题目
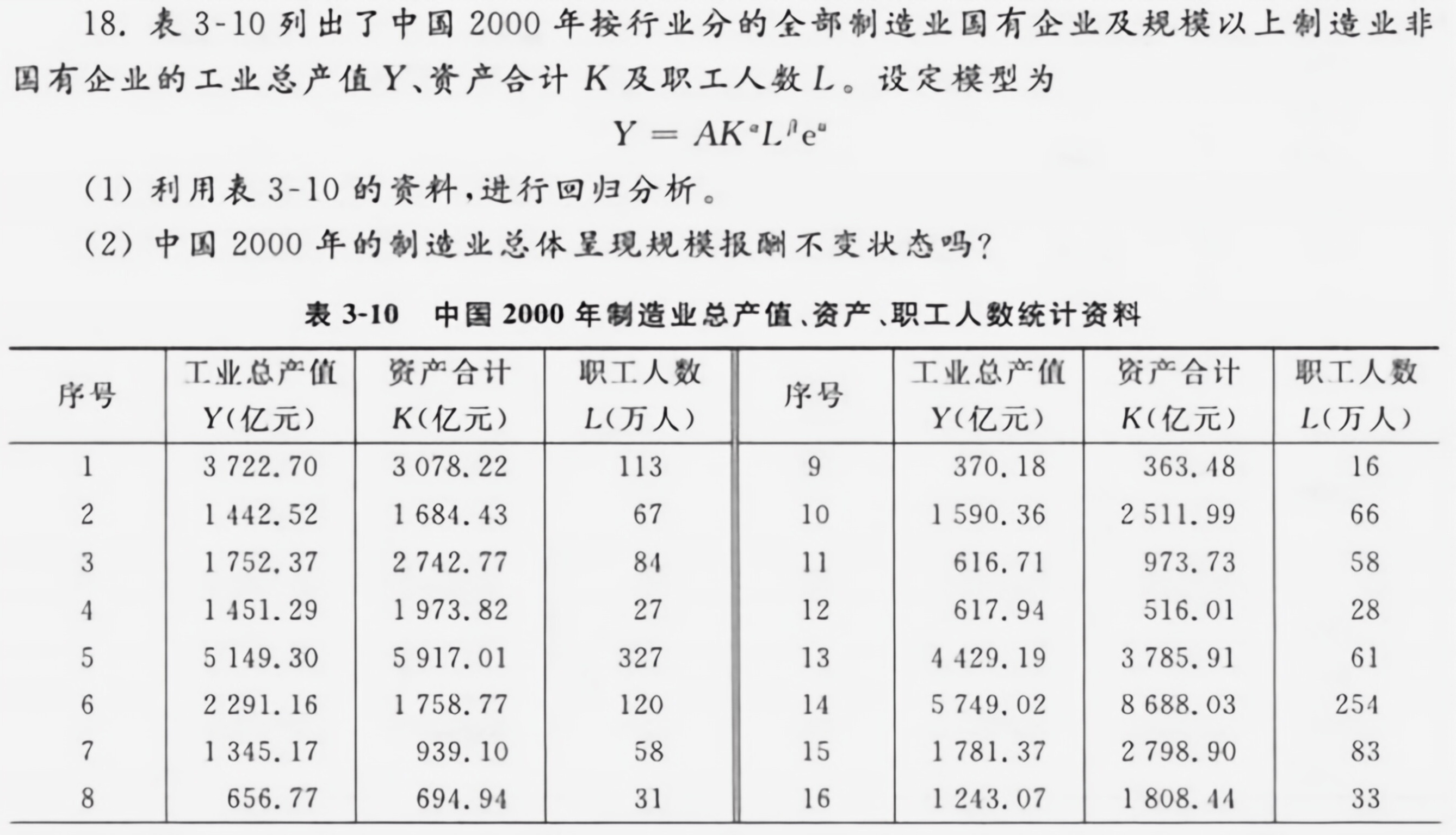
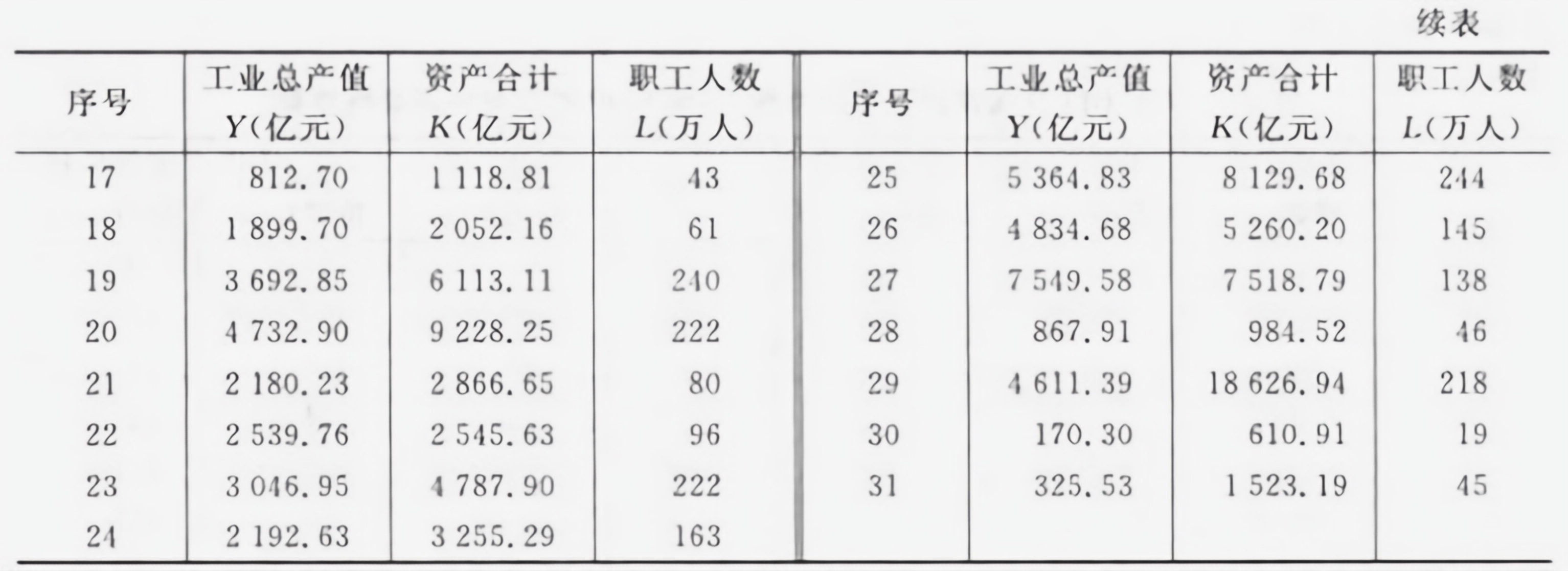
18.表 3-10 列出了中国2000年按行业分的全部制造业国有企业及规模以上制造业非-|||-国有企业的工业总产值Y、资产合计K及职工人数L。设定模型为-|||-=AKcdot (L)^n(e)^u-|||-(1)利用表 3-10 的资料,进行回归分析。-|||-(2)中国2000年的制造业总体呈现规模报酬不变状态吗?-|||-表 3-10 中国2000年制造业总产值、资产、职工人数统计资料-|||-序号 Y(亿元) K(亿元) L(万人) Y(亿元) K(亿元) L(万人)-|||-工业总产值 资产合计 职工人数 序号 工业总产值 资产合计 职工人数-|||-1 3722.70 3078.22 113 9 370.18 363.48 16-|||-2 1442.52 1684.43 67 10 1590.36 2511.99 66-|||-3 1752.37 2742.77 84 11 616.71 973.73 58-|||-4 1451.29 1973.82 27 12 617.94 516.01 28-|||-5 5149.30 5917.01 327 13 4429.19 3785.91 61-|||-6 2291.16 1758.77 120 14 5749.02 8688.03 254-|||-7 1345.17 939.10 58 15 1781.37 2798.90 83-|||-8 656.77 694.94 31 16 1243.07 1808.44 3318.表 3-10 列出了中国2000年按行业分的全部制造业国有企业及规模以上制造业非-|||-国有企业的工业总产值Y、资产合计K及职工人数L。设定模型为-|||-=AKcdot (L)^n(e)^u-|||-(1)利用表 3-10 的资料,进行回归分析。-|||-(2)中国2000年的制造业总体呈现规模报酬不变状态吗?-|||-表 3-10 中国2000年制造业总产值、资产、职工人数统计资料-|||-序号 Y(亿元) K(亿元) L(万人) Y(亿元) K(亿元) L(万人)-|||-工业总产值 资产合计 职工人数 序号 工业总产值 资产合计 职工人数-|||-1 3722.70 3078.22 113 9 370.18 363.48 16-|||-2 1442.52 1684.43 67 10 1590.36 2511.99 66-|||-3 1752.37 2742.77 84 11 616.71 973.73 58-|||-4 1451.29 1973.82 27 12 617.94 