题目
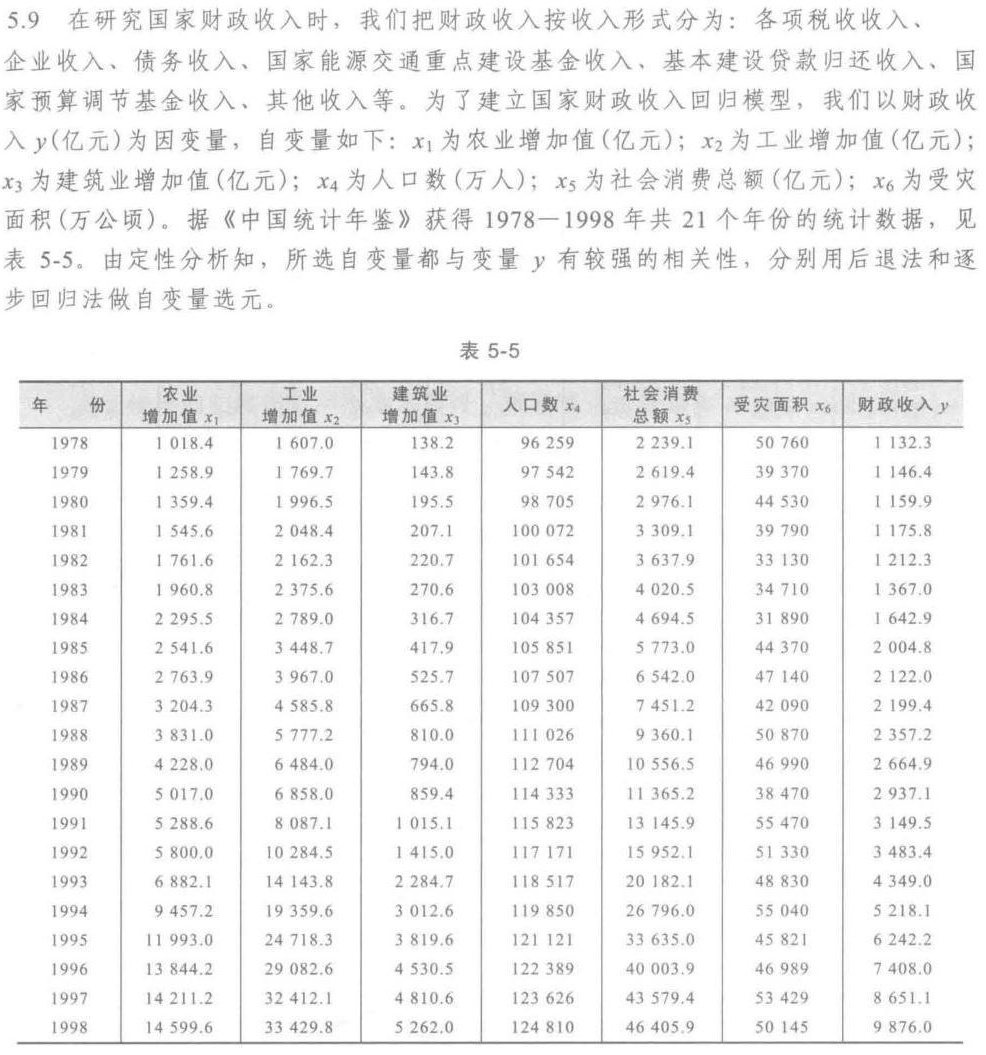
5.9 在研究国家财政收入时,我们把财政收入按收入形式分为:各项税收收入、-|||-企业收入、债务收入、国家能源交通重点建设基金收入、基本建设贷款归还收入、国-|||-家预算调节基金收入、其他收入等。为了建立国家财政收入回归模型,我们以财政收-|||-入y(亿元)为因变量,自变量如下:x1为农业增加值(亿元);x2为工业增加值(亿元);-|||-为建筑业增加值(亿元);x4为人口数(万人);x5为社会消费总额(亿元);x6为受灾-|||-面积(万公顷)。据《中国统计年鉴》获得 1978-1998 年共21个年份的统计数据,见-|||-5-5。 由定性分析知,所选自变量都与变量y有较强的相关性,分别用后退法和逐-|||-步回归法做自变量选元。-|||-表 5-5-|||-年 份 增加值x1 增加值x2 增加值x3 人口数x4 社会消费 受灾面积x6 财政收入y-|||-农业 工业 建筑业-|||-总额x5-|||-1978 1018.4 1607.0 138.2 96 259 2 239.1 50 760 1 132.3-|||-1979 1258.9 1769.7 143.8 97 542 2619.4 39 370 1 146.4-|||-1980 1 359.4 1996.5 195.5 98 705 2976.1 44 530 1 159.9-|||-1981 1545.6 2048.4 207.1 100 072 3 309.1 39 790 1 175.8-|||-1982 1761.6 2 162.3 220.7 101 654 3 637.9 33 130 1 212.3-|||-1983 1960.8 2 375.6 270.6 103 008 4020.5 34 710 1 367.0-|||-1984 2 295.5 2789.0 316.7 104 357 4694.5 31 890 1642.9-|||-1985 2541.6 3448.7 417.9 105 851 5 773.0 44 370 2004.8-|||-1986 2763.9 3967.0 525.7 107 507 6 542.0 47 140 2 122.0-|||-1987 3 204.3 4585.8 665.8 109 300 7451.2 42 090 2 199.4-|||-1988 3 831.0 5 777.2 810.0 111026 9 360.1 50 870 2 357.2-|||-1989 4228.0 6484.0 794.0 112704 10 556.5 46 990 2664.9-|||-1990 5017.0 6 858.0 859.4 114 333 11 365.2 38 470 2 937.1-|||-1991 