题目
某企业某种商品的销售资料如下:年份第一季度第二季度第三季度第四季度合计2002——1318312003581418452004610162254200581219256420061517——32试用同期平均法测定该商品的季节变动情况。解:同期平均法季节指数计算表年份第一季度第二季度第三季度第四季度合计2002——1318312003581418452004610162254200581219256420061517——32同季平均8.50011.75015.50020.75014.125季节指数%60.1769983.18584109.7345146.9027400数据审核时,主要从及时性、准确性和完整性方面进行审核的数据是( )A. 一手数据 B. 二手数据 C. 时间序列数据 D. ) E. 0=f(x-x) F. 0=f(x-x) G. 0=f(x-x) ) 各组数据在组内是均匀分布的 各组次数相等 各组数据之间没有差异 ) 总体单位数多少的影响 平均数大小和计量单位的影响 离散程度的影响 ) 两个总体的标准差应该相等 两个总体的平均数应该相等 两个总体的离差平方和应该相等 ) 事先对总体进行初步分析 按随机原则抽取样本 保证调查数据的准确性、及时性 P值中拒绝原假设理由最充分的是( A ) 2% 10% C.25% ) 0=f(x-x) 0=f(x-x) 0=f(x-x) P应选( A ) 85% 87% 90% ) 函数关系 B.相关关系 C.对应关系 ) 函数关系 B.相关关系 C.对应关系 ) 单相关 复相关 偏相关 ) 线性相关关系 B.曲线相关关系 C.任何相关关系 ) 0=f(x-x) 0=f(x-x) 0=f(x-x) ) 0=f(x-x) B.0=f(x-x) C.0=f(x-x) )A.0=f(x-x) B.0=f(x-x) 0=f(x-x) ) 曲线关系 线性关系 因果关系 ) 总离差平方和 回归平方和 残差平方和 ) 平均数时间数列 相对数时间数列 时期数列 ) 年末人口总数数列 B.年出生人数数列 C.单位播种面积的粮食产量数列 ) 逐期增减量之差等于累计增减量 逐期增减量之和等于累计增减量 逐期增减量之商等于累计增减量 ) 发展速度-1=增长速度 发展速度+1=增长速度 增长速度-1=发展速度 Sj的取值范围为 ( A ) 0≤Sj≤4 B.0≤Sj≤1 C.0≤Sj≤12 ) 15项 16项 17项 判断题 统计学是一门收集、整理和分析统计数据的实质性科学。(×) 分类数据是指只能归入某一类别的非数值型数据。 ( √ ) 分类数据和顺序数据相似之处在于两者都是非数字型数据。 ( √ ) 时间序列数据是指对不同单位在同一个时间点上收集的数据。(×) 从统计方法的构成看,统计学可以分为描述统计学和推断统计学。( √ ) 总体的数量特征都是从每个总体单位的特征加以逐级汇总而体现出来的。( √ ) 若总体中所包含的统计指标数是有限的,则称为有限总体。(×) 变量按其所受影响因素不同,可分为离散型变量和连续型变量。(×) 甲企业职工人数1248人,这是一个连续变量。 (×) 某地区2009年人均国内生产总值为13600元,这是一个离散变量。(×) 复合分组是对被研究现象总体只按一个变量进行分组。(×) 简单分组是对原始数据按两个或两个以上变量进行层叠式分组。(×) 算术平均数既适用于数值型数据,也适用于分类数据和顺序数据。( ×) 根据分组数据计算的平均数只是实际平均数的近似值。 ( √ ) 众数可直观地说明分布的离散趋势,可用它反映变量值一般水平的代表值。( ×) 四分位数是将按大小顺序排列的一组数据划分为三等分的四个变量值。