题目
Logistic回归分,下列哪项不对?______多选21.变异系数比较变异程度适宜:________________________________6.简述直线相关与回归的区别与应用答:区别:(1)资料要求不同,相关要求两个变量是双变量正态分布;回归要求应变量Y服从正态分布,而自变量X是能精确测量和严格控制的变量。(2)统计意义不同,相关反映两变量间的伴随关系这种关系是相互的,对等的;不一定有因果关系;回归则反映两变量间的依存关系,有自变量与应变量之分,一般 将“因”或较易测定、变异较小者定为自变量。这种依存关系可能是因果关系或从属关系。(3 )分目的不同,相关分的目的是把两变量间直线关系的密切程度及方向用一统计指标表示出来;回归分的目的 则是把自变量与应变量间的关系用函数公式定量表达岀来。总平方和减少的部分。-|||-(4)对于Ⅱ型回归,r与b值可相互换算,联系:(1)变量间关系的方向一致,对同一资料,其r与b的正负号一致。(2)假设检验等价,对同一样 本,tr=tb,由于tb计算较复杂,实际中常以r的假设检验代替对b的检验。(3)相关和回归可以相互释, 相关系数的平方r2(又称决定系数)是回归平方和与总的离均差平方和之比, 故回归平方和是引入相关变量后7.举例说明Poisson distribution的特征与应用答:特征1.总体均数与总体方差b2相等2.当n很大n很小,且nn=入为常数时,二项分布近似poisson分 布3.当入增大时poosson分布渐进正态分布,入》0时,可作正态处理4.poisson分布具备可加性.应用:1 总体均数卩区间估计2.样本均数与总体均数卩比较3.两样本均数的比较.8.用你所熟悉的专业举例说明方差分的基本思想与工作步骤07问答1.假设检验中如何确定p值大小?简述P值的含义/P值的计算: 一般地,用X表示检验的统计量,当H0为真时,可由样本数据计算岀该统计量的值C,根据检验统计量X的具体分布,可求出P值。具体地说:左侧检验的P值为检验统计量 X小于样本统计 值C的概率,即:P=P(X C)双侧检验的P值为检验统计量 X落在样本统计值C为端点的尾部区域内的概率的2倍:P=2P(X >C)(当C位于分布曲线的右端时)或P=2P( X< C)(当C位于分布曲线的左端时)。若X服从正态分布和t分布,其分布曲线是关于纵轴对称的,故其P值可表示为P=P(| X|>C)。计算出P值后,将给定的显著性水平a与P值比较,就可作出检验的结论:如果a>P值,则在显著性水平a下拒绝原假设。如果a为慎重起见,可增加样本容量,重新进行抽样检验。P值是:P值即概率,反映某一事件发生的可能性大小。统计学根据显著性检验方法所得到的P值,一般以P<0.05为显著,P <0.01为非常显著,其含义是样本间的差异由抽样误差所致的概率小于0.05或0.01。实际上,P值不能赋予数据任何重要性,只能说明某事件发生的机率。2.简述编制频数表的方法步骤及意义3.简述二项分布和poisson分布的联系与区别二项分布:对只具有两种互斥结果的离散型随机事件的规律性进行描述的一种概率分布。Poisson分布是在n很小,样本含量n趋于无穷大时,二项分布的极限形式。当v=8时,t分布即为u分布,趋向正态分布。4.简述非参数检验的优缺点,临床工作中如何选择?优点:(1)适用范围广,对变量的类型和分布无特殊要求,不受总体分布的限制;(2)对数据的要求不严,对某些指标不便准确测定的资料也可应用;(3)方法简便,易于理和掌握。缺点是如果对符合参数检验的资料用了非参数检验,因不能充分利用资料提供的信息,会使检验效能低于非参数检验;若要使检验效 能相同,往往需要更大的样本含量。09计算分1.