题目
设总体 X 服从两点分布 b ( 1 , p ), 一个样本观测值为 0 , 0 , 1 , 1 , 0 ,则参数 p 的极大似然估计值为( )A 0.4B 0.6C 2D 0.2
设总体 X 服从两点分布 b ( 1 , p ), 一个样本观测值为 0 , 0 , 1 , 1 , 0 ,则参数 p 的极大似然估计值为
( )
A 0.4
B 0.6
C 2
D 0.2
题目解答
答案
本题的答案选A。
两点分布可以写为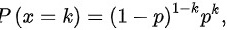
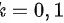 ;
;
由极大似然估计的定义知,设极大似然函数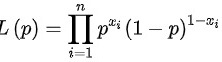 ,取对数得到:
,取对数得到:
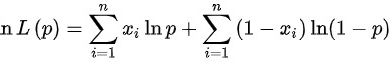
然后对上式求导,令其等于0: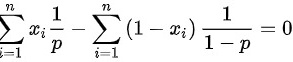
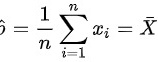
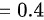 。
。
解析
考查要点:本题主要考查两点分布(伯努利分布)的极大似然估计的应用,需要掌握似然函数的构造、对数似然函数的求导及极值求解。
解题核心思路:
- 写出似然函数:根据样本观测值,构造概率乘积形式的似然函数。
- 取对数简化计算:将乘积转化为对数和,便于求导。
- 求导并解方程:通过对数似然函数对参数$p$求导,令导数为零,解方程得到极大似然估计值。
- 直接结论法:在伯努利分布中,极大似然估计值$\hat{p}$等于样本均值$\bar{X}$。
破题关键点:
- 正确识别样本中成功次数(取值为1的样本数)。
- 利用对数似然函数的导数公式,快速求解方程。
步骤1:构造似然函数
样本观测值为$0,0,1,1,0$,其中:
- 成功次数(取值为1):$n_1 = 2$,
- 失败次数(取值为0):$n_0 = 3$。
似然函数为:
$L(p) = \prod_{i=1}^5 P(X=x_i) = (1-p)^{n_0} \cdot p^{n_1} = (1-p)^3 \cdot p^2.$
步骤2:取对数并求导
对数似然函数为:
$\ln L(p) = 3\ln(1-p) + 2\ln p.$
对$p$求导并令导数为零:
$\frac{d}{dp} \ln L(p) = -\frac{3}{1-p} + \frac{2}{p} = 0.$
步骤3:解方程求$p$
整理方程:
$\frac{3}{1-p} = \frac{2}{p} \implies 3p = 2(1-p) \implies 5p = 2 \implies \hat{p} = \frac{2}{5} = 0.4.$
直接结论法(验证)
在伯努利分布中,极大似然估计值$\hat{p}$等于样本均值$\bar{X}$:
$\bar{X} = \frac{1}{5}(0+0+1+1+0) = \frac{2}{5} = 0.4.$