(×) 数据的离散程度越大,集中趋势的测度值对该组数据的代表性就越差。( √ ) 偏态和峰态是对分布集中程度的测度。 ( ×) H,不一定H是正确的。 ( √ ) Z检验。 (×) SST是描述所有数值集中程度的数量指标。 ( √ ) 方差分析采用t检验。 (×) 方差分析就是解决随机因素是否是造成数据差异的主要原因的问题。(×) 方差分析假定各水平观察值为来自正态总体的随机样本。 ( √ ) 多重比较法是通过对总体均值之间的配对比较来检验是哪些均值之间存在差异的方法。 ( √ ) 检验不显著,也可以对均值作多重比较。(×) 按变量之间相关关系的变化方向不同,可分为完全相关、不完全相关和不相关。(×) 当相关系数0=f(x-x)时,说明两个变量之间不存在任何相关关系。(×) 当变量x与y之间存在线性相关关系时,有0=f(x-x)。 ( √ ) 回归分析中,通常假定随机误差项0=f(x-x)遵从正态分布,即0=f(x-x)。( √ ) 最小二乘法就是寻找参数0=f(x-x)的估计值0=f(x-x),使残差绝对值之和达到最小。(×) 检验主要用于检验回归系数的显著性。 (×) 样本决定系数等于残差平方和与总离差平方和之比,记为0=f(x-x)。(×) 因变量单个值的预测区间大于因变量均值的预测区间。 ( √ ) 在线性相关条件下,研究两个和两个以上自变量对两个以上因变量的数量变化关系,称为多元线性回归分析。 (×) 多元线性回归模型中回归系数的最小二乘估计量是确定性变量。(×) 检验所得结论是一致的。( √ ) 因为时点观察值没有长度,所以时点数列的每一观察值的大小不直接受时期长短的影响。( √ ) 用趋势剔除法测定季节变动的目的是计算没有长期趋势影响的季节指数。 ( √ ) 若趋势方程为0=f(x-x),则该现象呈下降趋势。 ( √ ) 若时间数列各期的环比发展速度相等,则各期逐期增长量一定相等。(×) 平均发展水平是一种序时平均数,平均发展速度也是一种序时平均数。( √ ) 用移动平均法对平稳时间数列进行预测时,若选用偶数项进行移动平均,则需要平均两次才能计算出预测值。 (×) 如果现象的发展在季度上有明显的季节变动,则其季节指数一般会大于或小于100%。( √ ) 一般来说,当季节指数<400%时,表明现象此时处于淡季。(×) 预测误差是现象的观察值与预测值之差。一般来说,预测误差越小模型拟合效果越好。 ( √ ) 计算题
某企业某种商品的销售资料如下:
年份
第一季度
第二季度
第三季度
第四季度
合计
2002
—
—
13
18
31
2003
5
8
14
18
45
2004
6
10
16
22
54
2005
8
12
19
25
64
2006
15
17
—
—
32
试用同期平均法测定该商品的季节变动情况。
解:同期平均法季节指数计算表
年份
第一季度
第二季度
第三季度
第四季度
合计
2002
—
—
13
18
31
2003
5
8
14
18
45
2004
6
10
16
22
54
2005
8
12
19
25
64
2006
15
17
—
—
32
同季平均
8.500
11.750
15.500
20.750
14.125
季节指数%
60.17699
83.18584
109.7345
146.9027
400
数据审核时,主要从及时性、准确性和完整性方面进行审核的数据是( )
A. 一手数据B. 二手数据
C. 时间序列数据
D. )
E.
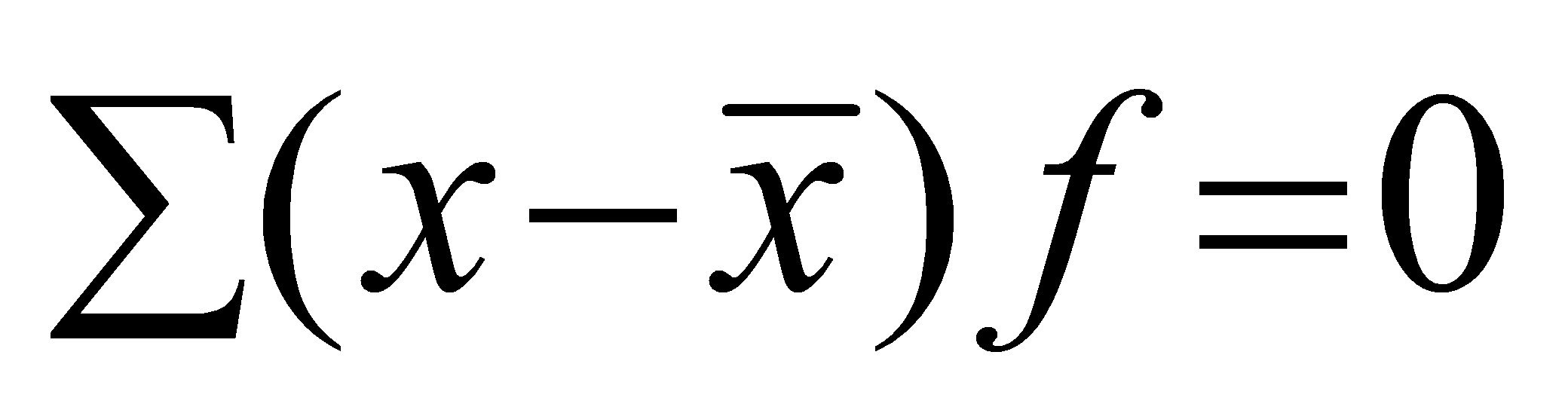
F.
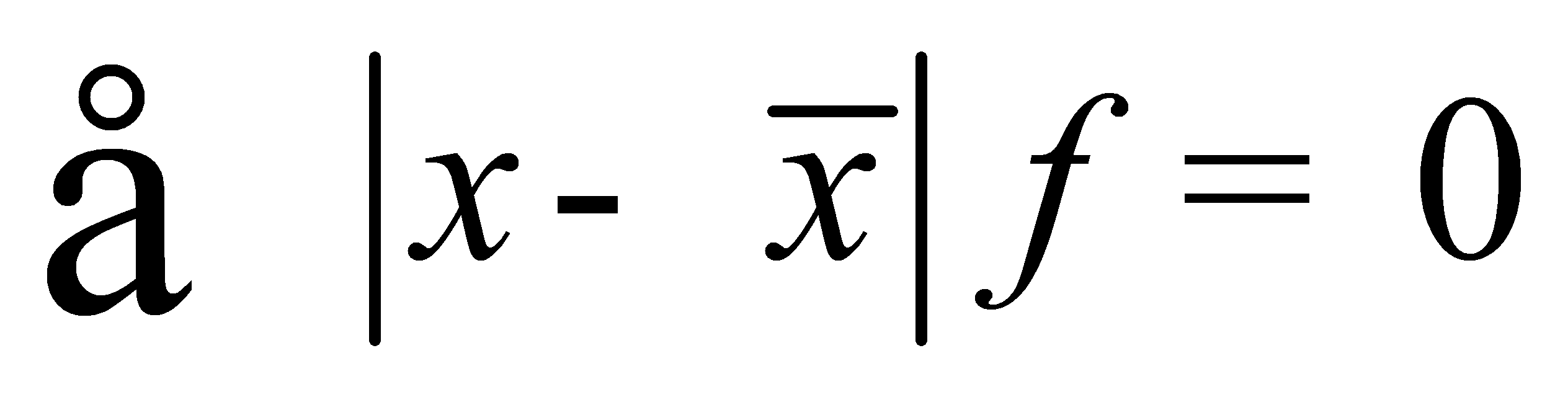
G.
