题目
设总体approx N(mu ,(sigma )^2) 2已知而approx N(mu ,(sigma )^2) 2为未知参数,approx N(mu ,(sigma )^2) 2是从总体approx N(mu ,(sigma )^2) 2中抽取的样本,记approx N(mu ,(sigma )^2) 2,又approx N(mu ,(sigma )^2) 2表示标准正态分布的分布函数,已知Ф(1.96)=0.975,Ф(1.28)=0.90,则approx N(mu ,(sigma )^2) 2的置信度为0.95的置信区间是( )。A. approx N(mu ,(sigma )^2) 2 B. approx N(mu ,(sigma )^2) 2 C. approx N(mu ,(sigma )^2) 2 D. approx N(mu ,(sigma )^2) 2
设总体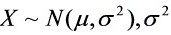 已知而
已知而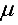 为未知参数,
为未知参数,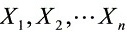 是从总体
是从总体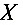 中抽取的样本,记
中抽取的样本,记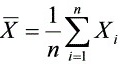 ,又
,又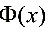 表示标准正态分布的分布函数,已知Ф(1.96)=0.975,Ф(1.28)=0.90,则的置信度为0.95的置信区间是( )。
表示标准正态分布的分布函数,已知Ф(1.96)=0.975,Ф(1.28)=0.90,则的置信度为0.95的置信区间是( )。
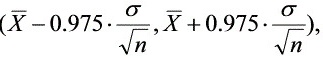
B.
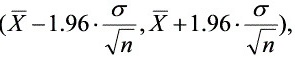
C.
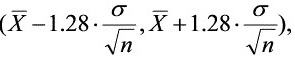
D.
题目解答
答案
区间估计
b
解析
本问题目主要考察的是正态分布总体均值的区间区间估计知识点,具体为当总体方差已知时,如何计算总体均值$\mu$的置信区间。
关键知识点回顾
当总体$X\sim N(\mu,\sigma^2)$且方差$\(\sigma^2$已知已知时,总体均值$\mu$的置信度为$1-\alpha$的置信区间公式为:
$\left( \bar{X} - z_{\alpha/2} \cdot \frac{\sigma}{\}{\sqrt{n}}, \bar{X} + z_{\alpha/2} \cdot \frac{\sigma}{\sqrt{n}} \right)$
其中:
- $\bar{X}$为样本均值,$z_{\alpha/2}$为标准正态分布的上$\alpha/2$分位数,即$P\{Z > z_{\alpha/2}\} = \alpha/2$,$Z\sim N(0,1)$。
题目条件分析
- 置信度为$0.95$,则$1-\alpha=0.95$,故$\alpha=0.05$,$\alpha/2=0.025$。
- 需找到$z_{0.025}$,即满足$P\{Z > z_{0.025\}=0.025$的分位数,等价于$\Phi(z_{0.025})=1-0.025=0.975$。
- 题目已知$\Phi(1.96)=0.975$,故$z_{0.025}=1.96$。
选项匹配匹配,验证
将$z_{\alpha/2}=1.96$代入置信区间公式,得:
$\left( \bar{X - 1.96 \cdot \frac{\sigma}{\sqrt{n}}, \barX + 1.96 \cdot \frac{\sigma}{\sqrt{n}} \right)$
与选项B完全一致。