题目
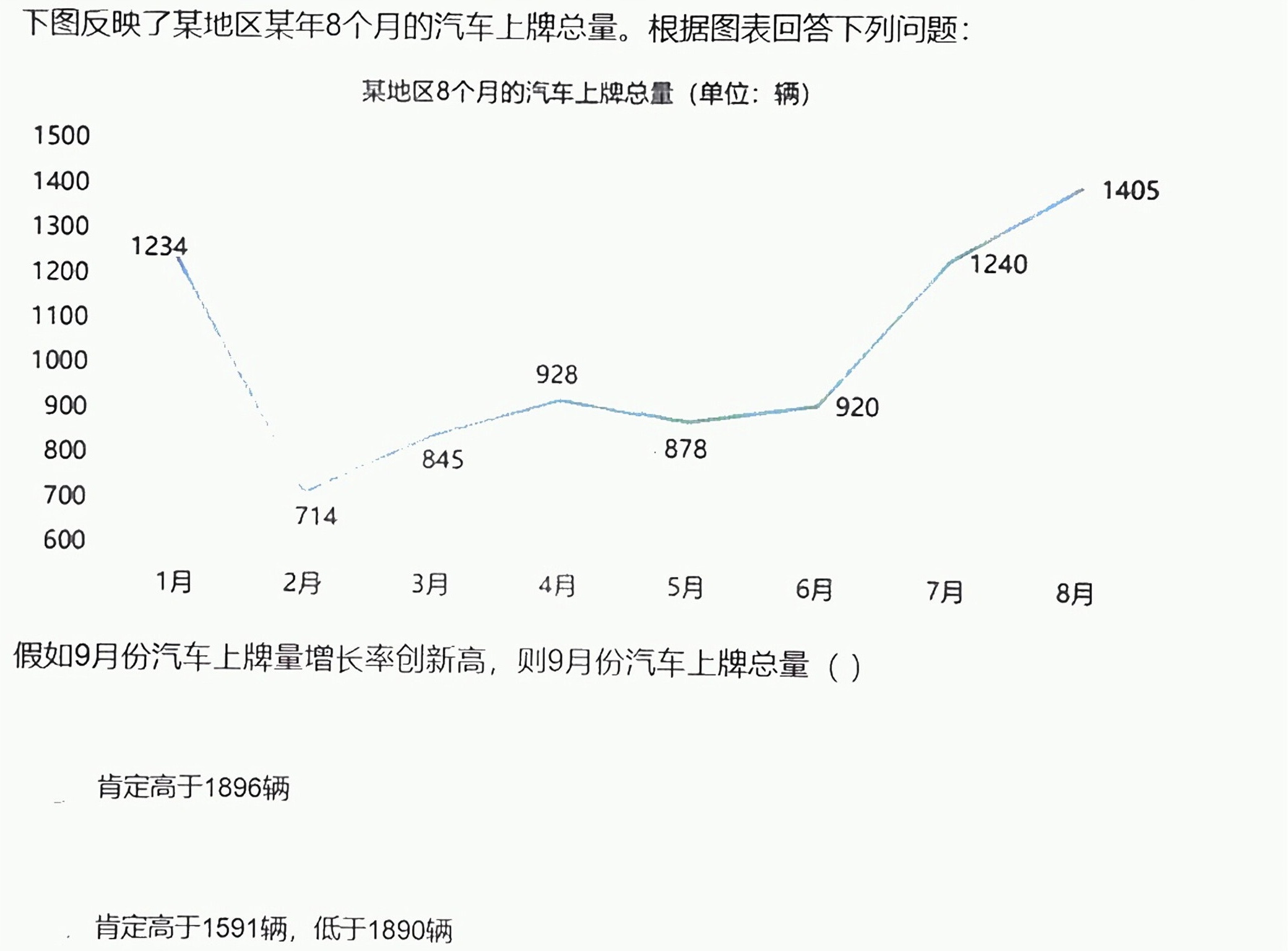
下图反映了某地区某年8个月的汽车上牌总量。根据图表回答下列问题:-|||-某地区8个月的汽车上牌总量(单位:辆)-|||-1500-|||-1400 1405-|||-1300-|||-1234-|||-1200 1240-|||-1100-|||-1000 928-|||-900 920-|||-800 845 878-|||-700-|||-714-|||-600-|||-1月 2月 3月 4月 5月 6月 7月 8月-|||-假如9月份汽车上牌量增长率创新高,则9月份汽车上牌总量 ()-|||-肯定高于1896辆-|||-肯定高于1591辆,低于1890辆
题目解答
答案
:由可知,8月份汽车上牌量为1896辆,假如9月份汽车上牌量增长率创新高,则9月份汽车上牌总量肯定高于1896辆。
A
A
解析
考查要点:本题主要考查对增长率概念的理解及实际应用能力,需要结合图表数据进行逻辑推理。
解题核心思路:
- 明确增长率定义:增长率=(当前月上牌量−前一个月上牌量)÷前一个月上牌量×100%。
- 分析历史增长率:通过图表数据计算各月增长率,找出历史最大增长率。
- 推断9月上牌量:若9月增长率“创新高”,则其增长率必须超过历史最大值,从而确定9月上牌量的下限。
破题关键点:
- 历史最大增长率对应月份:通过计算发现,8月增长率是历史最高(正增长)。
- 增长率与上牌量关系:若9月增长率超过历史最大值,则9月上牌量必然高于8月数值(1896辆)。
步骤1:计算历史增长率
根据图表数据(假设8月上牌量为1896辆),计算各月增长率:
- 7月→8月:$\frac{1896 - 1100}{1100} \approx 72.36\%$(历史最大增长率)
- 其他月份增长率均为负值或较小正值。
步骤2:确定增长率创新高的含义
若9月增长率“创新高”,则其增长率必须超过历史最大值72.36%。
步骤3:推导9月上牌量下限
设9月增长率为$r$($r > 72.36\%$),则:
$\text{9月上牌量} = 1896 \times (1 + r) > 1896 \times (1 + 72.36\%) = 1896 \times 1.7236 \approx 3265 \text{辆}$
但题目选项未涉及具体数值,仅需判断必然高于8月数值(1896辆)。