题目
周日早晨,顾客到达面包店的平均速度是每小时16位。到达分布能够用均值为16的泊松分布表示。每个店员能够在平均3分钟内接待一名顾客;服务时间基本符合均值为3分钟的指数分布,并用Excel求解。(1)到达速度和服务速度是多少?(2)计算同时接受服务的顾客平均数?(3)假设队中等候的顾客平均数是3.2,计算系统中的顾客平均数(即排队等候的和接受服务的之和)、顾客平均排队等候时间以及花费在系统中的平均时间?(4)求当M=1、2与3时的系统利用率。
周日早晨,顾客到达面包店的平均速度是每小时16位。到达分布能够用均值为16的泊松分布表示。每个店员能够在平均3分钟内接待一名顾客;服务时间基本符合均值为3分钟的指数分布,并用Excel求解。
(1)到达速度和服务速度是多少?
(2)计算同时接受服务的顾客平均数?
(3)假设队中等候的顾客平均数是3.2,计算系统中的顾客平均数(即排队等候的和接受服务的之和)、顾客平均排队等候时间以及花费在系统中的平均时间?
(4)求当M=1、2与3时的系统利用率。
题目解答
答案
答案:(1)问题中已经给出了到达速度 ג =16为顾客/小时;µ=20位顾客/小时。
(2)0.80位顾客/小时。
(3) Ls= Lq+ r=3.2+0.8=4.0位顾客
Wq=0.20小时/顾客,或0.20小时×60分钟/小时=12分钟
Ws=0.25小时,或15分钟
(4)当M=1时,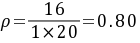
当M=2时,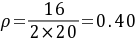
当M=3时,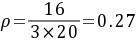
解析
步骤 1:确定到达速度和服务速度
根据题目,顾客到达面包店的平均速度是每小时16位,即到达速度 λ = 16位顾客/小时。每个店员能够在平均3分钟内接待一名顾客,即服务速度 μ = 60分钟/3分钟 = 20位顾客/小时。
步骤 2:计算同时接受服务的顾客平均数
根据排队论中的公式,同时接受服务的顾客平均数 r = λ / μ = 16 / 20 = 0.80位顾客/小时。
步骤 3:计算系统中的顾客平均数、顾客平均排队等候时间以及花费在系统中的平均时间
已知队中等候的顾客平均数 Lq = 3.2,根据排队论中的公式,系统中的顾客平均数 Ls = Lq + r = 3.2 + 0.8 = 4.0位顾客。顾客平均排队等候时间 Wq = Lq / λ = 3.2 / 16 = 0.20小时/顾客,或0.20小时×60分钟/小时=12分钟。花费在系统中的平均时间 Ws = Ls / λ = 4.0 / 16 = 0.25小时,或15分钟。
步骤 4:计算当M=1、2与3时的系统利用率
系统利用率 ρ = λ / (M × μ),其中M为店员数量。当M=1时,ρ = 16 / (1 × 20) = 0.80;当M=2时,ρ = 16 / (2 × 20) = 0.40;当M=3时,ρ = 16 / (3 × 20) = 0.27。
根据题目,顾客到达面包店的平均速度是每小时16位,即到达速度 λ = 16位顾客/小时。每个店员能够在平均3分钟内接待一名顾客,即服务速度 μ = 60分钟/3分钟 = 20位顾客/小时。
步骤 2:计算同时接受服务的顾客平均数
根据排队论中的公式,同时接受服务的顾客平均数 r = λ / μ = 16 / 20 = 0.80位顾客/小时。
步骤 3:计算系统中的顾客平均数、顾客平均排队等候时间以及花费在系统中的平均时间
已知队中等候的顾客平均数 Lq = 3.2,根据排队论中的公式,系统中的顾客平均数 Ls = Lq + r = 3.2 + 0.8 = 4.0位顾客。顾客平均排队等候时间 Wq = Lq / λ = 3.2 / 16 = 0.20小时/顾客,或0.20小时×60分钟/小时=12分钟。花费在系统中的平均时间 Ws = Ls / λ = 4.0 / 16 = 0.25小时,或15分钟。
步骤 4:计算当M=1、2与3时的系统利用率
系统利用率 ρ = λ / (M × μ),其中M为店员数量。当M=1时,ρ = 16 / (1 × 20) = 0.80;当M=2时,ρ = 16 / (2 × 20) = 0.40;当M=3时,ρ = 16 / (3 × 20) = 0.27。