用甲、乙两种方法分别测定一批空气样本CS2的含量(mg/m3)如下,已知本资料不满足参数检验的条件,试比较两种方法测定结果的差别有无统计学意义?(写岀完整步骤总平方和减少的部分。-|||-(4)对于Ⅱ型回归,r与b值可相互换算,总平方和减少的部分。-|||-(4)对于Ⅱ型回归,r与b值可相互换算,总平方和减少的部分。-|||-(4)对于Ⅱ型回归,r与b值可相互换算,SS总='■Xij2—C V总=N—1再算出SS组间V组间=g— 1SS组内=SS总—SS组间MS组间=SS组间/V组间MS组内=SS组内/V组内F=MS组间/MS组间,算出F值按V1=V组间V2=V组内,查F界值表,得F°.01(v1V2)比较,若大则P< 0.01拒绝% 认为有差别 若小则P大于0.01,不拒绝H006计算分1.有260人份血清样品,每份样品一分为二,用两种不同的免疫学检测方法检验类风湿因子,结果如下:甲,乙方法均阳性172人份,甲方法阴性为80人份;乙方法阴性76人份;还有部分是两种方法均为阴性,试根 据上述资料列岀合适的计算表,分这两种免疫学检验的结果之间有无联系和差别总平方和减少的部分。-|||-(4)对于Ⅱ型回归,r与b值可相互换算,2结果之间的联系应该用率的区间估计甲的阳性率P仁180/260乙的阳性率P2=184/260根据公式区间为p±ua/2 *Sp Sp= .p(1- p)/n算出两者区间进行比较,重复多则有联系2.有人为研究饮酒与高血压的关系,普查了某地区得到如下资料(1)请指出该资料中一个错误使用的概念,正确名称应该是神马?答:不应该用发病率,应该用患病率(2)能否据此认为”不饮酒”相对于”饮酒”来说更易于导致高血压,why?应该怎样做,最后的结论是神马?不能认为不饮酒更易于导致高血压,因为其内部构成不同饮酒组男性较多,不饮酒女性较多,应该进行率的标 准化.1本例已知饮酒和不饮酒组各自的内部构成及患病率,采用直接法2.选两种调查人数之和作标准3.求预期患病人数,将各组标准调查人数分别乘以两种原始患病率,即得不同构成两组预期值卩患病人数 4.计算两组调查卩标准化患病率 饮酒组患病率p'=106/2951=〜〜〜非饮酒组患病率p'=86/2952=〜〜经标准化,3,饮酒组患病率高于不饮酒组,与分组比较的患病率一致,校正了标准化前非饮酒组患病率高于 饮酒组患病率的不妥结论.05j计算1.在研究地方性克山病的病因时,科学工作者到病区的粮食可能是发病原因之一.今用病区的粮食作为处理因素,将大鼠随机分为两组,分别用甲,乙两种饲料配方饲养动物,观察大鼠的心肌坏死的面积(单位:格子数)如下,若问不同饲料之间对实验效应有无影响,其计算步骤是神马?此资料要用两种方法进行统计推断,并比较神马方法好,为神马?(不需要计算数据)甲组(n=29):0(10)0.20.30.4(2)0.61.01.62.22.63.3 4.35.15.45.5 6.16.29.713.836.0乙组(n=29)0(14)0.2(4)0.30.4(2)0.9(2)1.3(2)1.72.87.413.0答:此题用两种检验方法1.是两样本t检验2是秩和检验当用t检验时,假设两样本均为正态分布,两总体方差相同,(1).建立检验假设,确定检验水准H0:u仁u2,即不同饲料之间对实验无影响H1: u1工u2即〜〜有影响a=0.05(2).计算检验统计量(3)确定p值做出推断结论 查表t界值若t大则p<0.05拒绝H0及H1有统计学意义,即有影响 若t小p>0.05不拒绝H0不能认为有影响2.