题目
下图是四个地区不同盈利情况的百货公司个数统计(单位:个)。根据表格回答下列问题:三年级下册-|||-盈利 A地区 B地区 C地区 D地区-|||-高 30 150 50 100-|||-中等偏上 20 300 50 50-|||-中等偏下 100 90 100 70-|||-低 50 60 200 80在这四个地区中,哪一种家庭所占比例最低( )。高 B.中等偏上C.中等偏下 D.低
下图是四个地区不同盈利情况的百货公司个数统计(单位:个)。根据表格回答下列问题:
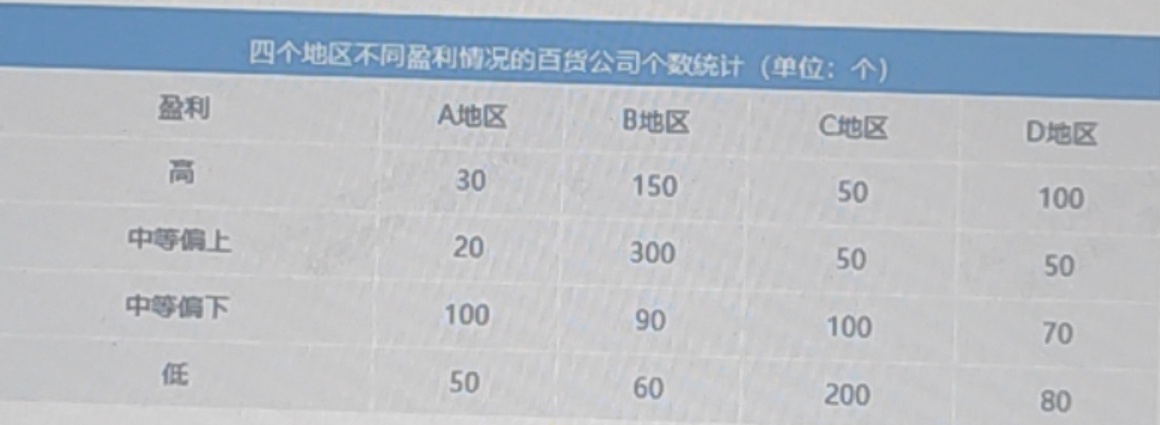
在这四个地区中,哪一种家庭所占比例最低( )。
- 高 B.中等偏上
C.中等偏下 D.低
题目解答
答案
解:首先求数据的总合,如下图
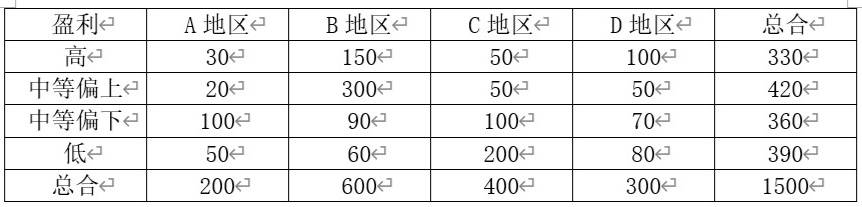
高盈利家庭占330÷1500=0.22=22%
中等偏上盈利家庭占420÷1500=0.28=28%
中等偏下盈利家庭占360÷1500=0.24=24%
低盈利家庭占390÷1500=0.26=26%
由此可见,高盈利家庭所占比例最低
故选A.
解析
考查要点:本题主要考查比例计算与比较的能力,需要根据表格数据计算不同盈利类别在整体中的占比,并找出比例最低的类别。
解题核心思路:
- 计算每个盈利类别在四个地区的总数量(如“高盈利”总共有多少个百货公司)。
- 计算所有类别总数量的总和(即所有数据的总和)。
- 分别计算每个盈利类别的占比(用类别总数量除以总数量)。
- 比较各占比,找出最小值对应的类别。
关键点:
- 正确求和是基础,需注意不要漏加或重复计算。
- 占比计算需统一以总数量为分母,而非单个地区的数量。
步骤1:计算每个盈利类别的总数量
- 高盈利:$30 + 150 + 50 + 100 = 330$
- 中等偏上:$20 + 300 + 50 + 50 = 420$
- 中等偏下:$100 + 90 + 100 + 70 = 360$
- 低盈利:$50 + 60 + 200 + 80 = 390$
步骤2:计算总数量
所有数据总和为:
$330 + 420 + 360 + 390 = 1500$
步骤3:计算各盈利类别的占比
- 高盈利占比:$\frac{330}{1500} = 0.22 = 22\%$
- 中等偏上占比:$\frac{420}{1500} = 0.28 = 28\%$
- 中等偏下占比:$\frac{360}{1500} = 0.24 = 24\%$
- 低盈利占比:$\frac{390}{1500} = 0.26 = 26\%$
步骤4:比较占比
通过计算可知,高盈利占比最低(22%),因此答案为选项A。