题目
名词解释Δ 总体与样本(population and sample):A. 根据研究目的确定的同质研究对象的全体(集合)。总体具有特定的分布特征及参数。分有限总体与无限总体; B. 从总体中随机抽取的部分观察单位; C. More:根据研究目的,从总体中抽取部分有代表性的样本,用样本统计量推断总体参数。 D. ndard deviation standard error): E. s: 表示单个测量值对其均数(I PA)的离散程度,; F. I PA:表示样本统计量对总体参数的离散程度,; G. More:标准差越大,标准误越小; 标准差用于描述观测值变异范围;标准误用来推断估计总体参数的可信区间和假设检验; 计算公式: 变量值标准差I PA样本均数标准误 I PA 阳性结果标准差I PA 样本阳性率的标准误I PA。 Δ Ⅰ型错误和Ⅱ型错误(typeⅠ error type Ⅱ error): Ⅰ:在假设检验中拒绝一个实际成立的原假设所犯的错误,其概率记为α; Ⅱ:在假设检验中接受了一个实际不成立的原假设所犯的错误,其概率记为β; More:假设检验中,无论是接受还是拒绝原假设均有可能犯错。当样本含量确定时,α越大,则β越小,反之,α越小β越大。增大样本量可同时减低α和β。 Δ I PA与I PA: I PA:从正态总体中抽样,样本含量较大时,观测值为95%的波动范围; I PA:从正态总体中抽样,样本含量较大时,总体均数95%的可信区间; qualitative data): (定量、数值变量):每个观察对象通过定量测定的方法都有一个确切的值,通常有单位,但也有例外(例如:淋巴细胞转化率)。EG: 医学中:身高、体重、血压、血红蛋白值等; (定性、分类变量):按照研究对象的某个特征进行分组,然后分组计数所获得的资料。EG:男 25 女35;等级分组资料(计数资料的一种):按照程度递增或递减。EG:癌症分期:早、中、晚; More:判断资料类型的标准:看每个观察对象是否有一个确切的值,有:计量;无:计数;计量资料、计数资料和等级分组资料不可以相互转化,只能高级向低级转化(高精度向低精度)。 ndom design paired design): 将同质的受试对象随机分到各处理组中进行试验观察或从不同总体中随机抽样进行对比的方法; 将受试对象按某些特征或条件配成对子,然后分别把每对中的两个受试对象随机分配到试验组和对照组,再给予每对中的个体以不同处理,连续试验若干对,观察对子间的差别有无意义的方法。 tion interval estimation): 直接用随机样本均数I PA作为总体均数μ的一个估计,用样本的标准差S作为总体标准差σ的一个估计,即直接用样本统计量I PA的估计值; 按预先给定的概率(1-α)用一个区间来估计总体均数,这个区间成为可信度(1-α)的可信区间(CI)或置信区间,预选给定的(1-α)称为可信度获置信度,常取95%或99%。 Δ 构成比与率: 某事物内部各部分所占的比例或比重,与时间单位无关; 单位时间内某事件发生的可能性大小(频率或概率),与事件单位有关,有速度和强度的含义; More:构成比和率是描述计数资料两个常用的指标。 Δ 小概念事件和小概率原理: 将P≤0.05或P≤0.01的事件称为小概率事件,统计学上认为不大可能发生。 在一次试验或一次抽样中当做不发生。 Δ 直线相关和直线回归: Y给定X=X的条件下服从正态分布;X是可以精确测量和严格控制的变量,一般称为Ⅰ型回归。直线相关要求两个变量X,Y服从双变量正态分布,这种资料若进行回归分析称为Ⅱ型回归。可以计算两个回归方程。②统计量:回归分析中主要统计量为截距a和回归系数b,相关分析统计量为系数r;回归系数有单位,相关系数无单位。③应用:相关分析主要是描述两个变量之间线性关系的密切程度和方向;回归分析说明两变量间依存变化的数量关系,不仅可以揭示变量x对变量y的影响大小,还可以有回归方程进行预测和控制。 联系:①r与b符号一致,对一组数据若同时计算r与b,它们的正负号是一致的。②假设检验等价,对同一样本,r和b的假设检验得到的t相等。