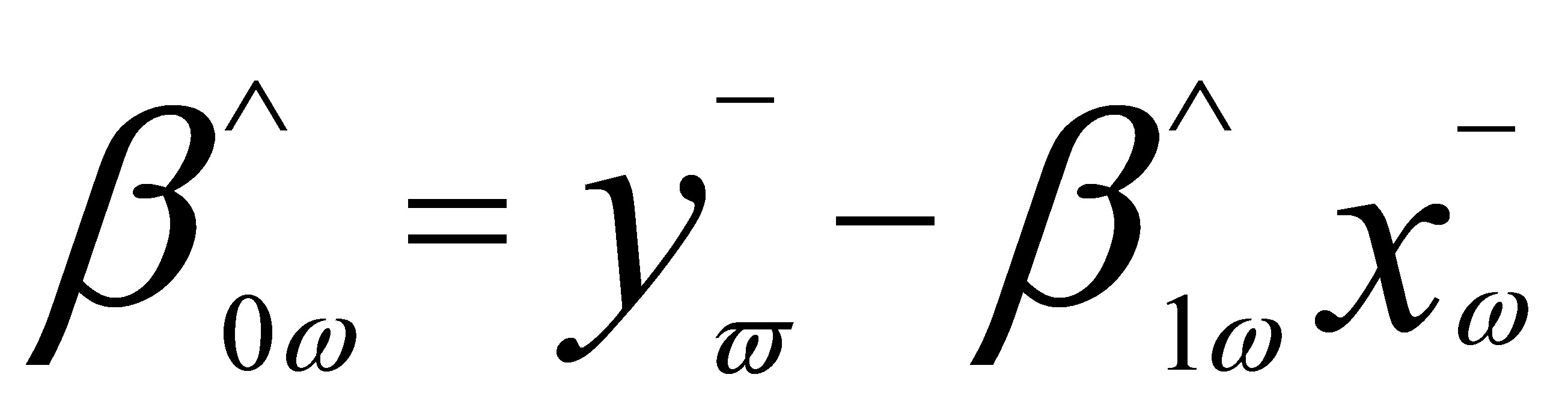
加权最小二乘估计的计算可以用SPSS软件完成。
有关权数的确定:
(1)为了使离差平方和中各项的地位相同,观测值的权数应该是观测值误差项方差的倒数,即:
(2)在实际问题的研究中,误差项的方差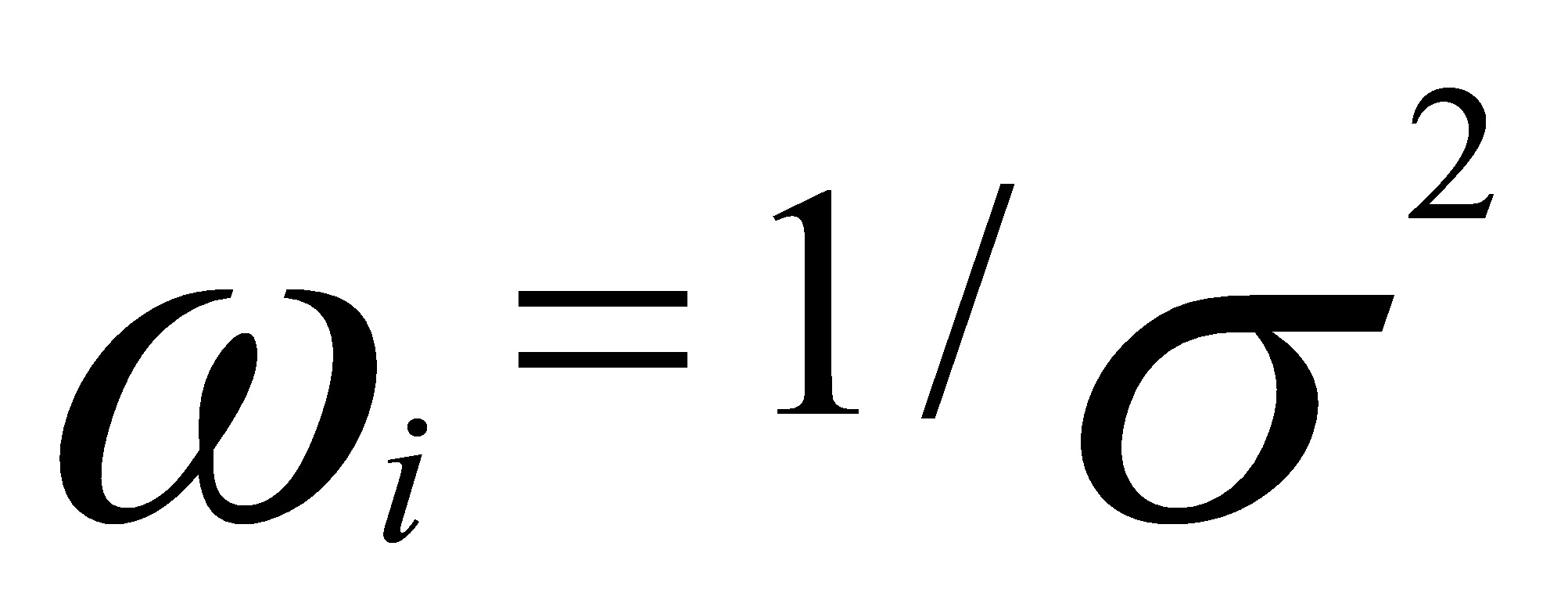 通常是未知的,但是误差项方差随自变量水平以系统的形式变化时,我们可以利用这种关系。如,已知误差项方差与成比例,那么=k,其中k为比例系数。权数为:=1/(k),因为比例系数k在参数估计中可以消去,所以我们可以直接使用权数:=1/
通常是未知的,但是误差项方差随自变量水平以系统的形式变化时,我们可以利用这种关系。如,已知误差项方差与成比例,那么=k,其中k为比例系数。权数为:=1/(k),因为比例系数k在参数估计中可以消去,所以我们可以直接使用权数:=1/
