题目
用一台自动包装机包装葡萄糖,规定标准每袋净重500克.假定在正常情况下,糖的净重服从正态分布.根据长期资料表明,标准差为15克.现从某一班的产品中随机取出9袋,测得重量为:497 506 518 511 524 510 488 515 512. 问包装机工作是否正常:(1)标准差有无变化?(2)平均重量是否符合规定标准?(α=0.05)
用一台自动包装机包装葡萄糖,规定标准每袋净重500克.假定在正常情况下,糖的净重服从正态分布.根据长期资料表明,标准差为15克.现从某一班的产品中随机取出9袋,测得重量为:497 506 518 511 524 510 488 515 512. 问包装机工作是否正常:(1)标准差有无变化?(2)平均重量是否符合规定标准?(α=0.05)
题目解答
答案
解 待检验的假设是
(1)H : σ2=152,
(2)H : μ=500.
(1)H : σ2=152
选取统计量
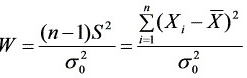 .
.
当H成立时,W~χ2(n-1).
α=0.05,查χ2分布临界值表得临界值
λ1=2.18,λ2=17.535,
由样本值得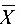 =509,
=509,
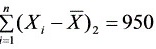 ,
,
W=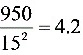 .
.
由于2.18=λ1<W<λ2=17.535.
故H相容,即不能认为标准有显著变化.
(2)H : μ=500
选取统计量
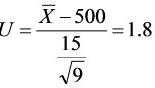 ,当H成立,U~N(0,1).
,当H成立,U~N(0,1).
查表P{|U|>1.96}=0.05,
U=1.8<1.96.
所以H相容.
解析
步骤 1:计算样本均值和样本方差
首先,计算样本均值和样本方差。样本均值$\overline{X}$和样本方差$S^2$的计算公式分别为:
$$\overline{X} = \frac{1}{n}\sum_{i=1}^{n}X_i$$
$$S^2 = \frac{1}{n-1}\sum_{i=1}^{n}(X_i - \overline{X})^2$$
其中,$n$是样本数量,$X_i$是第$i$个样本的重量。
步骤 2:检验标准差是否有变化
选取统计量$W=\dfrac{(n-1)S^2}{{\sigma_0}^2}$,其中$\sigma_0$是已知的标准差。当原假设$H_0: \sigma^2 = {\sigma_0}^2$成立时,$W$服从自由度为$n-1$的卡方分布$\chi^2(n-1)$。根据显著性水平$\alpha=0.05$,查卡方分布表得到临界值$\lambda_1$和$\lambda_2$。如果$W$落在$(\lambda_1, \lambda_2)$区间内,则不能拒绝原假设,即标准差没有显著变化。
步骤 3:检验平均重量是否符合规定标准
选取统计量$U=\dfrac{\overline{X}-\mu_0}{\frac{\sigma_0}{\sqrt{n}}}$,其中$\mu_0$是规定标准重量。当原假设$H_0: \mu = \mu_0$成立时,$U$服从标准正态分布$N(0,1)$。根据显著性水平$\alpha=0.05$,查标准正态分布表得到临界值$z_{\alpha/2}$。如果$|U|
首先,计算样本均值和样本方差。样本均值$\overline{X}$和样本方差$S^2$的计算公式分别为:
$$\overline{X} = \frac{1}{n}\sum_{i=1}^{n}X_i$$
$$S^2 = \frac{1}{n-1}\sum_{i=1}^{n}(X_i - \overline{X})^2$$
其中,$n$是样本数量,$X_i$是第$i$个样本的重量。
步骤 2:检验标准差是否有变化
选取统计量$W=\dfrac{(n-1)S^2}{{\sigma_0}^2}$,其中$\sigma_0$是已知的标准差。当原假设$H_0: \sigma^2 = {\sigma_0}^2$成立时,$W$服从自由度为$n-1$的卡方分布$\chi^2(n-1)$。根据显著性水平$\alpha=0.05$,查卡方分布表得到临界值$\lambda_1$和$\lambda_2$。如果$W$落在$(\lambda_1, \lambda_2)$区间内,则不能拒绝原假设,即标准差没有显著变化。
步骤 3:检验平均重量是否符合规定标准
选取统计量$U=\dfrac{\overline{X}-\mu_0}{\frac{\sigma_0}{\sqrt{n}}}$,其中$\mu_0$是规定标准重量。当原假设$H_0: \mu = \mu_0$成立时,$U$服从标准正态分布$N(0,1)$。根据显著性水平$\alpha=0.05$,查标准正态分布表得到临界值$z_{\alpha/2}$。如果$|U|