当秩和检验时,因相同秩太多,用两个独立样本比较的秩和检验(校正公式)H0:甲乙两种饲料对实验效应的 总体分布位置相同H1:不相同a=0.5统一偏秩,分组求秩和,以较小样本秩和作为T N=n什n2u=|T-n1(n+1)/2|-0.5/. n1n2(n+1)/nUc=U/-c算出Uc检u界值表比较 若u大则p<0.05拒绝H°,有影响,u小p>0.05不拒绝H0,不能认为有影响由上两种方法看出非参考检验方法较好,对于分布已知是否是正态小样本资料,或一端或两端是不确定值的资料,宜选用非参检验,此资料非正态分布,故选非参检验好2•今有42例可疑肺结核患者的谈液样本,每份标本都用甲乙两法进行培养,结果:甲乙两法均为阳性8例;甲法培养阳性26例;乙法培养阳性11例;试问甲乙两法培养结果有无差别?答:甲乙两种结果此资料为配对的四格表资料,故用配对四格表资料的 X2检验Ho:b=C,即两种方法检测结果相同Hi: B工C,即不同a=0.05因为b+c=18+13=31< 40故用校正公式Xc2=(|b-c|-1)2/b+c,v=1带入公式算出Xc2查X2界值表 若Xc2大则p小,p< 0.05拒绝H0有差别 若Xc2小,p大,p> 0.05不拒绝H0,不能认有差别3.下表为一抽样研究资料,试填补空白数据;根据(5)(6)(7)三栏结果作简要分;试估计0~岁年龄组恶性肿瘤死亡率和年龄别死亡率的可信区间;试比较20~与40~岁组恶性肿瘤死亡率有无差别答:1.0~岁年龄组恶性肿瘤死亡率的可信区间为:按95%算p±U*a/2*Sp,Sp= ...p(1-p)/n,95%的可信区间U*a/2=1.96带入公式得0~岁年龄组恶性肿瘤死亡率可信区间和年龄死亡率的可信区间2.比较20~与40~岁组恶性肿瘤死亡率有无差别用两样本率的u检验H°:n1=n2即~无差别H1:n仟n2即~有差别a=0.05 u=(p1-p2)/(Sp1-p2)算出u值,查u界值表,若u大则p<0.05拒绝H0,有差别 若u小则p>0.05不拒绝H0,尚不能认为有差别.
Logistic回归分,下列哪项不对?______多选21.变异系数比较变异程度适宜:________________________________
6.简述直线相关与回归的区别与应用
答:区别:(1)资料要求不同,相关要求两个变量是双变量正态分布;回归要求应变量Y服从正态分布,
而自变量X是能精确测量和严格控制的变量。(2)统计意义不同,相关反映两变量间的伴随关系这种关系
是相互的,对等的;不一定有因果关系;回归则反映两变量间的依存关系,有自变量与应变量之分,一般 将“因”或较易测定、变异较小者定为自变量。这种依存关系可能是因果关系或从属关系。(3 )分目的
不同,相关分的目的是把两变量间直线关系的密切程度及方向用一统计指标表示出来;回归分的目的 则是把自变量与应变量间的关系用函数公式定量表达岀来。
 联系:(1)变量间关系的方向一致,对同一资料,其r与b的正负号一致。(2)假设检验等价,对同一样 本,tr=tb,由于tb计算较复杂,实际中常以r的假设检验代替对b的检验。(3)相关和回归可以相互释, 相关系数的平方r2(又称决定系数)是回归平方和与总的离均差平方和之比, 故回归平方和是引入相关变量后
联系:(1)变量间关系的方向一致,对同一资料,其r与b的正负号一致。(2)假设检验等价,对同一样 本,tr=tb,由于tb计算较复杂,实际中常以r的假设检验代替对b的检验。(3)相关和回归可以相互释, 相关系数的平方r2(又称决定系数)是回归平方和与总的离均差平方和之比, 故回归平方和是引入相关变量后7.举例说明Poisson distribution的特征与应用
答:特征1.总体均数与总体方差b2相等2.当n很大n很小,且nn=入为常数时,二项分布近似poisson分 布3.当入增大时poosson分布渐进正态分布,入》0时,可作正态处理4.poisson分布具备可加性.应用:1 总体均数卩区间估计2.样本均数与总体均数卩比较3.两样本均数的比较.
