12.设总体X的概率密度为 (x;theta )= ) (e)^-(x-theta ), xgeqslant theta 0, xlt theta . ;-|||-而X1,X2,···,Xn是来自总体X的简单随机样本,求未知参数θ的矩估计量及最大似然估计-|||-量.
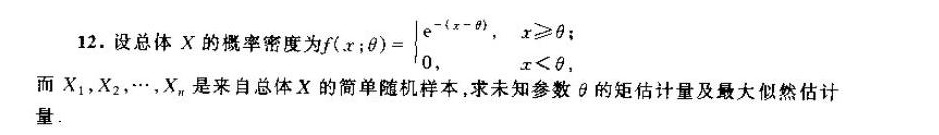
题目解答
答案
解析
题目考察知识
本题主要考察矩估计量和最大似然估计量的计算方法,具体涉及指数分布类型的总体概率密度函数。
一、矩估计量计算
思路:用样本矩估计总体矩
总体X的概率密度为:
$f(x;\theta) = \begin{cases} e^{-(x-\theta)} & x\geq\theta \\ 0 & x<\theta \end{cases}$
这是移位指数分布(参数为1,位移θ),需先计算总体的一阶原点矩(期望)$E(X)$,再用样本均值$\overline{X}$估计$E(X)$,解出θ的估计量。
步骤1:计算$E(X)$
$E(X) = \int_{\theta}^{\infty} x \cdot e^{-(x-\theta)} dx$
令$t = x - \theta$,则$x = t + \theta$,$dx = dt$,积分变为:
$E(X) = \int_{0}^{\infty} (t + \theta) e^{-t} dt = \int_{0}^{\infty} t e^{-t} dt + \theta \int_{0}^{\infty} e^{-t} dt$
- $\int_{0}^{\infty} t e^{-t} dt = 1$(伽马函数$\Gamma(2)=1$)
- $\int_{0}^{\infty} e^{-t} dt = 1$(指数分布积分)
故$E(X) = 1 + \theta$。
步骤2:用样本矩估计总体矩
样本一阶矩为$\overline{X} = \frac{1}{n}\sum_{i=1}^n X_i$,令$\overline{X} = E(X)$:
$\overline{X} = 1 + \theta \implies \theta_{ME} = \overline{X} - 1$
二、最大似然估计量计算
思路:构造似然函数,求最大化参数
步骤1:构造似然函数
样本$X_1,X_2,\dots,X_n$的似然函数为各密度函数乘积:
$L(\theta) = \prod_{i=1}^n f(X_i;\theta) = \begin{cases} \prod_{i=1}^n e^{-(X_i - \theta)} & X_i\geq\theta \ (\forall i) \\ 0 & \text{否则} \end{cases}$
化简得:
$L(\theta) = e^{-\sum_{i=1}^n (X_i - \theta)} = e^{-n\overline{X} + n\theta} \quad (\text{当} \theta \leq \min X_i)$
步骤2:求似然函数最大化
对数似然函数:
$\ln L(\theta) = -n\overline{X} + n\theta$
$\ln L(\theta)$是θ的严格增函数(导数$\frac{d\ln L}{d\theta}=n>0$),要最大化$\ln L(\theta)$,需θ尽可能大,但受约束$\theta \leq \min X_i$(否则$L(\theta)=0$)。
故θ的最大似然估计量为:
$\theta_{MI} = \min\{X_1,X_2,\dots,X_n\}$