题目
设X1,X2,···,X,是来自总体 -b-|||-10,0,2) 的一组样本.若 _(E)gt 0,-|||-lim _(xarrow infty ) |dfrac {1)(n)sum _(i=1)^n(X)_(i)-a|lt e} --|||-https:/img.zuoyebang.cc/zyb_d739db73f8f327d50e9624a1f21fbe5a.jpg. ,则 a= ())0,&({lim)} _(x arrow infty)|(1)/(n) {{sum)}_(i=1)^n X_i-a|
 0,\\&{{\lim}} _{x \rightarrow \infty}\{|\frac{1}{n} {{\sum}}_{i=1}^n X_i-a|<\varepsilon\}-\\&1, 则 a=()
\end {aligned}" data-width="317" data-height="147" data-size="14041" data-format="png" style="max-width:100%">
0,\\&{{\lim}} _{x \rightarrow \infty}\{|\frac{1}{n} {{\sum}}_{i=1}^n X_i-a|<\varepsilon\}-\\&1, 则 a=()
\end {aligned}" data-width="317" data-height="147" data-size="14041" data-format="png" style="max-width:100%">
题目解答
答案
 0,事件\\& \{|\frac{1}{n} {{\sum}}_{i=1}^{n} X_i - a| < \varepsilon\} 发生的概率等于\\& 1,即对于任意 \varepsilon > 0,{{\lim}}_{x \rightarrow \infty} \\&\{|\frac{1}{n} {{\sum}}_{i=1}^{n} X_i - a| < \varepsilon\} = 1。
\end {aligned}" data-width="351" data-height="575" data-size="57982" data-format="png" style="max-width:100%">
0,事件\\& \{|\frac{1}{n} {{\sum}}_{i=1}^{n} X_i - a| < \varepsilon\} 发生的概率等于\\& 1,即对于任意 \varepsilon > 0,{{\lim}}_{x \rightarrow \infty} \\&\{|\frac{1}{n} {{\sum}}_{i=1}^{n} X_i - a| < \varepsilon\} = 1。
\end {aligned}" data-width="351" data-height="575" data-size="57982" data-format="png" style="max-width:100%">
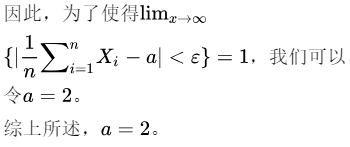
解析
步骤 1:理解题目中的记号和含义
题目中给出的记号和含义如下:
- $X \sim b(10, 0.2)$ 表示总体 $X$ 近似服从参数为 $10$ 和 $0.2$ 的二项分布。
- $X_1, X_2, \cdots, X_n$ 是从总体 $X$ 中抽取的样本。
- $\frac{1}{n} \sum_{i=1}^{n} X_i$ 表示样本均值。
- $\lim_{x \rightarrow \infty} \{|\frac{1}{n} \sum_{i=1}^{n} X_i - a| < \varepsilon\} - 1$ 表示事件 $\{|\frac{1}{n} \sum_{i=1}^{n} X_i - a| < \varepsilon\}$ 发生的概率减去 $1$。
- 我们要找到一个合适的 $a$,使得对于任意给定的 $\varepsilon > 0$,事件 $\{|\frac{1}{n} \sum_{i=1}^{n} X_i - a| < \varepsilon\}$ 发生的概率等于 $1$,即对于任意 $\varepsilon > 0$,$\lim_{x \rightarrow \infty} \{|\frac{1}{n} \sum_{i=1}^{n} X_i - a| < \varepsilon\} = 1$。
步骤 2:确定总体的期望值
由于 $X \sim b(10, 0.2)$,根据二项分布的期望公式,总体的期望值为:
$$E(X) = np = 10 \times 0.2 = 2$$
步骤 3:确定样本均值的期望值
根据大数定律,当样本量 $n$ 趋于无穷大时,样本均值 $\frac{1}{n} \sum_{i=1}^{n} X_i$ 的期望值趋近于总体的期望值,即:
$$\lim_{n \rightarrow \infty} E(\frac{1}{n} \sum_{i=1}^{n} X_i) = E(X) = 2$$
步骤 4:确定 $a$ 的值
为了使得 $\lim_{x \rightarrow \infty} \{|\frac{1}{n} \sum_{i=1}^{n} X_i - a| < \varepsilon\} = 1$,我们需要让 $a$ 等于总体的期望值,即 $a = 2$。
题目中给出的记号和含义如下:
- $X \sim b(10, 0.2)$ 表示总体 $X$ 近似服从参数为 $10$ 和 $0.2$ 的二项分布。
- $X_1, X_2, \cdots, X_n$ 是从总体 $X$ 中抽取的样本。
- $\frac{1}{n} \sum_{i=1}^{n} X_i$ 表示样本均值。
- $\lim_{x \rightarrow \infty} \{|\frac{1}{n} \sum_{i=1}^{n} X_i - a| < \varepsilon\} - 1$ 表示事件 $\{|\frac{1}{n} \sum_{i=1}^{n} X_i - a| < \varepsilon\}$ 发生的概率减去 $1$。
- 我们要找到一个合适的 $a$,使得对于任意给定的 $\varepsilon > 0$,事件 $\{|\frac{1}{n} \sum_{i=1}^{n} X_i - a| < \varepsilon\}$ 发生的概率等于 $1$,即对于任意 $\varepsilon > 0$,$\lim_{x \rightarrow \infty} \{|\frac{1}{n} \sum_{i=1}^{n} X_i - a| < \varepsilon\} = 1$。
步骤 2:确定总体的期望值
由于 $X \sim b(10, 0.2)$,根据二项分布的期望公式,总体的期望值为:
$$E(X) = np = 10 \times 0.2 = 2$$
步骤 3:确定样本均值的期望值
根据大数定律,当样本量 $n$ 趋于无穷大时,样本均值 $\frac{1}{n} \sum_{i=1}^{n} X_i$ 的期望值趋近于总体的期望值,即:
$$\lim_{n \rightarrow \infty} E(\frac{1}{n} \sum_{i=1}^{n} X_i) = E(X) = 2$$
步骤 4:确定 $a$ 的值
为了使得 $\lim_{x \rightarrow \infty} \{|\frac{1}{n} \sum_{i=1}^{n} X_i - a| < \varepsilon\} = 1$,我们需要让 $a$ 等于总体的期望值,即 $a = 2$。