用回归解释相关r的平方称为决定系数,I PA Δ b 与 r: 概念:b为样本直线回归系数,r为样本直线相关系数; 公式:I PA I PA; 统计学意义:b:当x变化一个单位时y的平均改变的估计值b>0.y随x上升而上升,b<0,y随x的上升而下降; 条件:b 双变量正态分布或y为正态分布; r 双变量正态分布。 P与α: P:由原假设H所规定的总体做同样的重复试验,获得等于及大于(或等于及小于)当前检验统计量的概率; α:即检验水准(显著性水准),是预先规定的判断小概率事件的概率尺度,通常规定为0.05或0.01; More:假设检验规定:如果一次实验结果P≤α,拒绝H,统计结论为“差别有统计学意义”;P>α,则不拒绝H,统计学结论为“差别没有统计学意义”。 Δ 系统误差与随机误差: 在一定条件下,由于某种(受试对象、研究者或实验条件)偏因使得观测值出现的倾向性的偏差,表现为恒定偏大或偏小或周期性变化,是不可消除的; 即偶然误差,指在排除了系统误差后仍然存在的由一些有关实验因素微小的随机波动引起的方向不定又不可相互抵偿的误差,该误差决定了测量的精密度。一次测量中,随机误差的大小与方向不可预言,但大量重复测定中,随机误差的出现具有统计规律性。 te prevalence rate): 表示在某一时期内特定人群中患某病新病例的频率,计算公式为:某病发病率=(某时期某病新病例数/同期间内平均人口数)×比例基数 也称现患率,表示某一时点某人群中患某病的频率,计算公式为:某病患病率=(某地某时点某病患病例数/该地同期内平均人口数)×比例基数 use fatality cure rate): 表示某期间内,某病患者中因某病死亡的频率,计算公式为:某病病死率=(某期间因某病死亡人数/同期某病的患病人数)×100% 表示接受治疗的病人中治愈的频率,计算公式为:治愈率=(治愈病人数/接受治疗病人数)×100% 填空 Δ 抽样误差是指 随机误差或偶然误差,是指在排除了系统误差后任然存在的由一些有关实验因素微小的随机波动引起的方向不定又可相互抵偿的误差,该误差决定了测量的精密度。一次测量中,随机误差的大小与方向不可预言,但大量重复的测定中,随机误差的出现具有统计规律性。 Δ 科研设计时,估计样本含量的先决条件是Ⅰ类错误概率的大小、Ⅱ错误概率的大小与容许误差和总体标准差或总体率。 Δ 实验设计基本原则是对照原则、随机原则与重复原则。 Δ 实验设计的基本要素是 设置处理因素、受试对象、实验效应。 Δ 为了满足统计方法的应用条件,有时需要对原始变量进行一定形式的数据变换,其目的是 偏态正态化、曲线直线化、方差齐性。 Δ 反映原始测定数据对其均值离散程度的统计量用 标准差 ;表达样本统计量对其参数随机偏离程度的统计量是 标准误。 Δ 已知某医院统计资料服从正态分布,且其n=400,I PA=30,s=5,据此可估计其中95%的数据波动范围是 I PA,其总体均数95%的可信区间为I PA。 Δ 对一对同质的计量资料,通常可以从 集中趋势 和 离散程度 两个方面来全面描述其数字特征。 Δ 对于一份统计资料,通常从统计描述与统计推断两个方面进行分析,其中统计推断包括 参数估计 和 假设检验 两个方面的内容。 Δ 对计数资料进行统计描述通常采用相对数指标,常用的相对数指标有 率、 构成比 和 相对比。 Δ 医学统计工作的内容是 实验设计、收集资料、整理资料、分析资料。统计分析常分为统计描述与统计推断两个阶段。 Δ 常用的制定医学正常值范围(参考值范围)的方法有 百分位数法 和 正态分布法 两种,一般前者适用于 偏态 分布资料,后者适用于 正态 分布资料。 Δ 计量资料作假设检验要求资料必须满足正态性和方差齐性,如果数据不能满足方差齐性要求,一般可以通过t’检验 变量交换和秩和检验三条途径来处理资料。 Δ 估计总体参数的方法有 点估计 和 区间估计,其中以 区间估计 最常用。 Δ 总体均数可信区间估计的理论基础是样本均数的抽样分布规律。 P >0.05 ,应该 不拒绝 H(,可认为两样本均数间的差异 无统计学意义; 若|t|>t0.05,ν),则P <0.05 ,应该 拒绝 H(,可认为两样本均数间的差异 有显著性。 