8.用你所熟悉的专业举例说明方差分的基本思想与工作步骤
07问答
1.假设检验中如何确定p值大小?简述P值的含义/
P值的计算: 一般地,用X表示检验的统计量,当H0为真时,可由样本数据计算岀该统计量的值C,
根据检验统计量X的具体分布,可求出P值。具体地说:左侧检验的P值为检验统计量 X小于样本统计 值C的概率,即:P=P{X C}双侧检验的P值为检验统计量 X落在样本统计值C为端点的尾部区域内的概率的2倍:P=2P{X >C}
(当C位于分布曲线的右端时)或P=2P{ X< C}(当C位于分布曲线的左端时)。若X服从正态分布和t分布,其分布曲线是关于纵轴对称的,故其P值可表示为P=P{| X|>C}。计算出P值后,将给定的显
著性水平a与P值比较,就可作出检验的结论:如果a>P值,则在显著性水平a下拒绝原假设。如果a
为慎重起见,可增加样本容量,重新进行抽样检验。P值是:P值即概率,反映某一事件发生的可能性大
小。统计学根据显著性检验方法所得到的P值,一般以P<0.05为显著,P <0.01为非常显著,其含义是
样本间的差异由抽样误差所致的概率小于0.05或0.01。实际上,P值不能赋予数据任何重要性,只能说明
某事件发生的机率。
2.简述编制频数表的方法步骤及意义
3.简述二项分布和poisson分布的联系与区别
二项分布:对只具有两种互斥结果的离散型随机事件的规律性进行描述的一种概率分布。Poisson分布是在
n很小,样本含量n趋于无穷大时,二项分布的极限形式。当v=8时,t分布即为u分布,趋向正态分布。
4.简述非参数检验的优缺点,临床工作中如何选择?
优点:(1)适用范围广,对变量的类型和分布无特殊要求,不受总体分布的限制;(2)对数据的要求不严,
对某些指标不便准确测定的资料也可应用;(3)方法简便,易于理和掌握。缺点是如果对符合参数检验
的资料用了非参数检验,因不能充分利用资料提供的信息,会使检验效能低于非参数检验;若要使检验效 能相同,往往需要更大的样本含量。
09计算分
1.用甲、乙两种方法分别测定一批空气样本CS2的含量(mg/m3)如下,已知本资
料不满足参数检验的条件,试比较两种方法测定结果的差别有无统计学意义?(写岀完整步骤
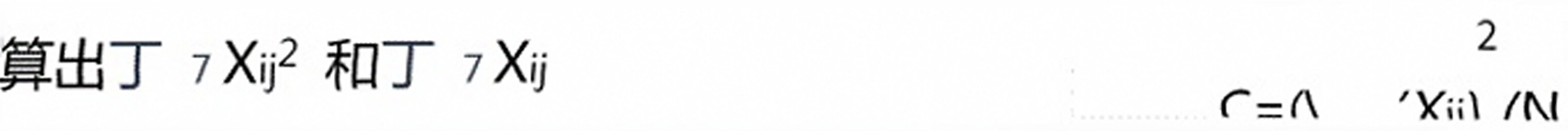

SS总='■Xij2—C V总=N—1再算出SS组间V组间=g— 1
SS组内=SS总—SS组间MS组间=SS组间/V组间MS组内=SS组内/V组内
F=MS组间/MS组间,算出F值按V1=V组间V2=V组内,查F界值表,得F°.01(v1V2)比较,若大则P< 0.01拒绝% 认为有差别 若小则P大于0.01,不拒绝H0
06计算分
1.有260人份血清样品,每份样品一分为二,用两种不同的免疫学检测方法检验类风湿因子,结果如下:甲,
乙方法均阳性172人份,甲方法阴性为80人份;乙方法阴性76人份;还有部分是两种方法均为阴性,试根 据上述资料列岀合适的计算表,分这两种免疫学检验的结果之间有无联系和差别

2结果之间的联系应该用率的区间估计甲的阳性率P仁180/260乙的阳性率P2=184/260
根据公式区间为p±ua/2 *Sp Sp= .p(1- p)/n算出两者区间进行比较,重复多则有联系
2.有人为研究饮酒与高血压的关系,普查了某地区得到如下资料
(1)请指出该资料中一个错误使用的概念,正确名称应该是神马?
答:不应该用发病率,应该用患病率
(2)能否据此认为”不饮酒”相对于”饮酒”来说更易于导致高血压,why?应该怎样做,最后的结论是神马?
