题目
33对于单向有序行列表,在比较各处理组的效应有无差别时,用检验不是最好的方法。()34.如果对全部研究对象都进行了调查或测定就没有抽样误差。()35.95%与99%的参考值范围相比,前者漏诊率大,后者误诊率大。( )
33对于单向有序行列表,在比较各处理组的效应有无差别时,用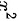 检验不是最好的方法。()
检验不是最好的方法。()
34.如果对全部研究对象都进行了调查或测定就没有抽样误差。()
35.95%与99%的参考值范围相比,前者漏诊率大,后者误诊率大。( )
题目解答
答案
正确
对于单向有序行列表(ordered categorical data),如果要比较各处理组的效应是否有差别,通常使用卡方检验不是最佳的方法。因为卡方检验通常用于比较分类变量的分布差异,而不是用于比较处理组效应的差异。更适合比较处理组效应差异的方法可能包括ANOVA(方差分析)或相关的非参数检验方法,如Kruskal-Wallis检验等。
错误
即使对全部研究对象进行了调查或测定,也可能存在其他类型的误差,例如测量误差或记录误差。因此,即使对所有对象进行调查或测定,仍然可能存在其他类型的误差,不仅仅是抽样误差。
正确
在医学诊断中,参考值范围(reference range)通常用于判断某一结果是否正常。95% 的参考值范围较窄,对应的漏诊率较高,即将正常情况错误地判断为异常;而99% 的参考值范围较宽,对应的误诊率较高,即将异常情况错误地判断为正常。因此,相对于95%的参考范围,99%的参考范围有更高的误诊率。
解析
步骤 1:理解单向有序行列表
单向有序行列表是指数据按照某种顺序排列,例如等级数据。这种数据类型通常用于描述不同处理组的效应。
步骤 2:理解检验方法
卡方检验通常用于比较分类变量的分布差异,而不是用于比较处理组效应的差异。对于单向有序行列表,更适合的方法可能是非参数检验,如Kruskal-Wallis检验。
步骤 3:判断正确性
由于卡方检验不是比较处理组效应差异的最佳方法,因此该陈述是正确的。
【答案】
正确
34. 如果对全部研究对象都进行了调查或测定就没有抽样误差。()
【解析】
步骤 1:理解抽样误差
抽样误差是指由于样本不能完全代表总体而产生的误差。当对全部研究对象进行调查或测定,即进行普查时,理论上不存在抽样误差。
步骤 2:考虑其他误差
即使进行普查,也可能存在其他类型的误差,如测量误差或记录误差。
步骤 3:判断正确性
由于普查时不存在抽样误差,但可能存在其他类型的误差,因此该陈述是错误的。
【答案】
错误
35. 95%与99%的参考值范围相比,前者漏诊率大,后者误诊率大。( )
【解析】
步骤 1:理解参考值范围
参考值范围用于判断某一结果是否正常。95%的参考值范围较窄,99%的参考值范围较宽。
步骤 2:理解漏诊率和误诊率
漏诊率是指将正常情况错误地判断为异常,误诊率是指将异常情况错误地判断为正常。
步骤 3:判断正确性
95%的参考值范围较窄,对应的漏诊率较高;99%的参考值范围较宽,对应的误诊率较高。因此,该陈述是正确的。
单向有序行列表是指数据按照某种顺序排列,例如等级数据。这种数据类型通常用于描述不同处理组的效应。
步骤 2:理解检验方法
卡方检验通常用于比较分类变量的分布差异,而不是用于比较处理组效应的差异。对于单向有序行列表,更适合的方法可能是非参数检验,如Kruskal-Wallis检验。
步骤 3:判断正确性
由于卡方检验不是比较处理组效应差异的最佳方法,因此该陈述是正确的。
【答案】
正确
34. 如果对全部研究对象都进行了调查或测定就没有抽样误差。()
【解析】
步骤 1:理解抽样误差
抽样误差是指由于样本不能完全代表总体而产生的误差。当对全部研究对象进行调查或测定,即进行普查时,理论上不存在抽样误差。
步骤 2:考虑其他误差
即使进行普查,也可能存在其他类型的误差,如测量误差或记录误差。
步骤 3:判断正确性
由于普查时不存在抽样误差,但可能存在其他类型的误差,因此该陈述是错误的。
【答案】
错误
35. 95%与99%的参考值范围相比,前者漏诊率大,后者误诊率大。( )
【解析】
步骤 1:理解参考值范围
参考值范围用于判断某一结果是否正常。95%的参考值范围较窄,99%的参考值范围较宽。
步骤 2:理解漏诊率和误诊率
漏诊率是指将正常情况错误地判断为异常,误诊率是指将异常情况错误地判断为正常。
步骤 3:判断正确性
95%的参考值范围较窄,对应的漏诊率较高;99%的参考值范围较宽,对应的误诊率较高。因此,该陈述是正确的。