(3)在社会,经济研究中,经常会遇到这种特殊的权数,即误差项方差与x的幂函数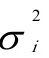 成比例,其中,m为待定的未知数。此时的权函数为:=1/
成比例,其中,m为待定的未知数。此时的权函数为:=1/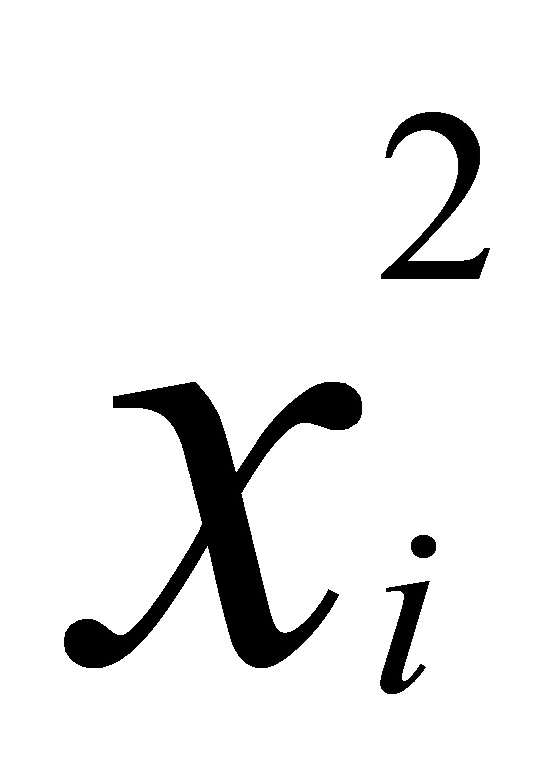
4.5(4.5)式一元加权最小二乘回归系数估计公式。
证明:
4.6验证(4.8)式多元加权最小二乘回归系数估计公式。
证明:对于多元线性回归模型 (1)
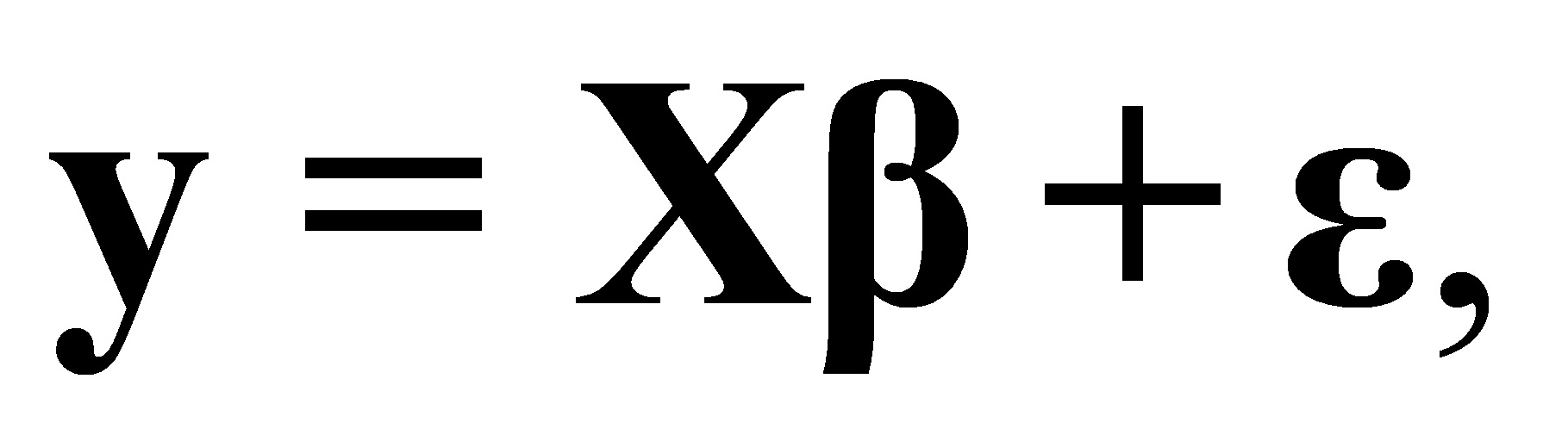 ,即存在异方差。设