5288.6 8087.1 1015.1 115 823 13 145.9 55 470 3 149.5-|||-1992 5 800.0 10 284.5 1415.0 117 171 15 952.1 51 330 3483.4-|||-1993 6 882.1 14 143.8 2 284.7 118517 20 182.1 48 830 4 349.0-|||-1994 9457.2 19 359.6 3 012.6 119 850 26796.0 55 040 5 218.1-|||-1995 11 993.0 24 718.3 3 819.6 121 121 33 635.0 45 821 6 242.2-|||-1996 13 844.2 29 082.6 4 530.5 122 389 40 003.9 46 989 7408.0-|||-1997 14 211.2 32 412.1 4810.6 123 626 43 579.4 53 429 8 651.1-|||-1998 14 599.6 33 429.8 5 262.0 124 810 46405.9 50 145 9 876.0-|||-1998
题目解答
答案

解析
考查要点:本题主要考查多元回归分析中的变量选择方法(后退法、逐步回归法)及其结果的合理性判断。
解题核心思路:
- 后退法:从包含所有变量的模型开始,逐步剔除对模型贡献不显著的变量,最终保留显著变量。
- 逐步回归法:通过变量的加入与剔除迭代,最终确定最优变量组合。
- 模型合理性:需结合实际经济意义检验回归系数符号是否合理。
破题关键:
- 明确两种方法的变量筛选逻辑差异。
- 通过回归系数的经济意义验证模型是否合理(如农业、工业增加值应正向影响财政收入)。
后退法与逐步回归结果对比
-
后退法过程:
- 初始模型包含所有变量 $x_1, x_2, x_3, x_4, x_5, x_6$。
- 逐步剔除不显著变量:$x_4$(人口数)→ $x_3$(建筑业增加值)→ $x_6$(受灾面积)。
- 最终保留变量:$x_1$(农业增加值)、$x_2$(工业增加值)、$x_5$(社会消费总额)。
-
逐步回归过程:
- 通过变量加入与剔除的迭代,最终结果与后退法一致,保留 $x_1, x_2, x_5$。
模型合理性分析
最终回归方程为:
$\hat{y} = 874.60 - 0.61x_1 - 0.35x_2 + 0.64x_5$
- $x_1$(农业增加值):系数为负,与实际不符(农业增长应促进财政收入)。
- $x_2$(工业增加值):系数为负,同样违背经济直觉(工业增长通常增加财政收入)。
- $x_5$(社会消费总额):系数为正,符合预期(消费活跃促进经济增长)。
结论:模型中 $x_1$ 和 $x_2$ 的系数符号不合理,可能由多重共线性或数据特性导致,需进一步诊断。