题目
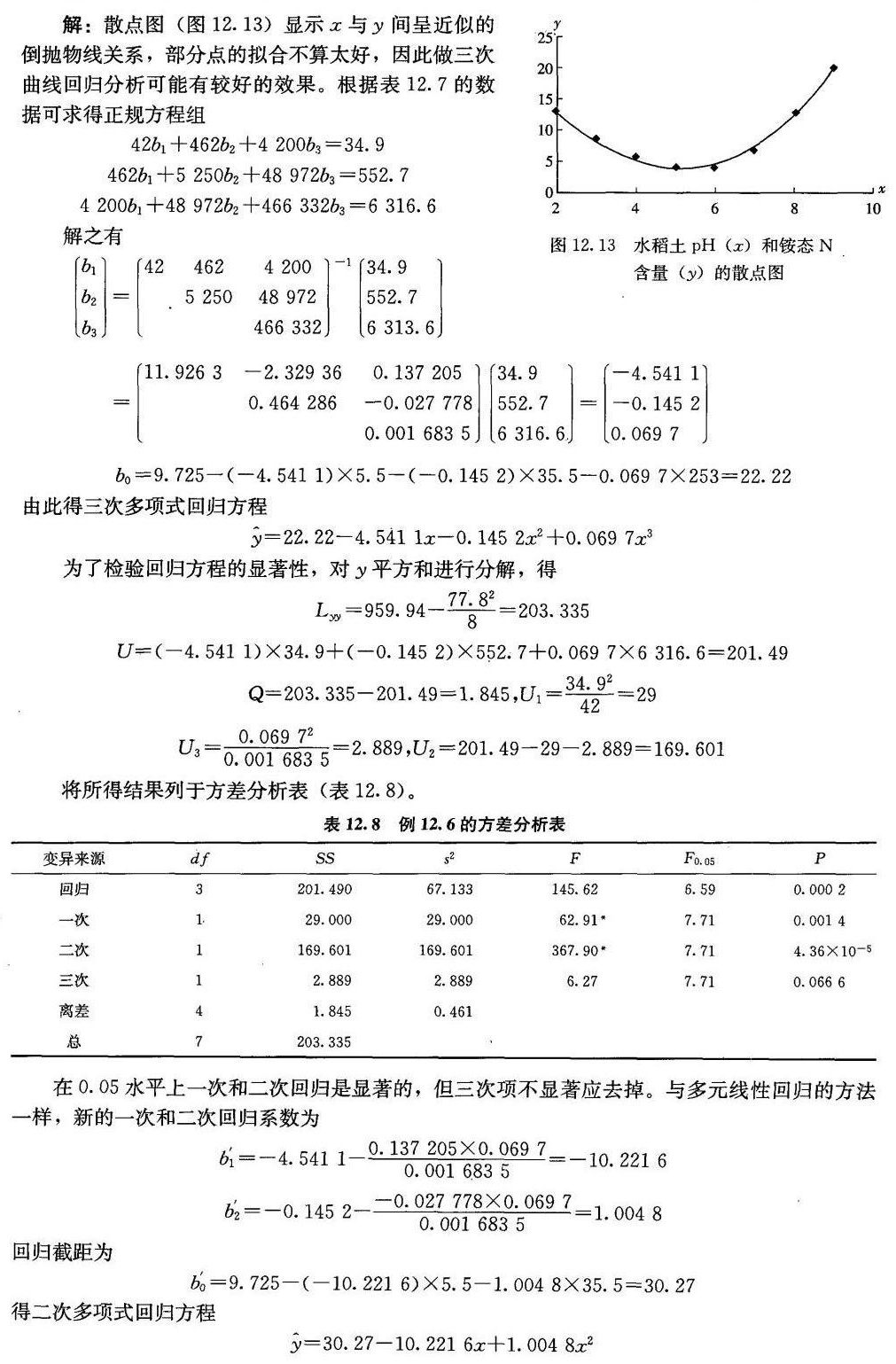
[例12.6]测定某水稻土用HCl和Na2CO33调酸后的pHx和铵态N含量y的结果见表-|||-12.7。试做多项式回归分析。-|||-表12.7某水稻土pHx和铵态N含量y的测定结果-|||-x y x^2 x^3 x^4 x^5 x^6 xy x^2y x^3y y^2-|||-2 13.0 4 8 16 32 64 26.0 52.0 104.0 169.00-|||-x y x^2 x^3 x^4 x^5 x^6 xy x^2y x^3y y^2-|||-3 9.2 9 27 81 243 729 27.6 82.8 284.4 84.64-|||-4 6.6 16 64 256 1024 4096 26.4 105.6 422.4 43.56-|||-5 4.7 25 125 625 3 125 15 625 23.5 117.5 587.5 22.09-|||-6 4.0 36 216 1 296 7 776 46 656 24.0 144.0 864.0 16.00-|||-7 7.1 49 343 2401 16 807 117 649 49.7 347.9 2435.3 50.41-|||-8 13.2 64 512 4 096 32 768 262 144 105.6 844.8 6 758.4 174.24-|||-9 20.0 81 729 6 561 59 049 531 441 180.0 1620.0 14 580.0 400.00-|||-∑ 44 77.8 284 2024 15 332 120 824 978 404 462.8 3 314.6 26000.0 959.94
题目解答
答案
解析
步骤 1:建立多项式回归模型
根据题目给出的数据,我们首先需要建立一个多项式回归模型。多项式回归模型的一般形式为:
\[ y = b_0 + b_1x + b_2x^2 + b_3x^3 + \cdots + b_nx^n \]
其中,\( b_0, b_1, b_2, \ldots, b_n \) 是回归系数,\( x \) 是自变量,\( y \) 是因变量。
步骤 2:计算回归系数
