题目
十、(7分)设供电站供应某地区1000户居民用电,各户用电情况相互独立。已 知每户每日用电量(单位:度)服从[0, 20]上的均匀分布,利用中心极限定 理求这1 000户居民每日用电量超过10 100度的概率。(所求概率用标准正 态分布函数①(切的值表示).
十、(7分)设供电站供应某地区1000户居民用电,各户用电情况相互独立。已 知每户每日用电量(单位:度)服从[0, 20]上的均匀分布,利用中心极限定 理求这1 000户居民每日用电量超过10 100度的概率。(所求概率用标准正 态分布函数①(切的值表示).
题目解答
答案
解:用X,表示第i户居民的用电量,则X,~〃[0,20]⏺
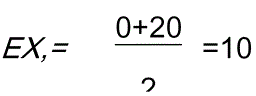
1000
则1000户居民的用电量为x=£xz ,山独立同分布中心极限定理 r-l
p{x > 10100 } = 1 一 p{x S 10100 }
X-1000xl0^10100-1000xl0
•1000x122 ■
10100-1000x10
— ) I 100 V,100°x —
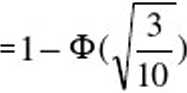
⏺
解析
步骤 1:定义随机变量
设X_i表示第i户居民的每日用电量,其中i=1,2,...,1000。根据题意,X_i服从[0,20]上的均匀分布。
步骤 2:计算期望和方差
对于均匀分布,期望E(X_i)和方差Var(X_i)分别为:
E(X_i) = (0 + 20) / 2 = 10
Var(X_i) = (20^2 - 0^2) / 12 = 400 / 12 = 100 / 3
步骤 3:应用中心极限定理
设X为1000户居民的总用电量,即X = X_1 + X_2 + ... + X_1000。根据中心极限定理,当样本量足够大时,X的分布近似于正态分布。因此,X的期望和方差分别为:
E(X) = 1000 * E(X_i) = 1000 * 10 = 10000
Var(X) = 1000 * Var(X_i) = 1000 * (100 / 3) = 100000 / 3
标准差σ = √(Var(X)) = √(100000 / 3) = 100√(10 / 3)
步骤 4:计算概率
我们需要计算P(X > 10100)。根据正态分布的性质,可以将X标准化为标准正态分布Z:
Z = (X - E(X)) / σ = (X - 10000) / (100√(10 / 3))
因此,P(X > 10100) = P(Z > (10100 - 10000) / (100√(10 / 3))) = P(Z > 100 / (100√(10 / 3))) = P(Z > √(3 / 10))
设X_i表示第i户居民的每日用电量,其中i=1,2,...,1000。根据题意,X_i服从[0,20]上的均匀分布。
步骤 2:计算期望和方差
对于均匀分布,期望E(X_i)和方差Var(X_i)分别为:
E(X_i) = (0 + 20) / 2 = 10
Var(X_i) = (20^2 - 0^2) / 12 = 400 / 12 = 100 / 3
步骤 3:应用中心极限定理
设X为1000户居民的总用电量,即X = X_1 + X_2 + ... + X_1000。根据中心极限定理,当样本量足够大时,X的分布近似于正态分布。因此,X的期望和方差分别为:
E(X) = 1000 * E(X_i) = 1000 * 10 = 10000
Var(X) = 1000 * Var(X_i) = 1000 * (100 / 3) = 100000 / 3
标准差σ = √(Var(X)) = √(100000 / 3) = 100√(10 / 3)
步骤 4:计算概率
我们需要计算P(X > 10100)。根据正态分布的性质,可以将X标准化为标准正态分布Z:
Z = (X - E(X)) / σ = (X - 10000) / (100√(10 / 3))
因此,P(X > 10100) = P(Z > (10100 - 10000) / (100√(10 / 3))) = P(Z > 100 / (100√(10 / 3))) = P(Z > √(3 / 10))