题目
测定试样中P2O5质量分数(%),数据如下:8。44,8.32,8.45,8.52,8.69,8。38 .用Q检验法对可疑数据决定取舍,求平均值、平均偏差、标准偏差s和置信度选90%及99%的平均值的置信范围。(13分).
测定试样中P2O5质量分数(%),数据如下:8。44,8.32,8.45,8.52,8.69,8。38 .用Q检验法对可疑数据决定取舍,求平均值、平均偏差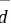 、标准偏差s和置信度选90%及99%的平均值的置信范围。(13分)
、标准偏差s和置信度选90%及99%的平均值的置信范围。(13分)
题目解答
答案
解:将测定值由小到大排列 8。32,8.38,8。44,8.45,8。52,8。69.可疑值为xn
(1) 用Q值检验法
Q计算 =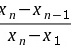 =
=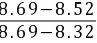 =0。46
=0。46
查表2-4,n=6时, Q0.90=0。56 Q计算表
故8.69%应予保留。两种判断方法所得结论一致。
(2) 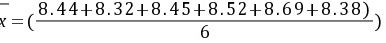 %=8.47%
%=8.47%
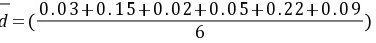 %=0。09%
%=0。09%
s=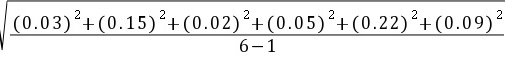 =0.13%
=0.13%
(3) 查表2—2,置信度为90%,n=6时,t=2.015
因此 μ=(8。47±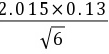 )=(8.47±0。11)%
)=(8.47±0。11)%
同理,对于置信度为99%,可得
μ=(8.47±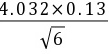 )%=(8。47±0.21)%
)%=(8。47±0.21)%
解析
步骤 1:数据排序
将测定值由小到大排列:8.32, 8.38, 8.44, 8.45, 8.52, 8.69。可疑值为8.69%。
步骤 2:Q值检验法
计算Q值:$Q_{计算} = \dfrac{{x}_{n}-{x}_{n-1}}{{x}_{n}-{x}_{1}} = \dfrac{8.69-8.52}{8.69-8.32} = 0.46$。
查表2-4,n=6时,$Q_{0.90}=0.56$,$Q_{0.99}=0.74$。因为$Q_{计算} < Q_{0.90}$,所以8.69%应予保留。
步骤 3:计算平均值、平均偏差和标准偏差
平均值:$\overline{x} = \dfrac{8.44+8.32+8.45+8.52+8.69+8.38}{6} = 8.47\%$。
平均偏差:$\overrightarrow{d} = \dfrac{0.03+0.15+0.02+0.05+0.22+0.09}{6} = 0.09\%$。
标准偏差:$s = \sqrt{\dfrac{{(0.03)}^{2}+{(0.15)}^{2}+{(0.02)}^{2}+{(0.05)}^{2}+{(0.22)}^{2}+{(0.09)}^{2}}{6-1}} = 0.13\%$。
步骤 4:计算置信范围
查表2-2,置信度为90%,n=6时,$t=2.015$。
置信度为90%的平均值的置信范围:$\mu = (8.47 \pm 2.015 \times 0.13) = (8.47 \pm 0.11)\%$。
置信度为99%的平均值的置信范围:$\mu = (8.47 \pm 4.032 \times 0.13) = (8.47 \pm 0.21)\%$。
将测定值由小到大排列:8.32, 8.38, 8.44, 8.45, 8.52, 8.69。可疑值为8.69%。
步骤 2:Q值检验法
计算Q值:$Q_{计算} = \dfrac{{x}_{n}-{x}_{n-1}}{{x}_{n}-{x}_{1}} = \dfrac{8.69-8.52}{8.69-8.32} = 0.46$。
查表2-4,n=6时,$Q_{0.90}=0.56$,$Q_{0.99}=0.74$。因为$Q_{计算} < Q_{0.90}$,所以8.69%应予保留。
步骤 3:计算平均值、平均偏差和标准偏差
平均值:$\overline{x} = \dfrac{8.44+8.32+8.45+8.52+8.69+8.38}{6} = 8.47\%$。
平均偏差:$\overrightarrow{d} = \dfrac{0.03+0.15+0.02+0.05+0.22+0.09}{6} = 0.09\%$。
标准偏差:$s = \sqrt{\dfrac{{(0.03)}^{2}+{(0.15)}^{2}+{(0.02)}^{2}+{(0.05)}^{2}+{(0.22)}^{2}+{(0.09)}^{2}}{6-1}} = 0.13\%$。
步骤 4:计算置信范围
查表2-2,置信度为90%,n=6时,$t=2.015$。
置信度为90%的平均值的置信范围:$\mu = (8.47 \pm 2.015 \times 0.13) = (8.47 \pm 0.11)\%$。
置信度为99%的平均值的置信范围:$\mu = (8.47 \pm 4.032 \times 0.13) = (8.47 \pm 0.21)\%$。