,即存在异方差。设
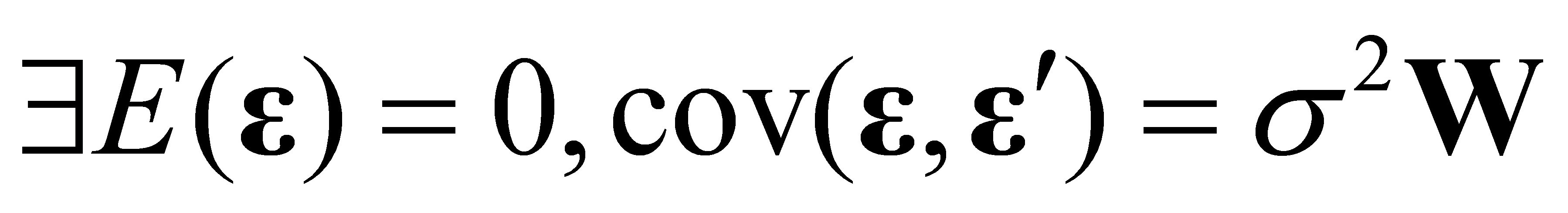 ,
,
用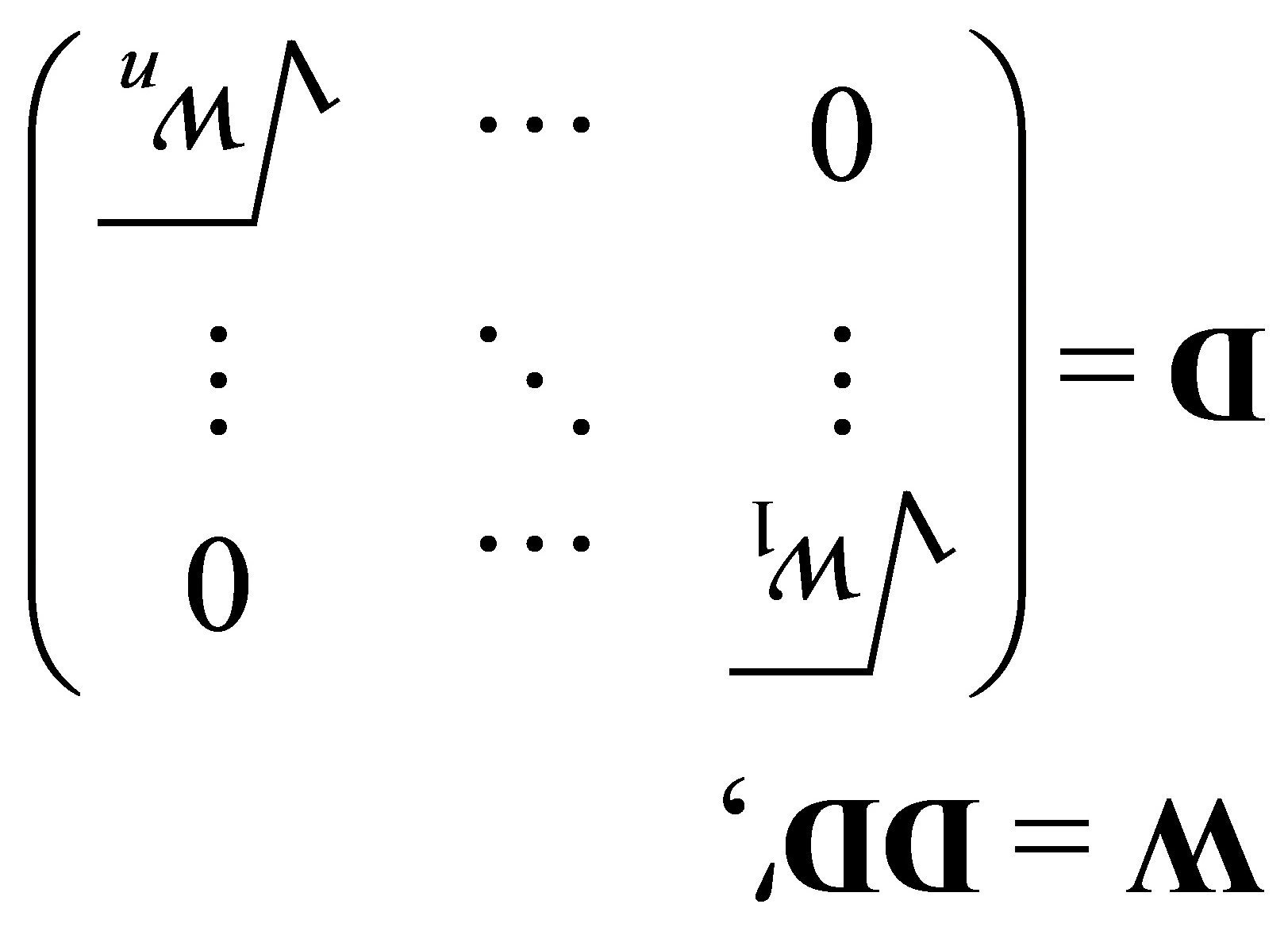 左乘(1)式两边,得到一个新的的模型:
左乘(1)式两边,得到一个新的的模型:
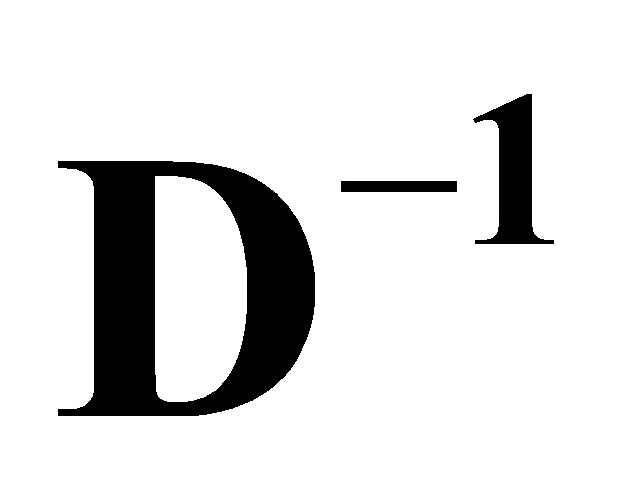 ,即。
,即。
因为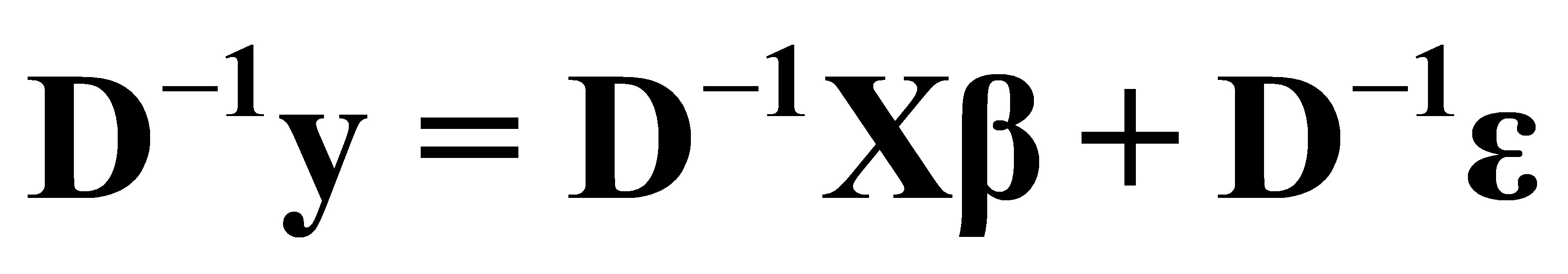 ,
,
故新的模型具有同方差性,故可以用广义最小二乘法估计该模型,得
原式得证。
4.7 有同学认为当数据存在异方差时,加权最小二乘回归方程与普通最小二乘回归方程之间必然有很大的差异,异方差越严重,两者之间的差异就越大。你是否同意这位同学的观点?说明原因。
