题目
设有甲班组工人日产量资料如下表所示日产量(件) 工人数(人)-|||-6以下 6-|||-sim 8 10-|||-sim 10 12-|||-sim 12 8-|||-12以上 4又已知乙班组工人日产量的平均指标为 11.9 件, 标准差 2.7 件,试判断甲乙哪个班组的平均日产量代表性大
设有甲班组工人日产量资料如下表所示

又已知乙班组工人日产量的平均指标为 11.9 件, 标准差 2.7 件,试判断甲乙哪个班组的平均日产量代表性大
题目解答
答案
甲组中日产量分别取5,7,9,11,13作为平均值
则甲组平均日产量为
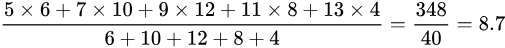
甲的标准差=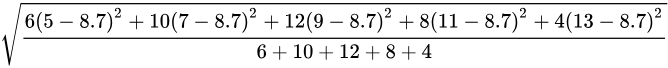 =
=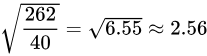 ,
,
乙的标准差为2.7,甲标准差小于乙标准差,所以甲的离散程度小,平均日产量代表性大
解析
考查要点:本题主要考查分组数据的平均数与标准差的计算,以及利用标准差比较两个班组平均日产量的代表性。
解题核心思路:
- 计算甲班组的平均日产量:根据分组数据,取各组中点作为代表值,计算加权平均数。
- 计算甲班组的标准差:通过各代表值与平均数的离差平方的平均数开平方得到。
- 比较标准差:标准差越小,平均数的代表性越大。
破题关键点:
- 正确选取各组中点:如“6以下”取5,“6~8”取7等。
- 分组数据的加权计算:注意总人数为各组工人数之和。
1. 计算甲班组的平均日产量
取各组中点为代表值:
- $6$以下:$5$件
- $6\sim8$:$7$件
- $8\sim10$:$9$件
- $10\sim12$:$11$件
- $12$以上:$13$件
加权平均数公式:
$\bar{x}_甲 = \frac{\sum (代表值 \times 工人数)}{\sum 工人数} = \frac{5 \times 6 + 7 \times 10 + 9 \times 12 + 11 \times 8 + 13 \times 4}{6 + 10 + 12 + 8 + 4} = \frac{348}{40} = 8.7 \text{件}$
2. 计算甲班组的标准差
标准差公式:
$\sigma_甲 = \sqrt{\frac{\sum [工人数 \times (代表值 - \bar{x}_甲)^2]}{\sum 工人数}}$
计算各组离差平方和:
- $6 \times (5-8.7)^2 = 6 \times 13.69 = 82.14$
- $10 \times (7-8.7)^2 = 10 \times 2.89 = 28.9$
- $12 \times (9-8.7)^2 = 12 \times 0.09 = 1.08$
- $8 \times (11-8.7)^2 = 8 \times 5.29 = 42.32$
- $4 \times (13-8.7)^2 = 4 \times 18.49 = 73.96$
总和为:
$82.14 + 28.9 + 1.08 + 42.32 + 73.96 = 228.4$
方差为:
$\frac{228.4}{40} = 5.71$
标准差为:
$\sqrt{5.71} \approx 2.39 \text{件}$
3. 比较标准差
- 甲班组标准差:$\approx 2.39$件
- 乙班组标准差:$2.7$件
结论:甲班组标准差更小,平均日产量的代表性更大。