Δ 欲了解两个变量之间相互关系的密切程度和方向性,一般常计算的统计量是相关系数r。 Δ 了解两个变量之间相互关系的密切程度和方向性,一般常计算的统计量是 r。 Δ 识别资料的类型很重要,不同的资料类型需要用不同的统计方法去分析,医学统计资料一般分为计量资料,计数资料和等级分组资料。 S反映 一组实测数据的变异大小 ,标准误I PA反映 一个样本抽样误差的大小。 Δ 现有两样本均数I PA1=169.5和I PA2=173.2,从统计学的观点看造成这两个均数存在差异的可能原因是抽样误差,或总体本质差异两方面。 Δ 直线回归分析中的最小二乘法原理指散点到直线纵向距离的平方和达到最小。 P<0.05 ,应 拒绝 H2,可认为两样本率的差异 有统计学意义。 P值的含义是 从原假设成立的总体随机抽样,获得大于等于或小于等于现有样本信息统计量的概率。 Δ 均数抽样误差大小可用 I PA 来反映,率的抽样误差大小可用 I PA 来表示。 S逐渐趋向于σ,逐渐趋向于0。 Δ 变异系数常用于比较单位不同或均数相差较大情况下两组资料的变异度。 Δ 相关分析侧重于考察变量之间相关关系密切程度,回归分析则侧重于考察变量之间数量变化规律。
名词解释
Δ 总体与样本(population and sample):
A. 根据研究目的确定的同质研究对象的全体(集合)。总体具有特定的分布特征及参数。分有限总体与无限总体;B. 从总体中随机抽取的部分观察单位;
C. More:根据研究目的,从总体中抽取部分有代表性的样本,用样本统计量推断总体参数。
D. ndard deviation standard error):
E. s: 表示单个测量值对其均数(
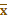 )的离散程度,;
)的离散程度,;F.
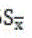 :表示样本统计量对总体参数的离散程度,;
:表示样本统计量对总体参数的离散程度,;G. More:标准差越大,标准误越小; 标准差用于描述观测值变异范围;标准误用来推断估计总体参数的可信区间和假设检验; 计算公式: 变量值标准差
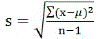 样本均数标准误
样本均数标准误 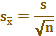 阳性结果标准差
阳性结果标准差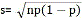 样本阳性率的标准误
样本阳性率的标准误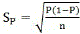 。
。Δ Ⅰ型错误和Ⅱ型错误(typeⅠ error type Ⅱ error):
Ⅰ:在假设检验中拒绝一个实际成立的原假设所犯的错误,其概率记为α;
Ⅱ:在假设检验中接受了一个实际不成立的原假设所犯的错误,其概率记为β;
More:假设检验中,无论是接受还是拒绝原假设均有可能犯错。当样本含量确定时,α越大,则β越小,反之,α越小β越大。增大样本量可同时减低α和β。
Δ
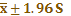 与
与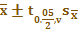 ::从正态总体中抽样,样本含量较大时,观测值为95%的波动范围;:从正态总体中抽样,样本含量较大时,总体均数95%的可信区间;
::从正态总体中抽样,样本含量较大时,观测值为95%的波动范围;:从正态总体中抽样,样本含量较大时,总体均数95%的可信区间;qualitative data):
(定量、数值变量):每个观察对象通过定量测定的方法都有一个确切的值,通常有单位,但也有例外(例如:淋巴细胞转化率)。EG: 医学中:身高、体重、血压、血红蛋白值等;
(定性、分类变量):按照研究对象的某个特征进行分组,然后分组计数所获得的资料。EG:男 25 女35;等级分组资料(计数资料的一种):按照程度递增或递减。EG:癌症分期:早、中、晚;
