某公司共有335量卡车,随机抽取30个卡车样本,每年平均缴纳公路税费均值9540,标准差1205。那么该公司卡车年缴公路税费均值的99%置信区间为z005=2.58 ?A z005=2.58 B z005=2.58C z005=2.58 D z005=2.58E z005=2.58
某公司共有335量卡车,随机抽取30个卡车样本,每年平均缴纳公路税费均值$9540,标准差$1205。那么该公司卡车年缴公路税费均值的99%置信区间为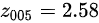 ?
?
A 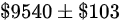
B 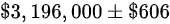
C 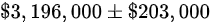
D 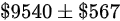
E 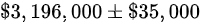
题目解答
答案
要计算该公司卡车年缴公路税费均值的99%置信区间,首先需要使用样本信息以及置信水平的Z值来计算置信区间的范围。
置信区间的计算公式为:

在这里,样本均值 = $9540,标准差 = $1205,样本大小 = 30,Z值 = 2.58(对应于99%的置信水平,可以在标准正态分布表中找到)。
现在,我们可以计算置信区间的范围:
置信区间 = 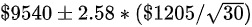
计算出结果:
置信区间 = $9540 ± 2.58 * ($220.79)
置信区间 = $9540 ± $570.98
因此,公司卡车年缴公路税费均值的99%置信区间为 $9540 ± $570.98。
答案选项中最接近的是选项 D:$9540 ± $567,因此答案是选项 D。
解析
考查要点:本题主要考查大样本情况下均值的置信区间计算,涉及Z值的应用和标准误差的计算。
解题核心思路:
- 确定置信区间公式:置信区间 = 样本均值 ± Z值 × 标准误差。
- 计算标准误差:标准误差 = 样本标准差 ÷ √样本量。
- 代入已知数据:样本均值为$9540,标准差为$1205,样本量为30,Z值为2.58(对应99%置信水平)。
- 计算边际误差,最终确定置信区间范围。
破题关键点:
- 区分Z值与t值:样本量≥30时使用Z值。
- 正确计算标准误差:注意分母为样本量的平方根。
- 四舍五入处理:结果需与选项匹配。
步骤1:写出置信区间公式
置信区间 = 样本均值 ± Z值 × 标准误差
其中,标准误差 = 样本标准差 ÷ √样本量。
步骤2:代入已知数据
- 样本均值 $\bar{x} = 9540$
- 样本标准差 $s = 1205$
- 样本量 $n = 30$
- Z值(99%置信水平)$Z_{0.05} = 2.58$
步骤3:计算标准误差
$\text{标准误差} = \frac{1205}{\sqrt{30}} \approx \frac{1205}{5.477} \approx 220.03$
步骤4:计算边际误差
$\text{边际误差} = Z_{0.05} \times \text{标准误差} = 2.58 \times 220.03 \approx 567.67$
步骤5:确定置信区间
$\text{置信区间} = 9540 \pm 567.67 \approx 9540 \pm 568$
步骤6:匹配选项
选项D为$9540 \pm 567$,与计算结果最接近(四舍五入差异),故选D。