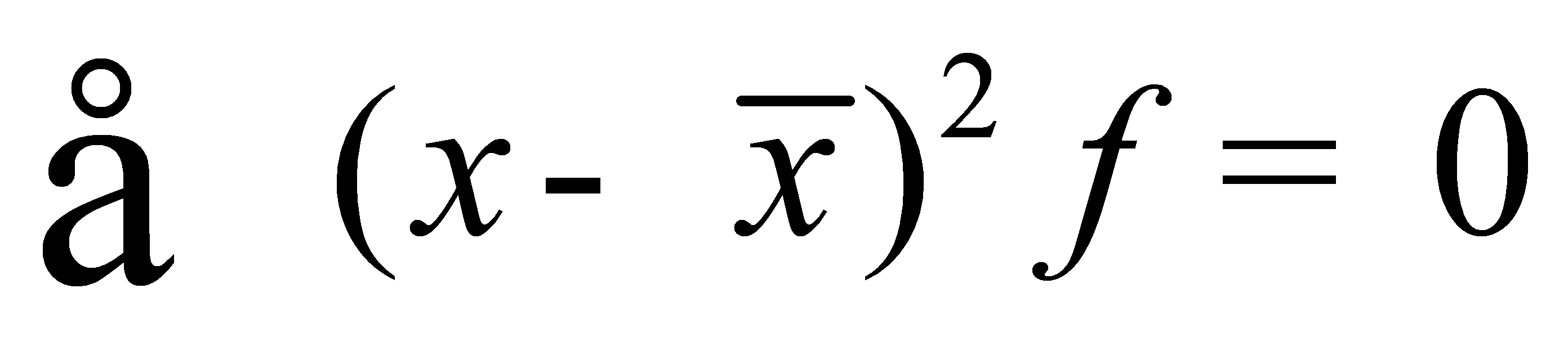
)
各组数据在组内是均匀分布的
各组次数相等
各组数据之间没有差异
)
总体单位数多少的影响
平均数大小和计量单位的影响
离散程度的影响
)
两个总体的标准差应该相等
两个总体的平均数应该相等
两个总体的离差平方和应该相等
)
事先对总体进行初步分析
按随机原则抽取样本
保证调查数据的准确性、及时性
P值中拒绝原假设理由最充分的是( A )
2%
10% C.25%
)
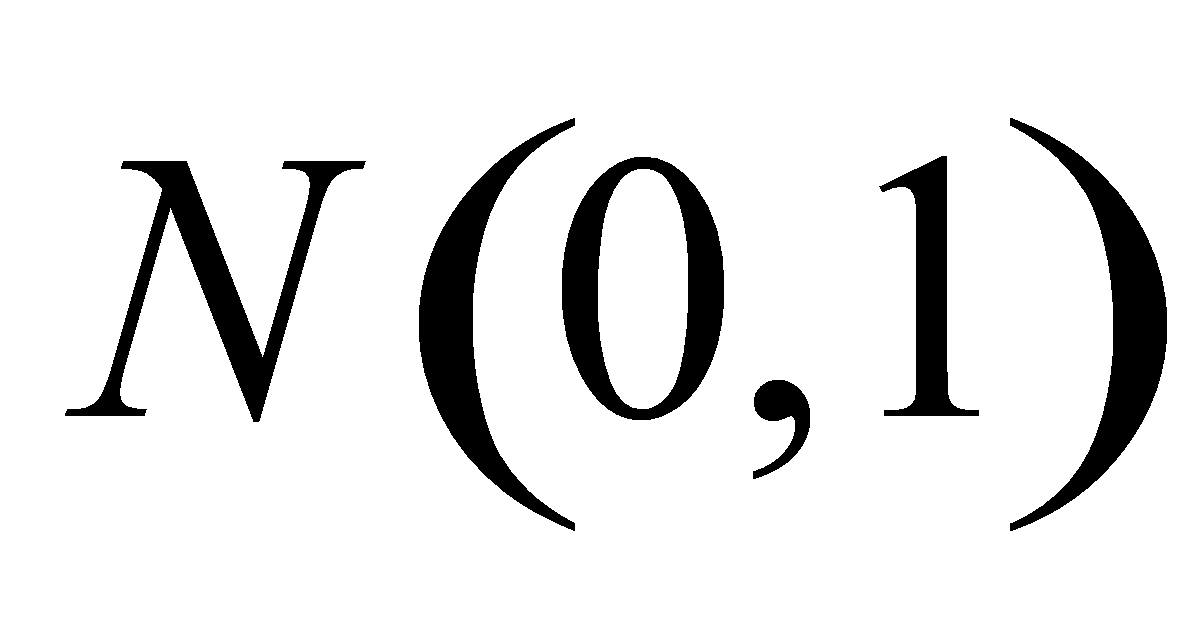
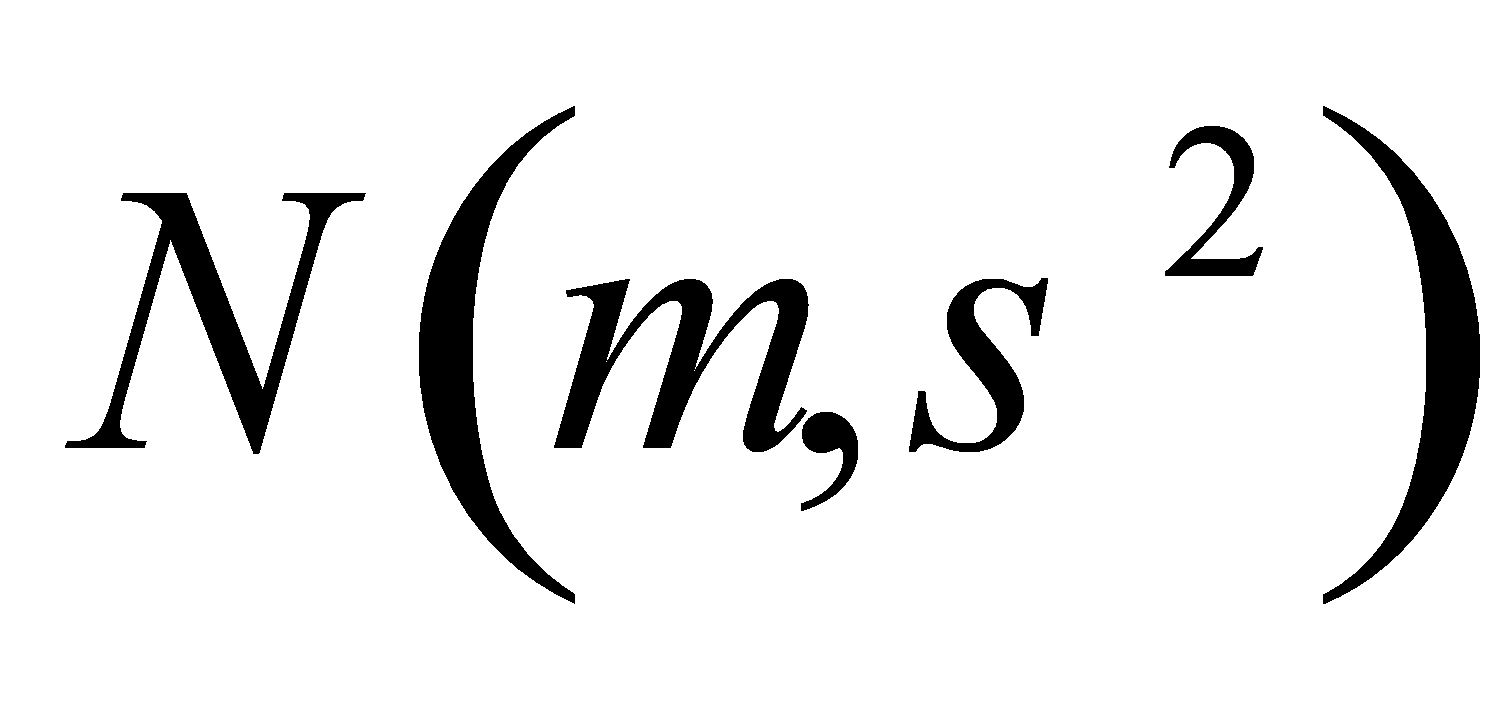
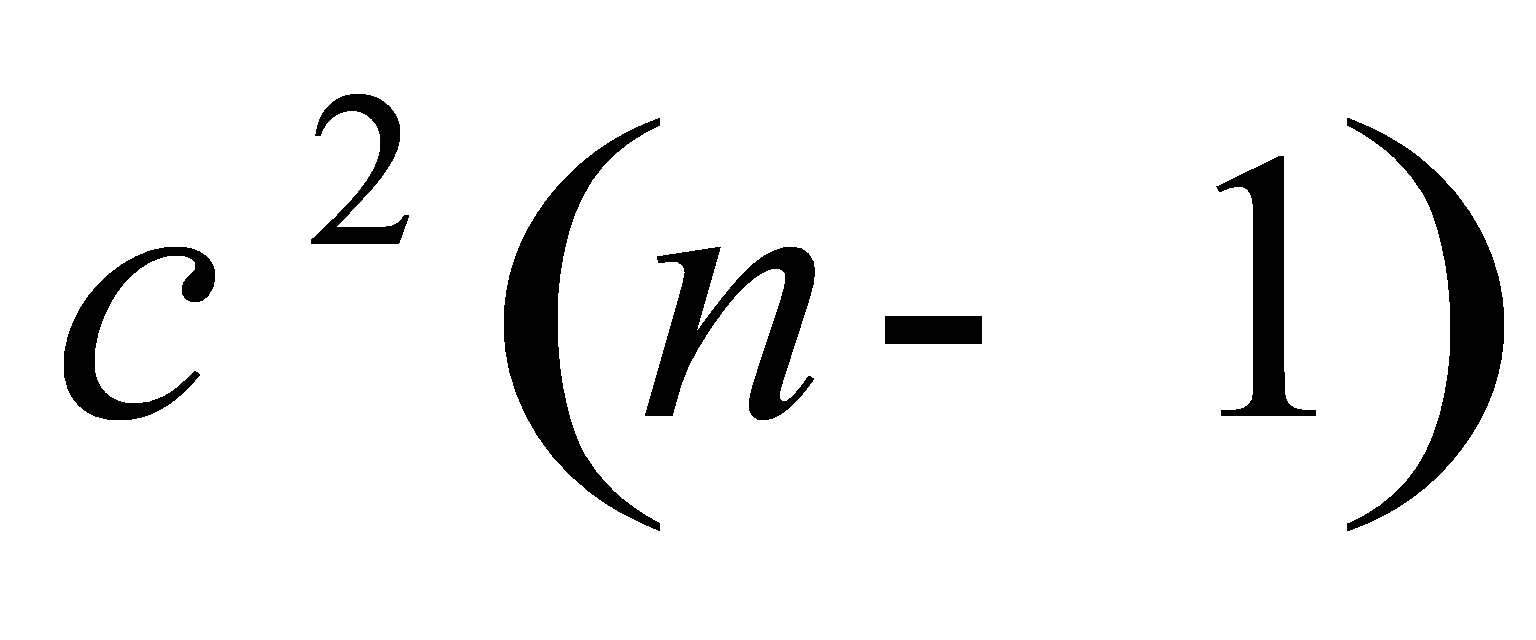
P应选( A )
85%
87%
90%
)
函数关系 B.相关关系 C.对应关系
)
函数关系 B.相关关系 C.对应关系
)
单相关
复相关
偏相关
)
线性相关关系 B.曲线相关关系 C.任何相关关系