答:不同意。当回归模型存在异方差时,加权最小二乘估计(WLS)只是普通最小二乘估计(OLS)的改进,这种改进可能是细微的,不能理解为WLS一定会得到与OLS截然不同的方程来,或者大幅度的改进。实际上可以构造这样的数据,回归模型存在很强的异方差,但WLS 与OLS的结果一样。加权最小二乘法不会消除异方差,只是消除异方差的不良影响,从而对模型进行一点改进。
4.8 对例4.3的数据,用公式计算出加权变换残差,绘制加权变换残差图,根据绘制出的图形说明加权最小二乘估计的效果。
题目解答
答案
此时等级相关系数为:-0.179 P值为0.199说明此时已经消除了异方差的影响;
但由于此时的决定系数R方为:0.648 小于最小二乘估计时的R方0.705 说明此的回归效果并不比最小而乘估计有效。
4.10 试举一可能产生随机误差项序列相关[3]的经济例子。
答:例如,居民总消费函数模型:
Ct=b0+b1Yt+ ε t t=1,2,…,n
由于居民收入对消费影响有滞后性,而且今年消费水平受上年消费水平影响,则可能出现序列相关性。另外由于消费习惯的影响被包含在随机误差项中,则可能出现序列相关性(往往是正相关 )。
4.11 序列相关性带来的严重后果是什么?
答:直接用普通最小二乘法估计随机误差项存在序列相关性的线性回归模型未知参数时,会产生下列一些问题:
1,参数估计量仍然是无偏的,但不具有有效性,因为有自相关性时参数估计值的方差大于无自相关性时的方差。
2,均方误差MSE可能严重低估误差项[4]的方差
7)比较以上各方法所见回归方程的优良性。 69
4.15说明引起异常值的原因和消除异常值的方法。 70