题目
设随机变量 sim t(n), 求证 ^2sim F(1,n).
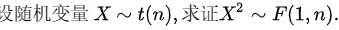
题目解答
答案
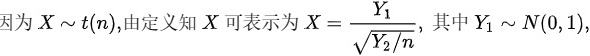
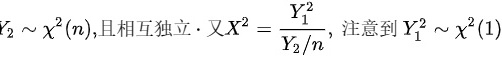
由F分布的定义可知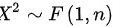
得证。
解析
考查要点:本题主要考查对t分布和F分布定义的理解,以及如何通过变量变换推导分布关系。
解题核心思路:
- 利用t分布的定义,将随机变量$X$表示为标准正态变量与卡方变量的组合形式。
- 平方后构造F分布的结构,即分子为卡方变量除以自由度,分母为另一卡方变量除以自由度的比值。
- 验证独立性,确保分子和分母对应的变量相互独立。
破题关键点:
- 明确$t(n)$分布的表达式中涉及的变量独立性。
- 识别平方后的表达式符合$F(1,n)$分布的定义形式。
步骤1:写出t分布的定义形式
由题意,$X \sim t(n)$可表示为:
$X = \dfrac{Y_1}{\sqrt{Y_2 / n}}$
其中,$Y_1 \sim N(0,1)$,$Y_2 \sim \chi^2(n)$,且$Y_1$与$Y_2$独立。
步骤2:对$X$平方并变形
计算$X^2$:
$X^2 = \left( \dfrac{Y_1}{\sqrt{Y_2 / n}} \right)^2 = \dfrac{Y_1^2}{Y_2 / n}$
步骤3:分析分子和分母的分布
- 分子部分:$Y_1^2 \sim \chi^2(1)$(标准正态变量的平方服从自由度为1的卡方分布)。
- 分母部分:$Y_2 / n$是自由度为$n$的卡方变量除以自由度。
步骤4:构造F分布的形式
根据$F$分布的定义,若
$F = \dfrac{U/m}{V/n}$
其中$U \sim \chi^2(m)$,$V \sim \chi^2(n)$且独立,则$F \sim F(m,n)$。
将$X^2$与上述形式对比:
$X^2 = \dfrac{Y_1^2 / 1}{Y_2 / n}$
此时,分子自由度$m=1$,分母自由度$n=n$,且$Y_1^2$与$Y_2$独立。因此,$X^2 \sim F(1,n)$。