)
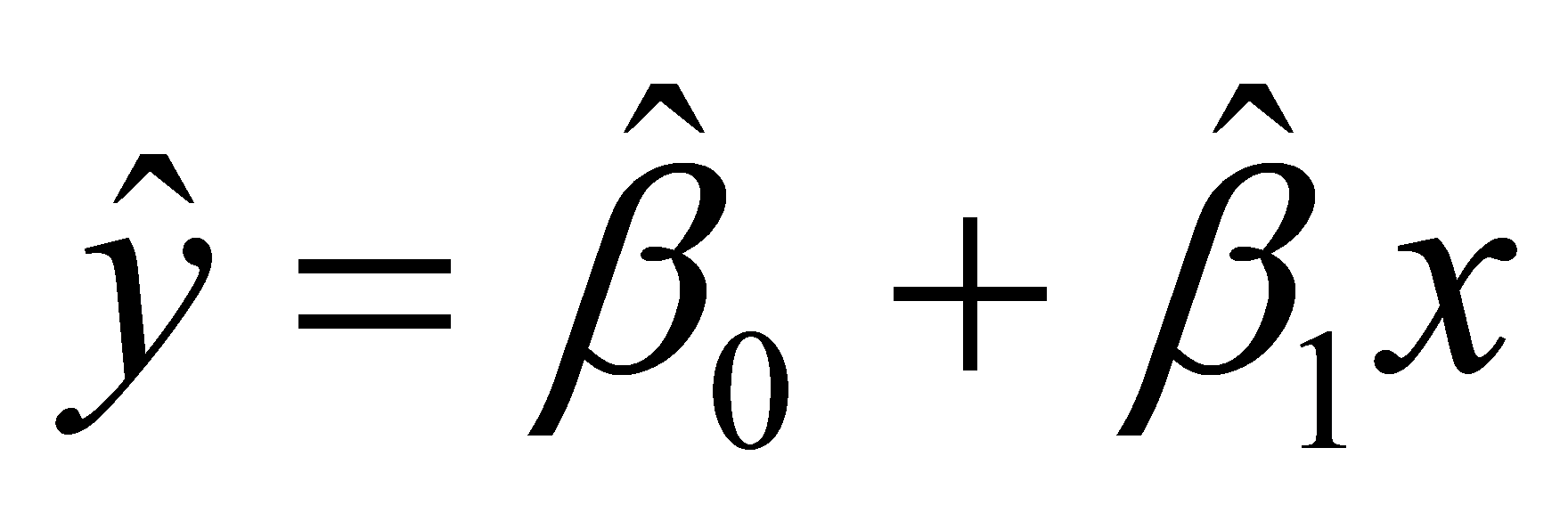
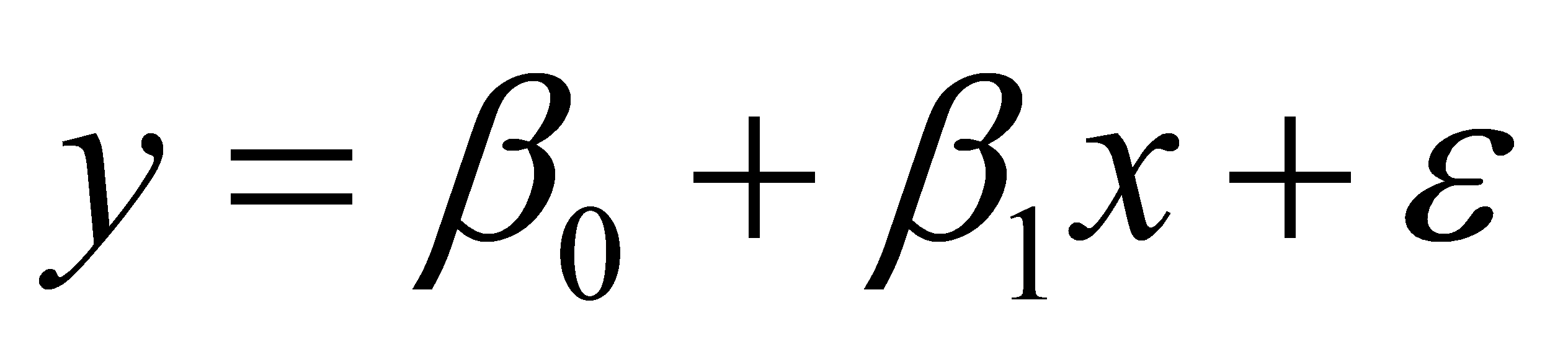
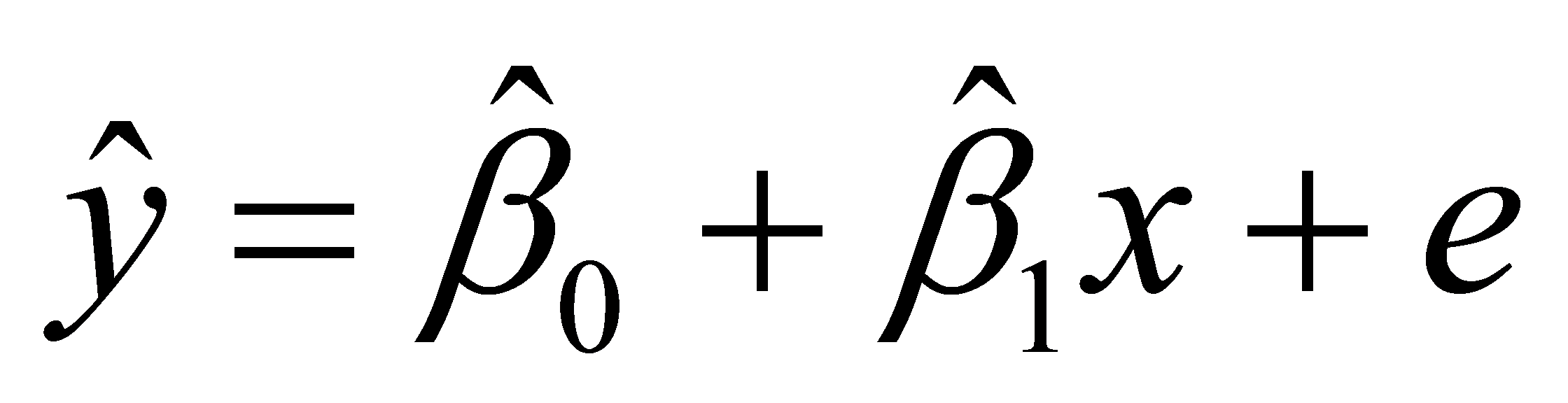
)
B. C.)A.
 B.
B.
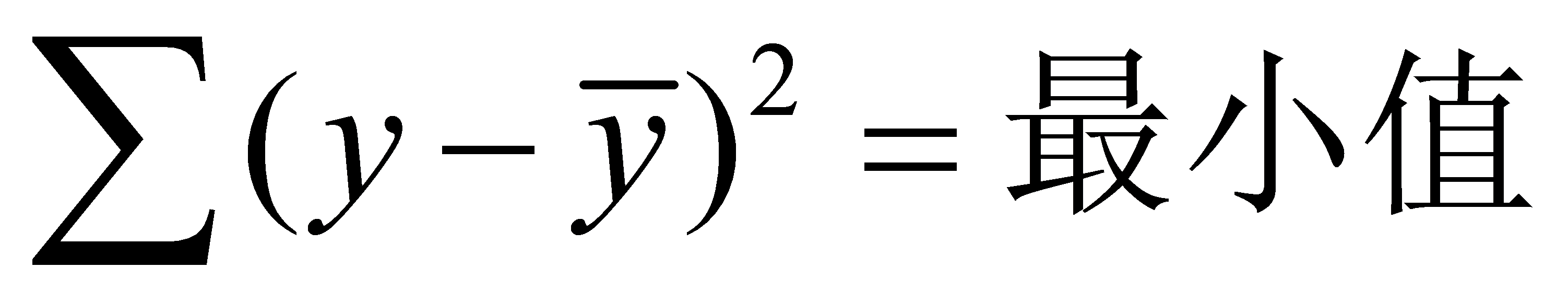
)
曲线关系
线性关系
因果关系
)
总离差平方和
回归平方和
残差平方和
)
平均数时间数列
相对数时间数列
时期数列
)
年末人口总数数列 B.年出生人数数列 C.单位播种面积的粮食产量数列
)
逐期增减量之差等于累计增减量
逐期增减量之和等于累计增减量
逐期增减量之商等于累计增减量
)
发展速度-1=增长速度
发展速度+1=增长速度
增长速度-1=发展速度
Sj的取值范围为 ( A )
0≤Sj≤4 B.0≤Sj≤1 C.0≤Sj≤12
)
15项
16项
17项
判断题
统计学是一门收集、整理和分析统计数据的实质性科学。(×)