根据题目给出的数据,我们可以通过最小二乘法来计算回归系数。最小二乘法的目标是最小化残差平方和,即:
\[ \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 \]
其中,\( y_i \) 是实际观测值,\( \hat{y}_i \) 是预测值。通过求解线性方程组,我们可以得到回归系数的值。
步骤 3:检验回归方程的显著性
为了检验回归方程的显著性,我们需要对 \( y \) 的平方和进行分解,得到回归平方和 \( U \) 和离差平方和 \( Q \)。然后,通过计算 \( F \) 统计量来检验回归方程的显著性。如果 \( F \) 统计量大于临界值 \( F_{0.05} \),则回归方程在0.05水平上是显著的。
步骤 4:简化回归方程
如果某些回归系数不显著,我们可以去掉这些项,得到简化后的回归方程。简化后的回归方程可以更好地解释数据。
根据题目给出的数据,我们首先需要建立一个多项式回归模型。多项式回归模型的一般形式为:
\[ y = b_0 + b_1x + b_2x^2 + b_3x^3 + \cdots + b_nx^n \]
其中,\( b_0, b_1, b_2, \ldots, b_n \) 是回归系数,\( x \) 是自变量,\( y \) 是因变量。
步骤 2:计算回归系数
根据题目给出的数据,我们可以通过最小二乘法来计算回归系数。最小二乘法的目标是最小化残差平方和,即:
\[ \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 \]
其中,\( y_i \) 是实际观测值,\( \hat{y}_i \) 是预测值。通过求解线性方程组,我们可以得到回归系数的值。
步骤 3:检验回归方程的显著性
为了检验回归方程的显著性,我们需要对 \( y \) 的平方和进行分解,得到回归平方和 \( U \) 和离差平方和 \( Q \)。然后,通过计算 \( F \) 统计量来检验回归方程的显著性。如果 \( F \) 统计量大于临界值 \( F_{0.05} \),则回归方程在0.05水平上是显著的。
步骤 4:简化回归方程
如果某些回归系数不显著,我们可以去掉这些项,得到简化后的回归方程。简化后的回归方程可以更好地解释数据。