不能认为不饮酒更易于导致高血压,因为其内部构成不同饮酒组男性较多,不饮酒女性较多,应该进行率的标 准化.1本例已知饮酒和不饮酒组各自的内部构成及患病率,采用直接法2.选两种调查人数之和作标准3.求
预期患病人数,将各组标准调查人数分别乘以两种原始患病率,即得不同构成两组预期值卩患病人数 4.计
算两组调查卩标准化患病率 饮酒组患病率p'=106/2951=〜〜〜非饮酒组患病率p'=86/2952=〜〜
经标准化,3,饮酒组患病率高于不饮酒组,与分组比较的患病率一致,校正了标准化前非饮酒组患病率高于 饮酒组患病率的不妥结论.
05j计算
1.在研究地方性克山病的病因时,科学工作者到病区的粮食可能是发病原因之一.今用病区的粮食作为处
理因素,将大鼠随机分为两组,分别用甲,乙两种饲料配方饲养动物,观察大鼠的心肌坏死的面积(单位:格
子数)如下,若问不同饲料之间对实验效应有无影响,其计算步骤是神马?此资料要用两种方法进行统计
推断,并比较神马方法好,为神马?(不需要计算数据)
甲组(n=29):0(10)0.20.30.4(2)0.61.01.62.22.63.3 4.35.15.45.5 6.16.29.7
13.836.0
乙组(n=29)0(14)0.2(4)0.30.4(2)0.9(2)1.3(2)1.72.87.413.0
答:此题用两种检验方法1.是两样本t检验2是秩和检验当用t检验时,假设两样本均为正态分布,两总体方
差相同,(1).建立检验假设,确定检验水准H0:u仁u2,即不同饲料之间对实验无影响H1: u1工u2即〜〜
有影响a=0.05(2).计算检验统计量(3)确定p值做出推断结论 查表t界值若t大则p<0.05拒绝H0
及H1有统计学意义,即有影响 若t小p>0.05不拒绝H0不能认为有影响
2.当秩和检验时,因相同秩太多,用两个独立样本比较的秩和检验(校正公式)H0:甲乙两种饲料对实验效应的 总体分布位置相同H1:不相同a=0.5统一偏秩,分组求秩和,以较小样本秩和作为T N=n什n2
u=|T-n1(n+1)/2|-0.5/. n1n2(n+1)/nUc=U/-c算出Uc检u界值表比较 若u大则p<0.05拒绝H°,有
影响,u小p>0.05不拒绝H0,不能认为有影响
由上两种方法看出非参考检验方法较好,对于分布已知是否是正态小样本资料,或一端或两端是不确定值的
资料,宜选用非参检验,此资料非正态分布,故选非参检验好
2•今有42例可疑肺结核患者的谈液样本,每份标本都用甲乙两法进行培养,结果:甲乙两法均为阳性8例;
甲法培养阳性26例;乙法培养阳性11例;试问甲乙两法培养结果有无差别?
答:甲乙两种结果
此资料为配对的四格表资料,故用配对四格表资料的 X2检验Ho:b=C,即两种方法检测结果相同Hi: B工C,即不同a=0.05因为b+c=18+13=31< 40故用校正公式Xc2=(|b-c|-1)2/b+c,v=1带入公式算出Xc2
查X2界值表 若Xc2大则p小,p< 0.05拒绝H0有差别 若Xc2小,p大,p> 0.05不拒绝H0,不能认有差别
3.下表为一抽样研究资料,试填补空白数据;根据(5)(6)(7)三栏结果作简要分;试估计0~岁年龄组恶性肿
瘤死亡率和年龄别死亡率的可信区间;试比较20~与40~岁组恶性肿瘤死亡率有无差别
答:1.0~岁年龄组恶性肿瘤死亡率的可信区间为:按95%算p±U*a/2*Sp,
Sp= ...p(1-p)/n,95%的可信区间U*a/2=1.96带入公式得0~岁年龄组恶性肿瘤死亡率可信区
间和年龄死亡率的可信区间
2.比较20~与40~岁组恶性肿瘤死亡率有无差别用两样本率的u检验H°:n1=n2即~无差别
H1:n仟n2即~有差别a=0.05 u=(p1-p2)/(Sp1-p2)算出u值,查u界值表,若u大则p<0.05拒绝H0,有差别 若u小则p>0.05不拒绝H0,尚不能认为有差别.
题目解答
答案
D.应变量可以是分类变量,也可以是数值变量 C.同类指标,均数相差较大E.不同指标,均数相差较大