题目
设总体X的密度函数为f(x)= θcθx?(θ+1) x>c 0 x≤c .其中c>0是已知常数,而θ>1是未知参数.(X1,X2,…,Xn)是从该总体中抽取的一个样本,试求参数θ的最大似然估计量.
设总体X的密度函数为f(x)=
.其中c>0是已知常数,而θ>1是未知参数.(X1,X2,…,Xn)是从该总体中抽取的一个样本,试求参数θ的最大似然估计量.
|
|
|
题目解答
答案
∵似然函数为L(θ)=
f(xi)=
θ cθ
=θn cnθ(x1x2…xn)?(θ+1)
∴lnL(θ)=nlnθ+nθln c?(θ+1)
lnxi.
∴
lnL(θ)=
+nln c?
lnxi
令
lnL(θ)=0,即
+nln c?
lnxi=0
得到似然函数的唯一驻点θ=
.
所以参数θ的最大似然估计量为
=
.
| n |
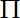 |
| i=1 |
| n |
|
| i=1 |
| x |
?(θ+1)
i
|
∴lnL(θ)=nlnθ+nθln c?(θ+1)
| n |
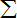 |
| i=1 |
∴
| d |
| dθ |
| n |
| θ |
| n |
|
| i=1 |
令
| d |
| dθ |
| n |
| θ |
| n |
|
| i=1 |
得到似然函数的唯一驻点θ=
| n | |||
|
所以参数θ的最大似然估计量为
| ? |
| θ |
| n | |||
|
解析
考查要点:本题主要考查最大似然估计的应用,需要根据给定的密度函数构造似然函数,并通过求导找到参数θ的最大似然估计量。
解题核心思路:
- 构造似然函数:将样本中每个观测值的概率密度相乘,得到关于θ的函数。
- 取对数简化计算:对似然函数取自然对数,转化为求和形式,便于求导。
- 求导并解方程:对θ求导,令导数为零,解方程得到θ的估计值。
- 验证唯一驻点:确认解为极大值点(本题中通过函数性质可直接确定)。
破题关键点:
- 正确写出似然函数,注意密度函数的分段形式。
- 对数似然函数的展开与求导,特别注意指数项的处理。
- 代数运算的准确性,避免符号错误。
构造似然函数
样本$(X_1, X_2, \dots, X_n)$中每个观测值均大于$c$,因此似然函数为:
$L(\theta) = \prod_{i=1}^n f(X_i) = \prod_{i=1}^n \left[ \theta c^\theta X_i^{-(\theta+1)} \right]$
展开后整理得:
$L(\theta) = \theta^n c^{\theta n} \left( \prod_{i=1}^n X_i \right)^{-(\theta+1)}$
取对数并简化
对数似然函数为:
$\ln L(\theta) = n \ln \theta + n \theta \ln c - (\theta + 1) \sum_{i=1}^n \ln X_i$
求导并解方程
对$\theta$求导:
$\frac{d}{d\theta} \ln L(\theta) = \frac{n}{\theta} + n \ln c - \sum_{i=1}^n \ln X_i$
令导数为零,解得:
$\frac{n}{\theta} + n \ln c - \sum_{i=1}^n \ln X_i = 0 \quad \Rightarrow \quad \hat{\theta} = \frac{n}{\sum_{i=1}^n \ln X_i - n \ln c}$
验证极大值
二阶导数为负,说明该驻点为极大值点,故$\hat{\theta}$即为最大似然估计量。