More:判断资料类型的标准:看每个观察对象是否有一个确切的值,有:计量;无:计数;计量资料、计数资料和等级分组资料不可以相互转化,只能高级向低级转化(高精度向低精度)。
ndom design paired design):
将同质的受试对象随机分到各处理组中进行试验观察或从不同总体中随机抽样进行对比的方法;
将受试对象按某些特征或条件配成对子,然后分别把每对中的两个受试对象随机分配到试验组和对照组,再给予每对中的个体以不同处理,连续试验若干对,观察对子间的差别有无意义的方法。
tion interval estimation):
直接用随机样本均数
作为总体均数μ的一个估计,用样本的标准差S作为总体标准差σ的一个估计,即直接用样本统计量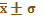 的估计值;
的估计值;按预先给定的概率(1-α)用一个区间来估计总体均数,这个区间成为可信度(1-α)的可信区间(CI)或置信区间,预选给定的(1-α)称为可信度获置信度,常取95%或99%。
Δ 构成比与率:
某事物内部各部分所占的比例或比重,与时间单位无关;
单位时间内某事件发生的可能性大小(频率或概率),与事件单位有关,有速度和强度的含义;
More:构成比和率是描述计数资料两个常用的指标。
Δ 小概念事件和小概率原理:
将P≤0.05或P≤0.01的事件称为小概率事件,统计学上认为不大可能发生。
在一次试验或一次抽样中当做不发生。
Δ 直线相关和直线回归:
Y给定X=X的条件下服从正态分布;X是可以精确测量和严格控制的变量,一般称为Ⅰ型回归。直线相关要求两个变量X,Y服从双变量正态分布,这种资料若进行回归分析称为Ⅱ型回归。可以计算两个回归方程。②统计量:回归分析中主要统计量为截距a和回归系数b,相关分析统计量为系数r;回归系数有单位,相关系数无单位。③应用:相关分析主要是描述两个变量之间线性关系的密切程度和方向;回归分析说明两变量间依存变化的数量关系,不仅可以揭示变量x对变量y的影响大小,还可以有回归方程进行预测和控制。
联系:①r与b符号一致,对一组数据若同时计算r与b,它们的正负号是一致的。②假设检验等价,对同一样本,r和b的假设检验得到的t相等。用回归解释相关r的平方称为决定系数,

Δ b 与 r:
概念:b为样本直线回归系数,r为样本直线相关系数;
公式:

 ;
;统计学意义:b:当x变化一个单位时y的平均改变的估计值b>0.y随x上升而上升,b<0,y随x的上升而下降;
条件:b 双变量正态分布或y为正态分布; r 双变量正态分布。
P与α:
P:由原假设H所规定的总体做同样的重复试验,获得等于及大于(或等于及小于)当前检验统计量的概率;
α:即检验水准(显著性水准),是预先规定的判断小概率事件的概率尺度,通常规定为0.05或0.01;
More:假设检验规定:如果一次实验结果P≤α,拒绝H,统计结论为“差别有统计学意义”;P>α,则不拒绝H,统计学结论为“差别没有统计学意义”。
Δ 系统误差与随机误差:
在一定条件下,由于某种(受试对象、研究者或实验条件)偏因使得观测值出现的倾向性的偏差,表现为恒定偏大或偏小或周期性变化,是不可消除的;
即偶然误差,指在排除了系统误差后仍然存在的由一些有关实验因素微小的随机波动引起的方向不定又不可相互抵偿的误差,该误差决定了测量的精密度。一次测量中,随机误差的大小与方向不可预言,但大量重复测定中,随机误差的出现具有统计规律性。
te prevalence rate):
表示在某一时期内特定人群中患某病新病例的频率,计算公式为:某病发病率=(某时期某病新病例数/同期间内平均人口数)×比例基数
也称现患率,表示某一时点某人群中患某病的频率,计算公式为:某病患病率=(某地某时点某病患病例数/该地同期内平均人口数)×比例基数
use fatality cure rate):
表示某期间内,某病患者中因某病死亡的频率,计算公式为:某病病死率=(某期间因某病死亡人数/同期某病的患病人数)×100%