分类数据是指只能归入某一类别的非数值型数据。 ( √ )
分类数据和顺序数据相似之处在于两者都是非数字型数据。 ( √ )
时间序列数据是指对不同单位在同一个时间点上收集的数据。(×)
从统计方法的构成看,统计学可以分为描述统计学和推断统计学。( √ )
总体的数量特征都是从每个总体单位的特征加以逐级汇总而体现出来的。( √ )
若总体中所包含的统计指标数是有限的,则称为有限总体。(×)
变量按其所受影响因素不同,可分为离散型变量和连续型变量。(×)
甲企业职工人数1248人,这是一个连续变量。 (×)
某地区2009年人均国内生产总值为13600元,这是一个离散变量。(×)
复合分组是对被研究现象总体只按一个变量进行分组。(×)
简单分组是对原始数据按两个或两个以上变量进行层叠式分组。(×)
算术平均数既适用于数值型数据,也适用于分类数据和顺序数据。( ×)
根据分组数据计算的平均数只是实际平均数的近似值。 ( √ )
众数可直观地说明分布的离散趋势,可用它反映变量值一般水平的代表值。( ×)
四分位数是将按大小顺序排列的一组数据划分为三等分的四个变量值。(×)
数据的离散程度越大,集中趋势的测度值对该组数据的代表性就越差。( √ )
偏态和峰态是对分布集中程度的测度。 ( ×)
H,不一定H是正确的。 ( √ )
Z检验。 (×)
SST是描述所有数值集中程度的数量指标。 ( √ )
方差分析采用t检验。 (×)
方差分析就是解决随机因素是否是造成数据差异的主要原因的问题。(×)
方差分析假定各水平观察值为来自正态总体的随机样本。 ( √ )
多重比较法是通过对总体均值之间的配对比较来检验是哪些均值之间存在差异的方法。 ( √ )
检验不显著,也可以对均值作多重比较。(×)
按变量之间相关关系的变化方向不同,可分为完全相关、不完全相关和不相关。(×)
当相关系数
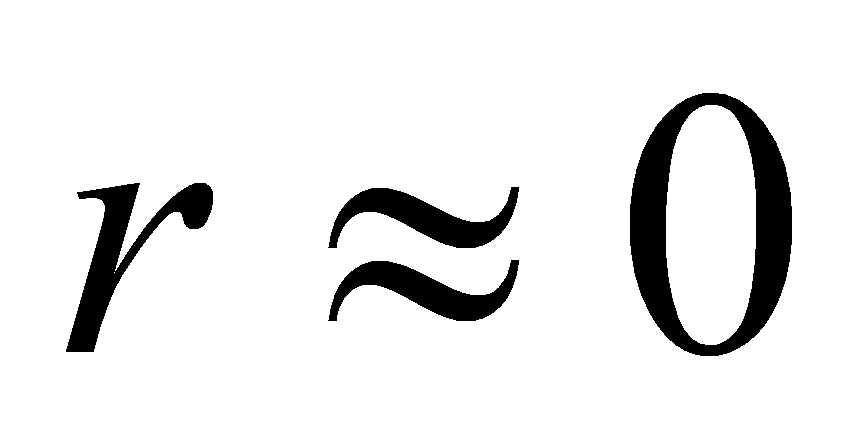 时,说明两个变量之间不存在任何相关关系。(×)
