题目
为研究缺氧对正常人心率和血压的影响收集 50 名 志愿者参加试验随机分为两组 要比较缺氧与非缺氧组收缩压等指标间是否有差别 应采用何种假设检验方法 _ a配对设计 t 检验b随机区组设计方差分析c 两独立样本比较的 t 检验d两样本率比较的 检验 E 两组资料比较的秩和检验
为研究缺氧对正常人心率和血压的影响收集 50 名 志愿者参加试验随机分为两组 要比较缺氧与非缺氧组收缩压等指标间是否有差别 应采用何种假设检验方法 _
a配对设计 t 检验
b随机区组设计方差分析
c 两独立样本比较的 t 检验
d两样本率比较的 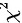 检验
检验
E 两组资料比较的秩和检验
题目解答
答案
需要比较缺氧组和非缺氧组之间的收缩压等指标是否存在差异。应该选择选项C,即使用两独立样本比较的t检验进行分析。
选项A的配对设计t检验适用于同一组参与者在不同条件下的比较,而你的情况是两组不同的参与者。
选项B的随机区组设计方差分析适用于比较多个组别之间的差异,而只有两个组别。
选项D的两样本率比较的检验适用于比较两个分类变量的比例差异,需要比较的是连续变量(收缩压)。
选项E的两组资料比较的秩和检验适用于非参数检验,适合于样本不满足正态分布的情况。如果数据不满足正态分布假设,可以考虑使用秩和检验。
综上所述,你应该选择选项C,即使用两独立样本比较的t检验进行分析。
解析
步骤 1:确定研究设计类型
研究设计是将50名志愿者随机分为两组,一组接受缺氧处理,另一组不接受缺氧处理。这是典型的两组独立样本设计,因为两组参与者是独立的,没有配对关系。
步骤 2:确定变量类型
需要比较的变量是收缩压,这是一个连续变量。因此,需要使用适合连续变量的统计检验方法。
步骤 3:选择合适的统计检验方法
由于是两组独立样本的比较,且变量是连续变量,因此应该使用两独立样本比较的t检验。配对设计t检验适用于同一组参与者在不同条件下的比较,随机区组设计方差分析适用于比较多个组别之间的差异,两样本率比较的${x}^{2}$检验适用于比较两个分类变量的比例差异,两组资料比较的秩和检验适用于非参数检验,适合于样本不满足正态分布的情况。根据题目描述,两独立样本比较的t检验是最合适的方法。
研究设计是将50名志愿者随机分为两组,一组接受缺氧处理,另一组不接受缺氧处理。这是典型的两组独立样本设计,因为两组参与者是独立的,没有配对关系。
步骤 2:确定变量类型
需要比较的变量是收缩压,这是一个连续变量。因此,需要使用适合连续变量的统计检验方法。
步骤 3:选择合适的统计检验方法
由于是两组独立样本的比较,且变量是连续变量,因此应该使用两独立样本比较的t检验。配对设计t检验适用于同一组参与者在不同条件下的比较,随机区组设计方差分析适用于比较多个组别之间的差异,两样本率比较的${x}^{2}$检验适用于比较两个分类变量的比例差异,两组资料比较的秩和检验适用于非参数检验,适合于样本不满足正态分布的情况。根据题目描述,两独立样本比较的t检验是最合适的方法。