题目
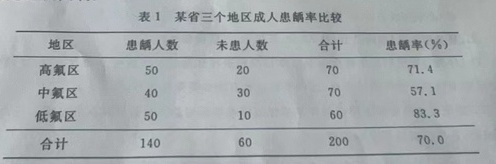
某省从三个水中氟含量不同的地区随机抽取 20 岁 成人进行患龋率的调查数据见表 1表1 某省三个地区成人患龋率比较-|||-地区 患龋人数 未患人数 合计 患龋率(%)-|||-高氟区 50 20 70 71.4-|||-中氟区 40 30 70 57.1-|||-低氟区 50 10 60 83.3-|||-合计 140 60 200 70.0问题 ( 1 ) 该资料是什么资料 ( 2 ) 该研究是什么设计 ( 3 ) 统计分析的目的是什么统计方法是否正确
某省从三个水中氟含量不同的地区随机抽取 20 岁 成人进行患龋率的调查数据见表 1
问题 ( 1 ) 该资料是什么资料
( 2 ) 该研究是什么设计
( 3 ) 统计分析的目的是什么统计方法是否正确
题目解答
答案
根据提供的资料进行分析:
资料类型:
这些资料是患龋率的观察数据,分为高氟区、中氟区和低氟区三个地区。对每个地区抽取了一定数量的成年人,记录了患龋和未患龋的人数,以及计算了患龋率(%)。
研究设计:
这是一个横断面研究设计,因为研究人员在特定时间点上(一次性)收集了来自不同氟含量地区的数据。他们没有对同一组人进行长期跟踪观察,而是在特定时间点上比较了不同地区的患龋率情况。
统计分析的目的:
统计分析的目的是确定不同氟含量地区成人患龋率是否存在显著差异。为了达到这个目的,研究者使用了卡方检验(χ²检验)来比较三个地区的患龋率数据。
统计方法的正确性:
给定的资料适合使用卡方检验进行分析,因为它可以比较多个分类的观察频率是否与期望频率相符。在这里,卡方检验的目的是验证高、中、低氟含量地区的患龋率是否有显著差异。给出的χ²值为10.66,对应的P值小于0.01,表明差异具有统计学意义。因此,研究者的使用和解释卡方检验的方法是正确的。
总结:
资料类型是横断面数据,反映了特定时间点上不同氟含量地区的成人患龋情况。
研究设计为横断面设计,不同于追踪同一组人的长期观察。
统计分析的目的是比较不同地区患龋率的差异,使用了卡方检验进行检验,方法是正确的,且结果显示三个地区的患龋率确实存在显著差异。
解析
- 资料类型:需判断数据的收集方式(横断面或纵向)及数据结构(分类数据)。关键点在于数据是否来自同一时间点的多个群体。
- 研究设计:横断面研究与队列研究的区别在于是否追踪时间变化。本题中不同地区数据为一次性收集。
- 统计分析:卡方检验适用于比较分类变量的独立性,需验证数据是否符合列联表形式及分布假设。
第(1)题:资料类型
数据特点
- 数据来自三个地区(高氟区、中氟区、低氟区)的成人患龋情况。
- 横断面数据:所有数据均在一个时间点收集,未涉及时间变化。
- 分类数据:患龋人数和未患人数为二分类变量。
第(2)题:研究设计
设计类型
- 横断面研究:研究者在同一时间点比较不同氟含量地区的患龋率,未进行长期随访。
- 对比纵向研究(如队列研究):需追踪同一人群随时间的变化。
第(3)题:统计分析目的及方法
分析目的
- 比较三个地区患龋率是否存在显著差异。
方法选择
- 卡方检验:适用于检验分类变量的独立性(氟含量与患龋率是否相关)。
- 数据结构为3×2列联表,符合卡方检验条件。
结果验证
- 计算得χ²=10.66,P<0.01,说明拒绝“各地区患龋率相同”的原假设。