题目
一手机生产厂家在其宣传广告中声称他们生产的某种品牌的手机的待机时间的平均值至少为71.5小时,一质检部门检查了该厂生产的这种品牌的手机6部,测得待机时间的平均值overline (z)=70, ^2=10,假设手机的待机时间overline (z)=70, ^2=10未知,问当显著性水平为0.05时,由这些数据能否说明该广告有欺骗消费者之嫌疑? overline (z)=70, ^2=10
一手机生产厂家在其宣传广告中声称他们生产的某种品牌的手机的待机时间的平均值至少为71.5小时,一质检部门检查了该厂生产的这种品牌的手机6部,测得待机时间的平均值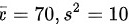 ,假设手机的待机时间
,假设手机的待机时间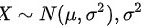 未知,问当显著性水平为0.05时,由这些数据能否说明该广告有欺骗消费者之嫌疑?
未知,问当显著性水平为0.05时,由这些数据能否说明该广告有欺骗消费者之嫌疑? 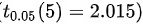
题目解答
答案
这是一个单样本t检验的问题,我们需要检验的假设是:
- 原假设(H0):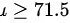 ,即手机的平均待机时间至少为71.5小时。
,即手机的平均待机时间至少为71.5小时。
- 备择假设(H1):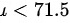 ,即手机的平均待机时间小于71.5小时。
,即手机的平均待机时间小于71.5小时。
我们的目标是检验原假设是否成立。如果原假设被拒绝,那么就说明广告有欺骗消费者之嫌疑。
首先,我们需要计算t统计量的值。t统计量的计算公式为:
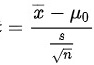
其中,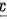 是样本平均值,
是样本平均值,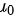 是原假设中的参数值,s是样本标准差,n是样本大小。将题目中的数据代入,我们得到:
是原假设中的参数值,s是样本标准差,n是样本大小。将题目中的数据代入,我们得到:
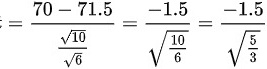
然后,我们需要查表得到t分布在显著性水平0.05下的临界值。题目已经给出了这个值,即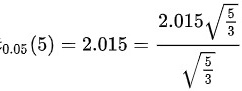 。
。
最后,我们需要比较t统计量的值和临界值。如果t统计量的值小于临界值,那么我们就拒绝原假设,否则我们就不能拒绝原假设。
在这个问题中,我们的备择假设是,所以我们关心的是t统计量的值是否小于临界值的负值,即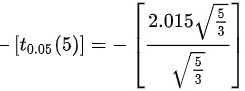 。因为
。因为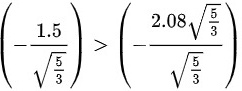 \left(-\frac{2.08\sqrt{\frac{5}{3}}}{\sqrt{\frac{5}{3}}}\right)" data-width="247" data-height="91" data-size="7671" data-format="png" style="max-width:100%">,所以我们不能拒绝原假设。这意味着,根据这些数据,我们不能说明该广告有欺骗消费者之嫌疑。
\left(-\frac{2.08\sqrt{\frac{5}{3}}}{\sqrt{\frac{5}{3}}}\right)" data-width="247" data-height="91" data-size="7671" data-format="png" style="max-width:100%">,所以我们不能拒绝原假设。这意味着,根据这些数据,我们不能说明该广告有欺骗消费者之嫌疑。
解析
步骤 1:确定假设
- 原假设(H0):$\mu \geq 71.5$,即手机的平均待机时间至少为71.5小时。
- 备择假设(H1):$\mu < 71.5$,即手机的平均待机时间小于71.5小时。
步骤 2:计算t统计量
- 样本平均值 $\overline{x} = 70$,样本标准差 $s = \sqrt{10}$,样本大小 $n = 6$。
- t统计量的计算公式为:$t = \frac{\overline{x} - \mu_0}{s / \sqrt{n}}$。
- 将题目中的数据代入,我们得到:$t = \frac{70 - 71.5}{\sqrt{10} / \sqrt{6}} = \frac{-1.5}{\sqrt{10/6}} = \frac{-1.5}{\sqrt{5/3}}$。
步骤 3:确定临界值
- 题目已经给出了显著性水平0.05下的临界值,即$t_{0.05}(5) = 2.015$。
- 因为是单尾检验,我们关心的是t统计量的值是否小于临界值的负值,即$-t_{0.05}(5) = -2.015$。
步骤 4:比较t统计量和临界值
- 比较计算得到的t统计量值和临界值:$t = \frac{-1.5}{\sqrt{5/3}}$。
- 计算t统计量的值:$t = \frac{-1.5}{\sqrt{5/3}} = \frac{-1.5}{\sqrt{1.6667}} = \frac{-1.5}{1.29099} = -1.162$。
- 比较:$-1.162 > -2.015$。
步骤 5:做出决策
- 因为t统计量的值大于临界值的负值,所以我们不能拒绝原假设。
- 这意味着,根据这些数据,我们不能说明该广告有欺骗消费者之嫌疑。
- 原假设(H0):$\mu \geq 71.5$,即手机的平均待机时间至少为71.5小时。
- 备择假设(H1):$\mu < 71.5$,即手机的平均待机时间小于71.5小时。
步骤 2:计算t统计量
- 样本平均值 $\overline{x} = 70$,样本标准差 $s = \sqrt{10}$,样本大小 $n = 6$。
- t统计量的计算公式为:$t = \frac{\overline{x} - \mu_0}{s / \sqrt{n}}$。
- 将题目中的数据代入,我们得到:$t = \frac{70 - 71.5}{\sqrt{10} / \sqrt{6}} = \frac{-1.5}{\sqrt{10/6}} = \frac{-1.5}{\sqrt{5/3}}$。
步骤 3:确定临界值
- 题目已经给出了显著性水平0.05下的临界值,即$t_{0.05}(5) = 2.015$。
- 因为是单尾检验,我们关心的是t统计量的值是否小于临界值的负值,即$-t_{0.05}(5) = -2.015$。
步骤 4:比较t统计量和临界值
- 比较计算得到的t统计量值和临界值:$t = \frac{-1.5}{\sqrt{5/3}}$。
- 计算t统计量的值:$t = \frac{-1.5}{\sqrt{5/3}} = \frac{-1.5}{\sqrt{1.6667}} = \frac{-1.5}{1.29099} = -1.162$。
- 比较:$-1.162 > -2.015$。
步骤 5:做出决策
- 因为t统计量的值大于临界值的负值,所以我们不能拒绝原假设。
- 这意味着,根据这些数据,我们不能说明该广告有欺骗消费者之嫌疑。