时,说明两个变量之间不存在任何相关关系。(×)当变量x与y之间存在线性相关关系时,有
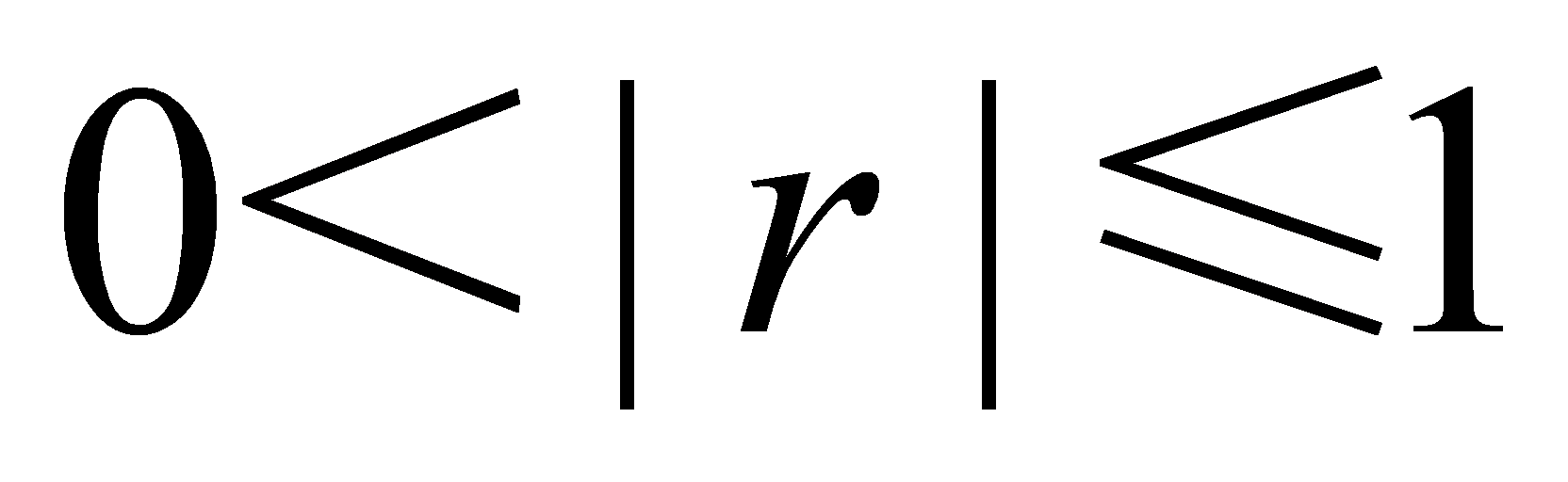 。 ( √ )
。 ( √ )回归分析中,通常假定随机误差项
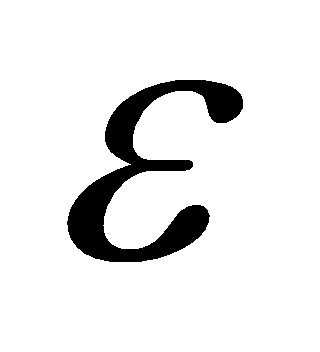 遵从正态分布,即
遵从正态分布,即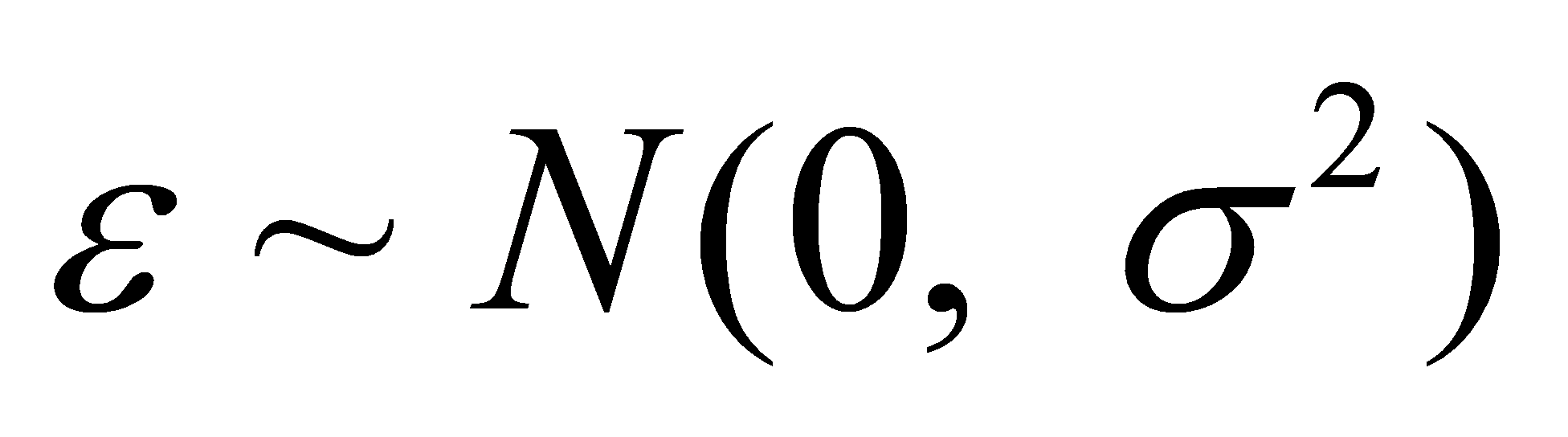 。( √ )
。( √ )最小二乘法就是寻找参数
的估计值,使残差绝对值之和达到最小。(×)检验主要用于检验回归系数的显著性。 (×)
样本决定系数等于残差平方和与总离差平方和之比,记为
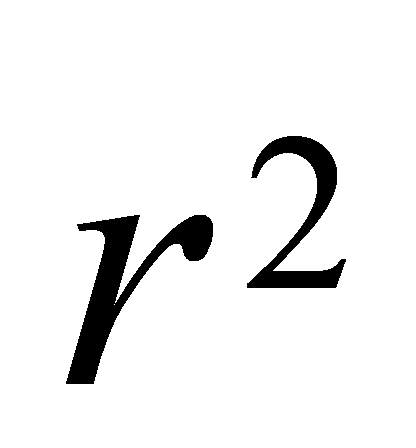 。(×)
。(×)因变量单个值的预测区间大于因变量均值的预测区间。 ( √ )
在线性相关条件下,研究两个和两个以上自变量对两个以上因变量的数量变化关系,称为多元线性回归分析。 (×)
多元线性回归模型中回归系数的最小二乘估计量是确定性变量。(×)
检验所得结论是一致的。( √ )
因为时点观察值没有长度,所以时点数列的每一观察值的大小不直接受时期长短的影响。( √ )
用趋势剔除法测定季节变动的目的是计算没有长期趋势影响的季节指数。 ( √ )
若趋势方程为
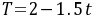 ,则该现象呈下降趋势。 ( √ )
,则该现象呈下降趋势。 ( √ )若时间数列各期的环比发展速度相等,则各期逐期增长量一定相等。(×)
平均发展水平是一种序时平均数,平均发展速度也是一种序时平均数。( √ )
用移动平均法对平稳时间数列进行预测时,若选用偶数项进行移动平均,则需要平均两次才能计算出预测值。 (×)
如果现象的发展在季度上有明显的季节变动,则其季节指数一般会大于或小于100%。( √ )
一般来说,当季节指数<400%时,表明现象此时处于淡季。(×)
预测误差是现象的观察值与预测值之差。一般来说,预测误差越小模型拟合效果越好。 ( √ )
计算题
题目解答
答案
A