题目
据下表资料,如果服用两药后的血压下降值服从正态分布,能否认为服用这两种降压药后,两血压下降值总体均数相等。服两药后血压下降的mmHg值-|||-N x s-|||-甲药 30 12.3 2.0-|||-乙药 30 24.0 2.5A.不能,因为12.3小于24.0B.需作两样本比较的单侧t检验才能定C.需作两样本比较的双侧t检验才能定D.需作两样本比较的单侧u检验才能定E.需作两样本比较的双侧u检验才能定
据下表资料,如果服用两药后的血压下降值服从正态分布,能否认为服用这两种降压药后,两血压下降值总体均数相等。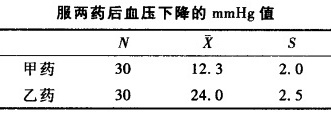
A.不能,因为12.3小于24.0
B.需作两样本比较的单侧t检验才能定
C.需作两样本比较的双侧t检验才能定
D.需作两样本比较的单侧u检验才能定
E.需作两样本比较的双侧u检验才能定
题目解答
答案
官方提供
C假设检验里建立假设有两种。一是无效假设,符号为H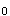 ,假设两总体均数相等(μ=μ),即样本均数
,假设两总体均数相等(μ=μ),即样本均数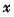 所代表的总体均数μ与假设和总体均数μ相等。和μ差别仅仅由抽样误差所致;二是备择假设,符号为H
所代表的总体均数μ与假设和总体均数μ相等。和μ差别仅仅由抽样误差所致;二是备择假设,符号为H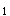 ,二者都是根据推断的目的提出的对总体特征的假设。这里还有双侧检验和单侧检验之分,需根据研究目的和专业知识而定。
,二者都是根据推断的目的提出的对总体特征的假设。这里还有双侧检验和单侧检验之分,需根据研究目的和专业知识而定。
,假设两总体均数相等(μ=μ),即样本均数所代表的总体均数μ与假设和总体均数μ相等。和μ差别仅仅由抽样误差所致;二是备择假设,符号为H,二者都是根据推断的目的提出的对总体特征的假设。这里还有双侧检验和单侧检验之分,需根据研究目的和专业知识而定。解析
本题考查假设检验方法的选择,核心在于判断何时使用t检验或u检验,以及确定检验的单侧或双侧。
- 关键点1:题目中给出的是样本均数和样本标准差(而非总体方差),且样本量为30,属于小样本(通常n<30为小样本),因此应选择t检验。
- 关键点2:题目问“能否认为总体均数相等”,即检验两总体均数是否有差异,未限定方向(如“甲药不低于乙药”),因此需选择双侧检验。
综上,正确方法是两样本双侧t检验。
1. 检验类型选择
- t检验 vs u检验:
当总体方差未知且样本量较小时(通常n<30),使用t检验;若总体方差已知或样本量足够大(n≥30),可用u检验。本题中,题目仅给出样本标准差(s),未提及总体方差,且样本量为30(接近小样本边界),因此应选择t检验。 - 单侧 vs 双侧:
题目问“是否相等”,未限定方向(如“甲药是否更优”),需检验是否有任意方向的差异,因此选择双侧检验。
2. 选项分析
- 选项C(双侧t检验)符合上述条件。
- 选项E(双侧u检验)错误,因为总体方差未知,且样本量未明确达到大样本标准。
- 选项A直接比较样本均数,未考虑抽样误差,结论不可靠。
- 选项B、D(单侧检验)错误,因题目未要求方向性判断。