题目
设总体 sim N(0,2) ,(X1,X2,···,X6)是来-|||-自总体X的样本,若 dfrac (a({X)_(1)+(X)_(2))}(sqrt {{sum )_(i=3)^6({X)_(2)}^2}} 服从t分布,-|||-则a=-|||-A3-|||-B sqrt (2)-|||-C 0-|||-D1

题目解答
答案



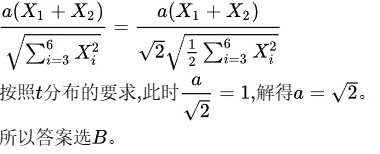
解析
考查要点:本题主要考查t分布的构成条件,涉及正态分布、卡方分布的性质及其相互独立性。
解题核心思路:
- 分子部分:将$X_1 + X_2$标准化为标准正态分布。
- 分母部分:将$\sum_{i=3}^6 X_i^2$转化为卡方分布的形式。
- 结合t分布定义:分子为标准正态变量,分母为卡方分布的平方根除以自由度,通过系数匹配确定$a$的值。
破题关键点:
- 正态分布的线性组合:$X_1 + X_2$服从$N(0, 4)$,标准化后为$\frac{X_1 + X_2}{2} \sim N(0, 1)$。
- 卡方分布的构造:$\sum_{i=3}^6 \left(\frac{X_i}{\sqrt{2}}\right)^2 \sim \chi^2(4)$,因此$\sum_{i=3}^6 X_i^2 \sim 2\chi^2(4)$。
- t分布的形式:分子需为标准正态变量,分母需为$\sqrt{\frac{\chi^2(4)}{4}}$,通过系数匹配确定$a = \sqrt{2}$。
1. 分析分子部分的分布
- $X_1 \sim N(0, 2)$,$X_2 \sim N(0, 2)$,且相互独立。
- $X_1 + X_2 \sim N(0 + 0, 2 + 2) = N(0, 4)$。
- 标准化后:$\frac{X_1 + X_2}{\sqrt{4}} = \frac{X_1 + X_2}{2} \sim N(0, 1)$。
2. 分析分母部分的分布
- 对于$i = 3,4,5,6$,$\frac{X_i}{\sqrt{2}} \sim N(0, 1)$。
- $\sum_{i=3}^6 \left(\frac{X_i}{\sqrt{2}}\right)^2 \sim \chi^2(4)$。
- 因此,$\sum_{i=3}^6 X_i^2 = 2 \cdot \chi^2(4)$。
3. 结合t分布的定义
- t分布形式:$\frac{U}{\sqrt{\frac{V}{n}}}$,其中$U \sim N(0, 1)$,$V \sim \chi^2(n)$,且$U$与$V$独立。
- 原式变形为:
$\frac{a(X_1 + X_2)}{\sqrt{\sum_{i=3}^6 X_i^2}} = \frac{a \cdot 2 \cdot \frac{X_1 + X_2}{2}}{\sqrt{2 \cdot \chi^2(4)}} = \frac{2a \cdot U}{\sqrt{2} \cdot \sqrt{\chi^2(4)}}.$ - 要求分子系数为1,即$\frac{2a}{\sqrt{2}} = 1$,解得$a = \sqrt{2}$。