题目
设总体X服从区间[l,θ]上的均匀分布, theta gt 1 未知,X1,···,x1,是取-|||-自X的样本,则θ的最大似然估计量为

题目解答
答案
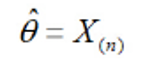
解析
步骤 1:理解均匀分布的似然函数
均匀分布的概率密度函数为$f(x) = \frac{1}{\theta - 1}$,其中$x \in [1, \theta]$。对于样本$X_1, X_2, ..., X_n$,似然函数$L(\theta)$是所有样本点的概率密度函数的乘积,即$L(\theta) = \prod_{i=1}^{n} f(X_i)$。
步骤 2:写出似然函数
由于每个样本点的概率密度函数相同,似然函数可以写为$L(\theta) = (\frac{1}{\theta - 1})^n$,其中$n$是样本数量。注意,这个表达式只有在所有样本点$x_i$都落在区间$[1, \theta]$内时才有效,否则似然函数为0。
步骤 3:确定最大似然估计量
为了使似然函数$L(\theta)$最大,$\theta$应该尽可能小,但同时要保证所有样本点$x_i$都落在区间$[1, \theta]$内。因此,$\theta$的最小可能值是样本中的最大值,即$\theta = X_{(n)}$,其中$X_{(n)}$表示样本中的最大值。
均匀分布的概率密度函数为$f(x) = \frac{1}{\theta - 1}$,其中$x \in [1, \theta]$。对于样本$X_1, X_2, ..., X_n$,似然函数$L(\theta)$是所有样本点的概率密度函数的乘积,即$L(\theta) = \prod_{i=1}^{n} f(X_i)$。
步骤 2:写出似然函数
由于每个样本点的概率密度函数相同,似然函数可以写为$L(\theta) = (\frac{1}{\theta - 1})^n$,其中$n$是样本数量。注意,这个表达式只有在所有样本点$x_i$都落在区间$[1, \theta]$内时才有效,否则似然函数为0。
步骤 3:确定最大似然估计量
为了使似然函数$L(\theta)$最大,$\theta$应该尽可能小,但同时要保证所有样本点$x_i$都落在区间$[1, \theta]$内。因此,$\theta$的最小可能值是样本中的最大值,即$\theta = X_{(n)}$,其中$X_{(n)}$表示样本中的最大值。