表示接受治疗的病人中治愈的频率,计算公式为:治愈率=(治愈病人数/接受治疗病人数)×100%
填空
Δ 抽样误差是指 随机误差或偶然误差,是指在排除了系统误差后任然存在的由一些有关实验因素微小的随机波动引起的方向不定又可相互抵偿的误差,该误差决定了测量的精密度。一次测量中,随机误差的大小与方向不可预言,但大量重复的测定中,随机误差的出现具有统计规律性。
Δ 科研设计时,估计样本含量的先决条件是Ⅰ类错误概率的大小、Ⅱ错误概率的大小与容许误差和总体标准差或总体率。
Δ 实验设计基本原则是对照原则、随机原则与重复原则。
Δ 实验设计的基本要素是 设置处理因素、受试对象、实验效应。
Δ 为了满足统计方法的应用条件,有时需要对原始变量进行一定形式的数据变换,其目的是 偏态正态化、曲线直线化、方差齐性。
Δ 反映原始测定数据对其均值离散程度的统计量用 标准差 ;表达样本统计量对其参数随机偏离程度的统计量是 标准误。
Δ 已知某医院统计资料服从正态分布,且其n=400,
=30,s=5,据此可估计其中95%的数据波动范围是 ,其总体均数95%的可信区间为 。
。Δ 对一对同质的计量资料,通常可以从 集中趋势 和 离散程度 两个方面来全面描述其数字特征。
Δ 对于一份统计资料,通常从统计描述与统计推断两个方面进行分析,其中统计推断包括 参数估计 和 假设检验 两个方面的内容。
Δ 对计数资料进行统计描述通常采用相对数指标,常用的相对数指标有 率、 构成比 和 相对比。
Δ 医学统计工作的内容是 实验设计、收集资料、整理资料、分析资料。统计分析常分为统计描述与统计推断两个阶段。
Δ 常用的制定医学正常值范围(参考值范围)的方法有 百分位数法 和 正态分布法 两种,一般前者适用于 偏态 分布资料,后者适用于 正态 分布资料。
Δ 计量资料作假设检验要求资料必须满足正态性和方差齐性,如果数据不能满足方差齐性要求,一般可以通过t’检验 变量交换和秩和检验三条途径来处理资料。
Δ 估计总体参数的方法有 点估计 和 区间估计,其中以 区间估计 最常用。
Δ 总体均数可信区间估计的理论基础是样本均数的抽样分布规律。
P >0.05 ,应该 不拒绝 H(,可认为两样本均数间的差异 无统计学意义; 若|t|>t0.05,ν),则P <0.05 ,应该 拒绝 H(,可认为两样本均数间的差异 有显著性。
Δ 欲了解两个变量之间相互关系的密切程度和方向性,一般常计算的统计量是相关系数r。
Δ 了解两个变量之间相互关系的密切程度和方向性,一般常计算的统计量是 r。
Δ 识别资料的类型很重要,不同的资料类型需要用不同的统计方法去分析,医学统计资料一般分为计量资料,计数资料和等级分组资料。
S反映 一组实测数据的变异大小 ,标准误
 反映 一个样本抽样误差的大小。
反映 一个样本抽样误差的大小。Δ 现有两样本均数
1=169.5和2=173.2,从统计学的观点看造成这两个均数存在差异的可能原因是抽样误差,或总体本质差异两方面。Δ 直线回归分析中的最小二乘法原理指散点到直线纵向距离的平方和达到最小。
P<0.05 ,应 拒绝 H2,可认为两样本率的差异 有统计学意义。
P值的含义是 从原假设成立的总体随机抽样,获得大于等于或小于等于现有样本信息统计量的概率。
Δ 均数抽样误差大小可用
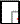 来反映,率的抽样误差大小可用
来反映,率的抽样误差大小可用  来表示。
来表示。S逐渐趋向于σ,逐渐趋向于0。
Δ 变异系数常用于比较单位不同或均数相差较大情况下两组资料的变异度。
Δ 相关分析侧重于考察变量之间相关关系密切程度,回归分析则侧重于考察变量之间数量变化规律。
题目解答
答案
宁可累死在路上,也不能闲死在家里!宁可去碰壁,也不能面壁。是狼就要练好牙,是羊就要练好腿。什么是奋斗?奋斗就是每天很难,可一年一年却越来越容易。不奋斗就是每天都很容易,可一年一年越来越难。能干的人,不在情绪上计较,只在做事上认真;无能的人!不在做事上认真,只在情绪上计较。拼一个春夏秋冬!赢一个无悔人生!早安!—————献给所有努力的人.