516.01 28-|||-5 5149.30 5917.01 327 13 4429.19 3785.91 61-|||-6 2291.16 1758.77 120 14 5749.02 8688.03 254-|||-7 1345.17 939.10 58 15 1781.37 2798.90 83-|||-8 656.77 694.94 31 16 1243.07 1808.44 33
题目解答
答案



解析
题目考察知识和解题思路
本题主要考察C-D生产函数的回归分析及规模报酬判断,具体步骤如下:
(1)回归分析过程
模型设定为 $Y = AK^\alpha L^\beta e^u$,为线性化需两边取对数:
$\ln Y = \ln A + \alpha \ln K + \beta \ln L + u$
关键步骤:
- 数据处理:使用EViews对31个样本数据进行OLS回归,得到以下结果:
- 截距项:$\ln \hat{A} = 1.1540$($t=1.5860$,$p=0.1240>0.05$,不显著)
- 资本弹性:$\hat{\alpha} = -0.6092$($t=3.4541$,$p=0.0018<0.05$,显著)
- 劳动弹性:$\hat{\beta} = 0.3608$($t=1.7897$,$p=0.0843>0.05$,不显著)
- 模型整体:$R^2=0.8099$,$F=59.6550$($p=0.0000<0.05$,显著)。
(2)规模报酬判断
规模报酬不变的条件是 $\alpha + \beta = 1$,需通过约束性检验验证:
方法一:F检验
- 无约束模型:$\ln Y = \ln A + \alpha \ln K + \beta \ln L + u$,残差平方和 $RSS_U=5.0703$,解释变量数 $k_U=2$。
- 有约束模型:假设 $\alpha + \beta = 1$,转化为 $\ln(Y/L) = \ln A + (\alpha - 1)\ln(K/L) + u$,残差平方和 $RSS_R=5.0886$,解释变量数 $k_R=1$。
- F统计量:
$F = \frac{(RSS_R - RSS_U)/(k_U - k_R)}{RSS_U/(n - k_U - 1)} = \frac{(5.0886 - 5.0703)/1}{5.0703/(31 - 2 - 1)} = 0.1011$
临界值 $F_{0.05}(1,28)=4.20$,$F=0.1011<4.20$,不拒绝原假设。
方法二:Wald检验
直接检验 $H_0:\alpha + \beta=1$,Wald统计量 $\chi^2=0.1011$($p=0.7505>0.05$),不拒绝原假设。